
Featured Publications
All Publications
TRI Authors: Rares Ambrus, Vitor Guizilini, Jie Li, Sudeep Pillai, Adrien Gaidon
All Authors: Rares Ambrus, Vitor Guizilini, Jie Li, Sudeep Pillai, Adrien Gaidon
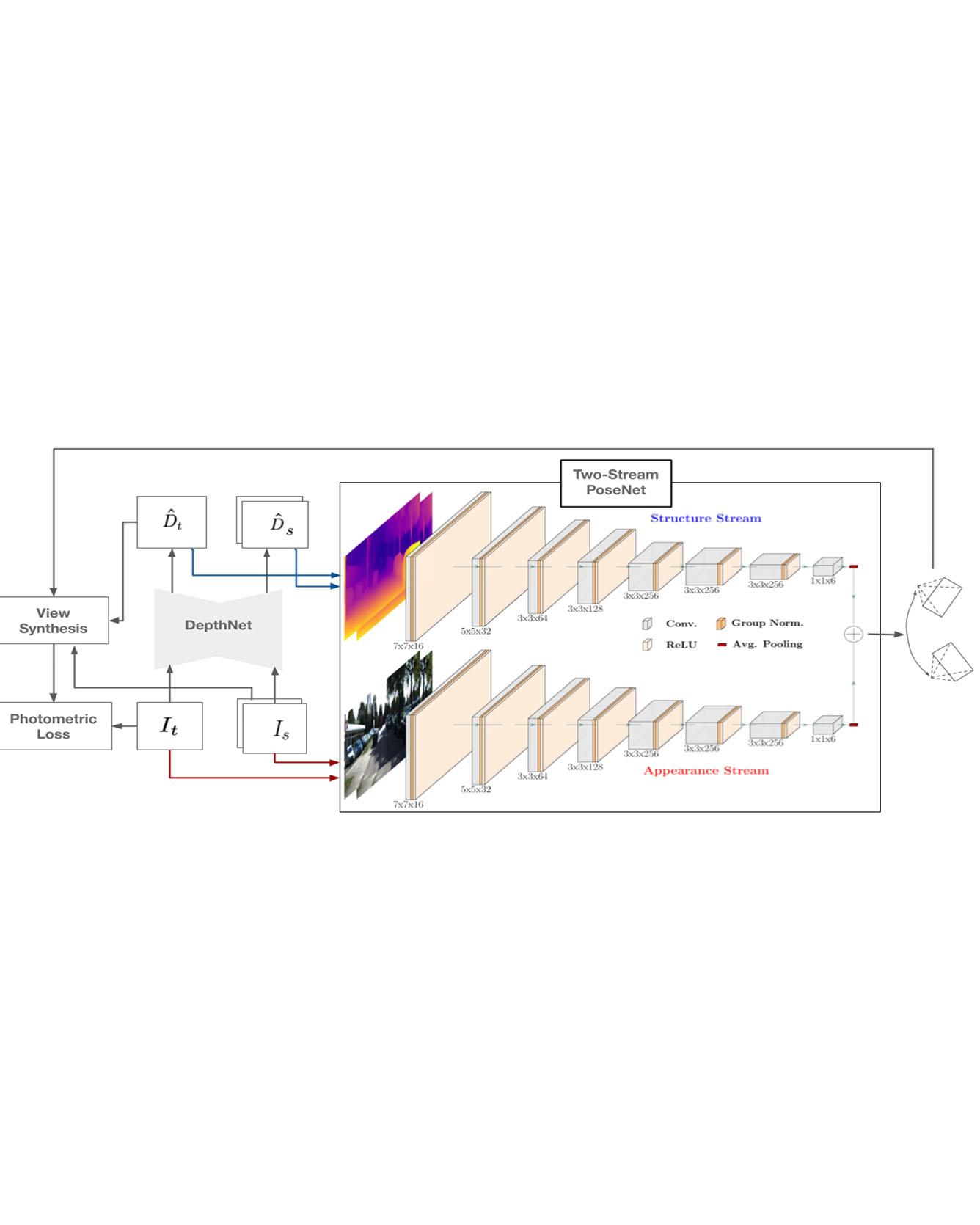
Learning depth and camera ego-motion from raw unlabeled RGB video streams is seeing exciting progress through self-supervision from strong geometric cues. To leverage not only appearance but also scene geometry, we propose a novel self-supervised two-stream network using RGB and inferred depth information for accurate visual odometry. In addition, we introduce a sparsity-inducing data augmentation policy for ego-motion learning that effectively regularizes the pose network to enable stronger generalization performance. As a result, we show that our proposed two-stream pose network achieves state-of-the-art results among learning-based methods on the KITTI odometry benchmark, and is especially suited for self-supervision at scale. Our experiments on a large-scale urban driving dataset of 1 million frames indicate that the performance of our proposed architecture does indeed scale progressively with more data. Read more
Citation: Ambrus, Rares, Vitor Guizilini, Jie Li, Sudeep Pillai, and Adrien Gaidon. "Two stream networks for self-supervised ego-motion estimation." In Conference on Robot Learning (CoRL) 2019.
TRI Authors: Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Jie Li and Adrien Gaidon
All Authors: Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Jie Li and Adrien Gaidon
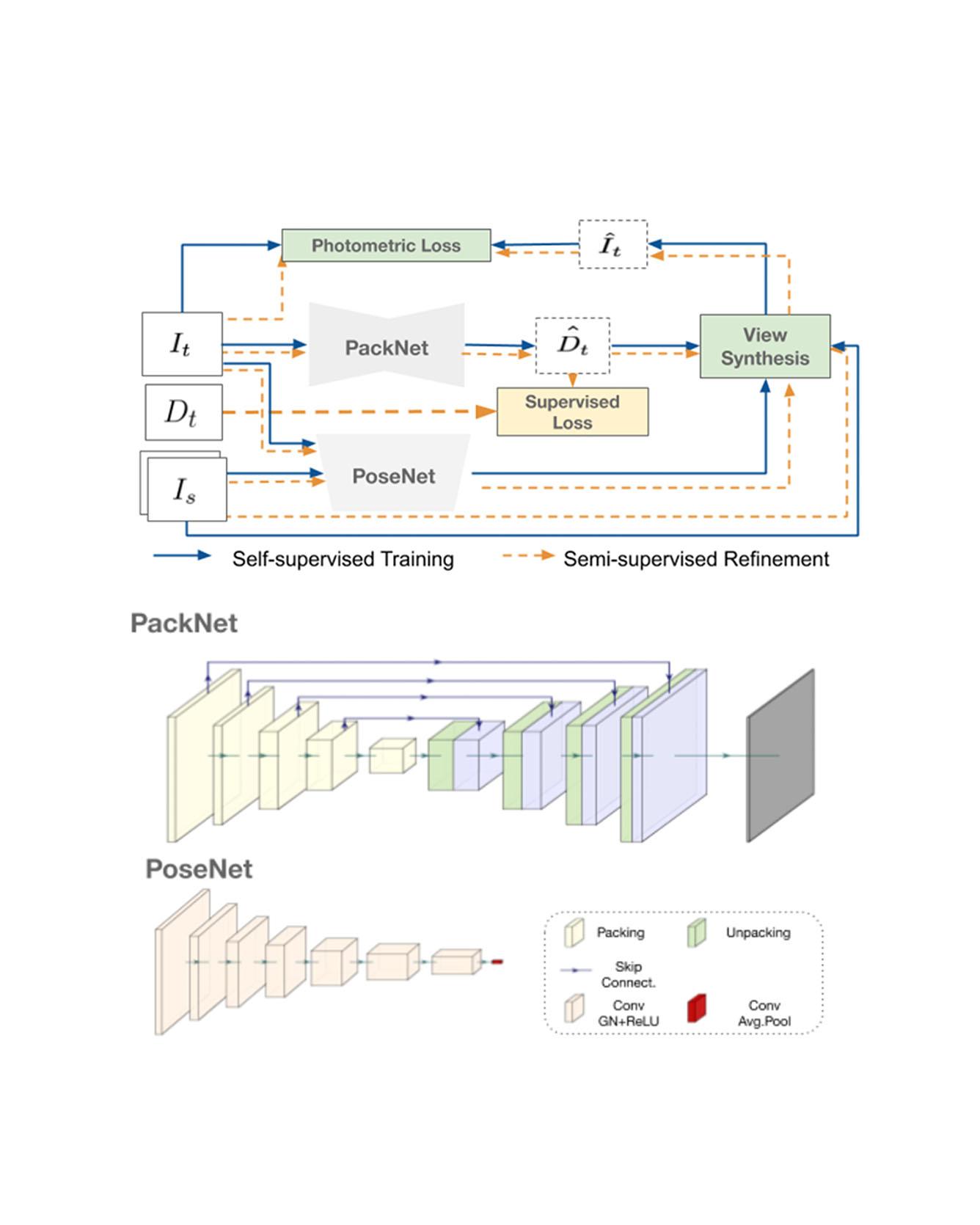
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art. Read More
Citation: Guizilini, Vitor, Jie Li, Rares Ambrus, Sudeep Pillai, and Adrien Gaidon. "Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances." In Conference on Robot Learning (CoRL) 2019.
TRI Authors: Max Bajracharya, James Borders, Dan Helmick, Thomas Kollar, Michael Laskey, John Leighty, Jeremy Ma, Umashankar Nagarajan, Akiyoshi Ochiai, Josh Peterson, Krishna Shankar, Kevin Stone, Yutaka Takaoka
All Authors: Max Bajracharya, James Borders, Dan Helmick, Thomas Kollar, Michael Laskey, John Leighty, Jeremy Ma, Umashankar Nagarajan, Akiyoshi Ochiai, Josh Peterson, Krishna Shankar, Kevin Stone, Yutaka Takaoka
We describe a mobile manipulation hardware and software system capable of autonomously performing complex human-level tasks in real homes, after being taught the task with a single demonstration from a person in virtual reality. This is enabled by a highly capable mobile manipulation robot, whole-body task space hybrid position/force control, teaching of parameterized primitives linked to a robust learned dense visual embeddings representation of the scene, and a task graph of the taught behaviors. We demonstrate the robustness of the approach by presenting results for performing a variety of tasks, under different environmental conditions, in multiple real homes. Our approach achieves 85% overall success rate on three tasks that consist of an average of 45 behaviors each. Read More
Citation: Bajracharya, Max, James Borders, Dan Helmick, Thomas Kollar, Michael Laskey, John Leichty, Jeremy Ma et al. "A Mobile Manipulation System for One-Shot Teaching of Complex Tasks in Homes." arXiv preprint arXiv:1910.00127 (2019).

TRI Author: Adrien Gaidon
All Authors: Felipe Codevilla and Eder Santana and Antonio M. López and Adrien Gaidon
Driving requires reacting to a wide variety of complex environment conditions and agent behaviors. Explicitly modeling each possible scenario is unrealistic. In contrast, imitation learning can, in theory, leverage data from large fleets of human-driven cars. Behavior cloning in particular has been successfully used to learn simple visuomotor policies end-to-end, but scaling to the full spectrum of driving behaviors remains an unsolved problem. In this paper, we propose a new benchmark to experimentally investigate the scalability and limitations of behavior cloning. We show that behavior cloning leads to state-of-the-art results, executing complex lateral and longitudinal maneuvers, even in unseen environments, without being explicitly programmed to do so. However, we confirm some limitations of the behavior cloning approach: some well-known limitations (e.g., dataset bias and overfitting), new generalization issues (e.g., dynamic objects and the lack of a causal modeling), and training instabilities, all requiring further research before behavior cloning can graduate to real-world driving. The code, dataset, benchmark, and agent studied in this paper can be found at github.com/felipecode/coiltraine/blob/master/docs/exploring_limitations.md Read more
Citation: Codevilla, Felipe, Eder Santana, Antonio M. López, and Adrien Gaidon. "Exploring the limitations of behavior cloning for autonomous driving." In Proceedings of the IEEE International Conference on Computer Vision, pp. 9329-9338. 2019.

TRI Author: Adrien Gaidon
All Authors: Cesar Roberto de Souza, Adrien Gaidon, Yohann Cabon, Naila Murray, Antonio Manuel Lopez
Deep video action recognition models have been highly successful in recent years but require large quantities of manually-annotated data, which are expensive and laborious to obtain. In this work, we investigate the generation of synthetic training data for video action recognition, as synthetic data have been successfully used to supervise models for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation, physics models and other components of modern game engines. With this model we generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for “Procedural Human Action Videos”. PHAV contains a total of 39,982 videos, with more than 1000 examples for each of 35 action categories. Our video generation approach is not limited to existing motion capture sequences: 14 of these 35 categories are procedurally-defined synthetic actions. In addition, each video is represented with 6 different data modalities, including RGB, optical flow and pixel-level semantic labels. These modalities are generated almost simultaneously using the Multiple Render Targets feature of modern GPUs. In order to leverage PHAV, we introduce a deep multi-task (i.e. that considers action classes from multiple datasets) representation learning architecture that is able to simultaneously learn from synthetic and real video datasets, even when their action categories differ. Our experiments on the UCF-101 and HMDB-51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance. Our approach also significantly outperforms video representations produced by fine-tuning state-of-the-art unsupervised generative models of videos. Read More
Citation: de Souza, César Roberto, Adrien Gaidon, Yohann Cabon, Naila Murray, and Antonio Manuel López. "Generating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models." International Journal of Computer Vision (2019): 1-32.

TRI Authors: Wadim Kehl, Adrien Gaidon
All Authors: Fabian Manhardt, Wadim Kehl, Adrien Gaidon
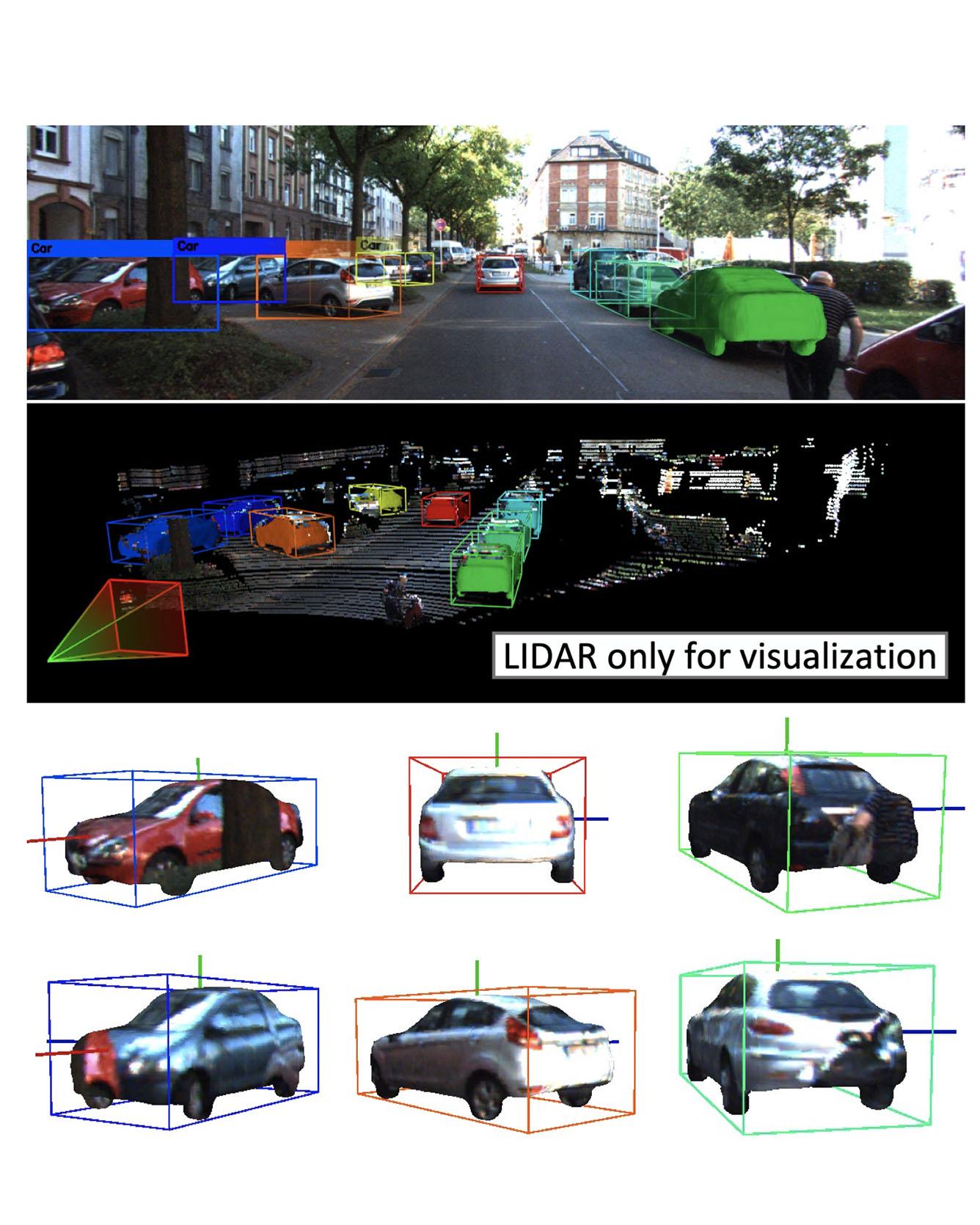
We present a deep learning method for end-to-end monocular 3D object detection and metric shape retrieval. We propose a novel loss formulation by lifting 2D detection, orientation, and scale estimation into 3D space. Instead of optimizing these quantities separately, the 3D instantiation allows to properly measure the metric misalignment of boxes. We experimentally show that our 10D lifting of sparse 2D Regions of Interests (RoIs) achieves great results both for 6D pose and recovery of the textured metric geometry of instances. This further enables 3D synthetic data augmentation via inpainting recovered meshes directly onto the 2D scenes. We evaluate on KITTI3D against other strong monocular methods and demonstrate that our approach doubles the AP on the 3D pose metrics on the official test set, defining the new state of the art. Read More
Citation: Manhardt, Fabian, Wadim Kehl, and Adrien Gaidon. "Roi-10d: Monocular lifting of 2d detection to 6d pose and metric shape." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2069-2078. 2019.
TRI Authors: Kuan-Hui Lee, Takaaki Tagawa, Jia-En M. Pan, Adrien Gaidon, Bertrand Douillard
All Authors: Kuan-Hui Lee, Takaaki Tagawa, Jia-En M. Pan, Adrien Gaidon, Bertrand Douillard
Vehicle taillight recognition is an important application for automated driving, especially for intent prediction of ado vehicles and trajectory planning of the ego vehicle. In this work, we propose an end-to-end deep learning framework to recognize taillights, i.e. rear turn and brake signals, from a sequence of images. The proposed method starts with a Convolutional Neural Network (CNN) to extract spatial features, and then applies a Long Short-Term Memory network (LSTM) to learn temporal dependencies. Furthermore, we integrate attention models in both spatial and temporal domains, where the attention models learn to selectively focus on both spatial and temporal features. Our method is able to outperform the state of the art in terms of accuracy on the UC Merced Vehicle Rear Signal Dataset, demonstrating the effectiveness of attention models for vehicle taillight recognition. Read More
Citation: Lee, Kuan-Hui, Takaaki Tagawa, Jia-En M. Pan, Adrien Gaidon, and Bertrand Douillard. "An Attention-based Recurrent Convolutional Network for Vehicle Taillight Recognition." In 2019 IEEE Intelligent Vehicles Symposium (IV), pp. 2365-2370. IEEE, 2019.

TRI Authors: Hongkai Dai, Russ Tedrake
All Authors: Hongkai Dai, Gregory Izatt, Russ Tedrake
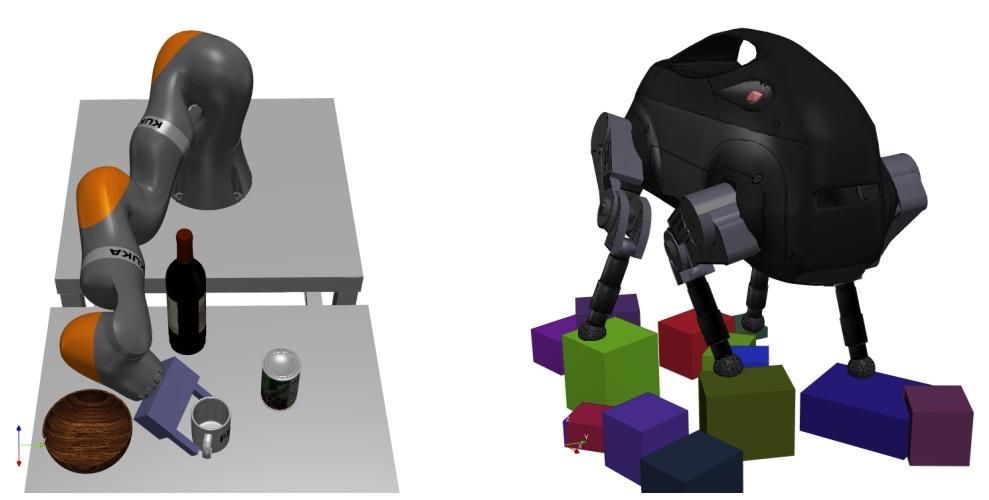
In this paper, we present a novel formulation of the inverse kinematics (IK) problem with generic constraints as a mixed-integer convex optimization program. The proposed approach can solve the IK problem globally with generic task space constraints: a major improvement over existing approaches, which either solve the problem in only a local neighborhood of the user initial guess through nonlinear non-convex optimization, or address only a limited set of kinematics constraints. Specifically, we propose a mixed-integer convex relaxation of non-convex SO(3) rotation constraints, and apply this relaxation on the IK problem. Our formulation can detect if an instance of the IK problem is globally infeasible, or produce an approximate solution when it is feasible. We show results on a seven-joint arm grasping objects in a cluttered environment, an 18-degree-of-freedom quadruped standing on stepping stones, and a parallel Stewart platform. Moreover, we show that our approach can find a collision free path for a gripper in a cluttered environment, or certify such a path does not exist. We also compare our approach against the analytical approach for a six-joint manipulator. The open-source code is available at http://drake.mit.edu. Read More
Citation: Dai, Hongkai, Gregory Izatt, and Russ Tedrake. "Global inverse kinematics via mixed-integer convex optimization." The International Journal of Robotics Research 38, no. 12-13 (2019): 1420-1441.
TRI Authors: Alex Alspach, Kunimatsu Hashimoto, Naveen Kuppuswarny and Russ Tedrake
All Authors: A. Alspach, K. Hashimoto, N. Kuppuswarny and R. Tedrake
Incorporating effective tactile sensing and mechanical compliance is key towards enabling robust and safe operation of robots in unknown, uncertain and cluttered environments. Towards realizing this goal, we present a lightweight, easy-to-build, highly compliant dense geometry sensor and end effector that comprises an inflated latex membrane with a depth sensor behind it. We present the motivations and the hardware design for this Soft-bubble and demonstrate its capabilities through example tasks including tactile-object classification, pose estimation and tracking, and nonprehensile object manipulation. We also present initial experiments to show the importance of high-resolution geometry sensing for tactile tasks and discuss applications in robust manipulation. Read More
Citation: Alspach, Alex, Kunimatsu Hashimoto, Naveen Kuppuswarny, and Russ Tedrake. "Soft-bubble: A highly compliant dense geometry tactile sensor for robot manipulation." In 2019 2nd IEEE International Conference on Soft Robotics (RoboSoft), pp. 597-604. IEEE, 2019.

TRI Authors: Astrid Jackson, Brandon D. Northcutt
All Authors: Astrid Jackson, Brandon D. Northcutt, Gita Sukthankar
One of the advantages of teaching robots by demonstration is that it can be more intuitive for users to demonstrate rather than describe the desired robot behavior. However, when the human demonstrates the task through an interface, the training data may inadvertently acquire artifacts unique to the interface, not the desired execution of the task. Being able to use one's own body usually leads to more natural demonstrations, but those examples can be more difficult to translate to robot control policies. This paper quantifies the benefits of using a virtual reality system that allows human demonstrators to use their own body to perform complex manipulation tasks. We show that our system generates superior demonstrations for a deep neural network without introducing a correspondence problem. The effectiveness of this approach is validated by comparing the learned policy to that of a policy learned from data collected via a conventional gaming system, where the user views the environment on a monitor screen, using a Sony Play Station 3 (PS3) DualShock 3 wireless controller as input. Read more
Citation: Jackson, Astrid, Brandon D. Northcutt, and Gita Sukthankar. "The benefits of immersive demonstrations for teaching robots." In 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 326-334. IEEE, 2019.