
Featured Publications
All Publications
TRI Authors: Jie Li, Allan Raventos, Arjun Bhargava, Takaaki Tagawa, Adrien Gaidon
All Authors: Jie Li, Allan Raventos, Arjun Bhargava, Takaaki Tagawa, Adrien Gaidon
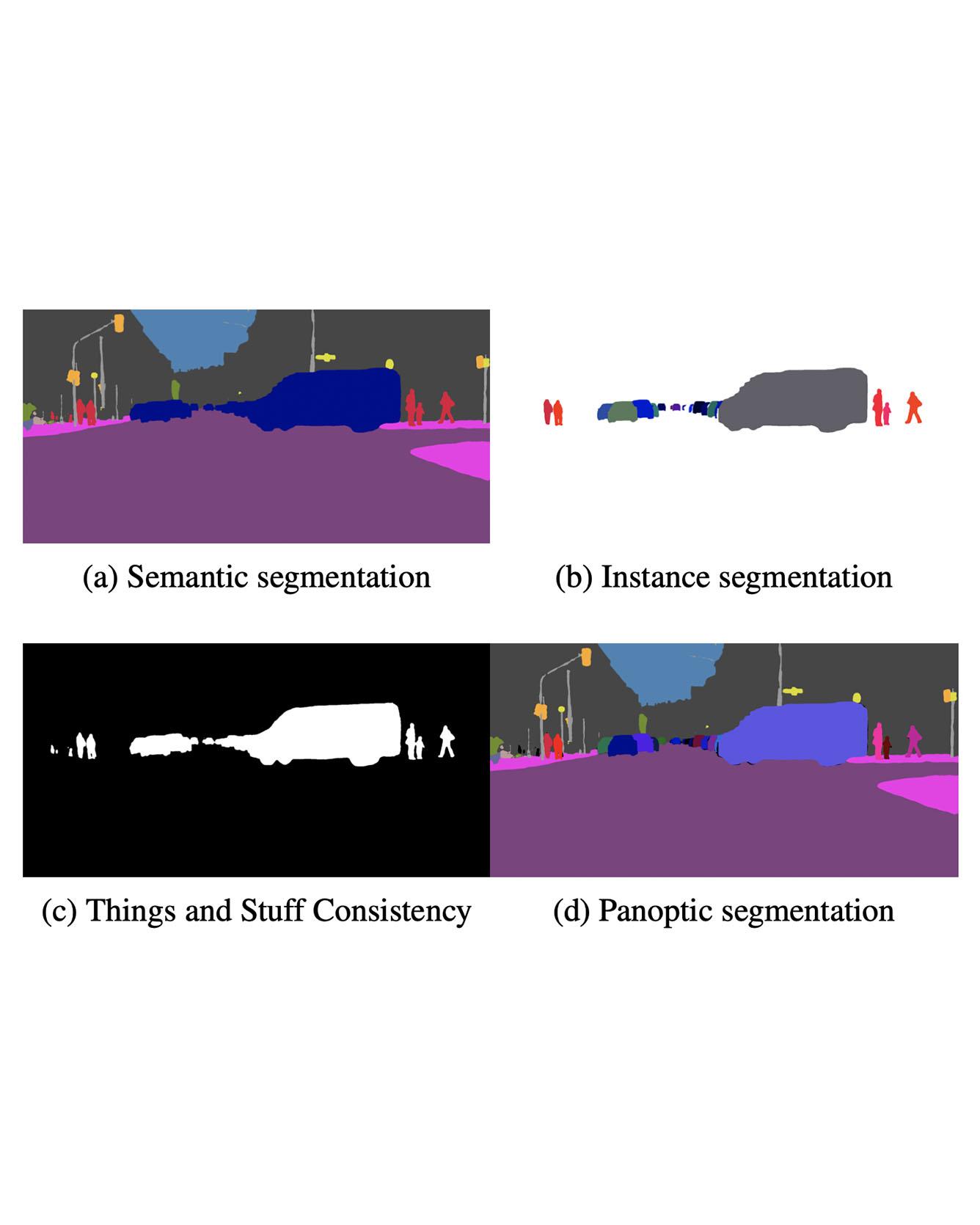
We propose an end-to-end learning approach for panoptic segmentation, a novel task unifying instance (things) and semantic (stuff) segmentation. Our model, TASCNet, uses feature maps from a shared backbone network to predict in a single feed-forward pass both things and stuff segmentations. We explicitly constrain these two output distributions through a global things and stuff binary mask to enforce cross-task consistency. Our proposed unified network is competitive with the state of the art on several benchmarks for panoptic segmentation as well as on the individual semantic and instance segmentation tasks. Read more
Citation: Li, Jie, Allan Raventos, Arjun Bhargava, Takaaki Tagawa, and Adrien Gaidon. "Learning to fuse things and stuff." arXiv preprint arXiv:1812.01192 (2018).
TRI Authors: Kuan-Hui Lee, Jie Li, Adrien Gaidon
All Authors: Kuan-Hui Lee, German Ros, Jie Li, Adrien Gaidon
Deep Learning for Computer Vision depends mainly on the source of supervision.Photo-realistic simulators can generate large-scale automatically labeled syntheticdata, but introduce a domain gap negatively impacting performance. We propose anew unsupervised domain adaptation algorithm, called SPIGAN, relying on Sim-ulator Privileged Information (PI) and Generative Adversarial Networks (GAN).We use internal data from the simulator as PI during the training of a target tasknetwork. We experimentally evaluate our approach on semantic segmentation. Wetrain the networks on real-world Cityscapes and Vistas datasets, using only unla-beled real-world images and synthetic labeled data with z-buffer (depth) PI fromthe SYNTHIA dataset. Our method improves over no adaptation and state-of-the-art unsupervised domain adaptation techniques. Read More
Citation: Lee, Kuan-Hui, German Ros, Jie Li, and Adrien Gaidon. "SPIGAN: Privileged adversarial learning from simulation." In International Conference on Learning Representations, 2019.

TRI Authors: Sudeep Pillai, Rares Ambrus, Adrien Gaidon
All Authors: Sudeep Pillai, Rares Ambrus, Adrien Gaidon
Recent techniques in self-supervised monocular depth estimation are approaching the performance of supervised methods, but operate in low resolution only. We show that high resolution is key towards high-fidelity self-supervised monocular depth prediction. Inspired by recent deep learning methods for Single-Image Super-Resolution, we propose a sub-pixel convolutional layer extension for depth super-resolution that accurately synthesizes high-resolution disparities from their corresponding low-resolution convolutional features. In addition, we introduce a differentiable flip-augmentation layer that accurately fuses predictions from the image and its horizontally flipped version, reducing the effect of left and right shadow regions generated in the disparity map due to occlusions. Both contributions provide significant performance gains over the state-of-the-art in self-supervised depth and pose estimation on the public KITTI benchmark. A video of our approach can be found at this https URL. Read More
Citation: Pillai, Sudeep, Rareş Ambruş, and Adrien Gaidon. "Superdepth: Self-supervised, super-resolved monocular depth estimation." In 2019 International Conference on Robotics and Automation (ICRA), pp. 9250-9256. IEEE, 2019.

TRI Author: Hongkai Dai
All Authors: Romeo Orsolino, Michele Focchi, Carlos Mastalli, Hongkai Dai, Darwin G. Caldwell and Claudio Semini
Motion planning in multicontact scenarios has recently gathered interest within the legged robotics community, however actuator force/torque limits are rarely considered. We believe that these limits gain paramount importance when the complexity of the terrains to be traversed increases. We build on previous research from the field of robotic grasping to propose two new six-dimensional bounded polytopes named the Actuation Wrench Polytope (AWP) and the Feasible Wrench Polytope (FWP). We define theAWP as the set of all the wrenches that a robot can generate while considering its actuation limits. This considers the admissible contact forces that the robot can generate given its current configuration and actuation capabilities. The Contact Wrench Cone (CWC) instead includes features of the environment such as the contact normal or the friction coefficient. The intersection of the AWP and of the CWC results in a convex polytope, the FWP, which turns out to be more descriptive of the real robot capabilities than existing simplified models, while maintaining the same compact representation. We explain how to efficiently compute the vertex-description of the FWP that is then used to evaluate a feasibility factor that we adapted from the field of robotic grasping. This allows us to optimize for robustness to external disturbance wrenches. Based on this, we present an implementation of a motion planner for our quadruped robot HyQ that provides online Center of Mass trajectories that are guaranteed to be statically stable and actuation-consistent. Read More
Citation: Orsolino, Romeo, Michele Focchi, Carlos Mastalli, Hongkai Dai, Darwin G. Caldwell, and Claudio Semini. "Application of wrench-based feasibility analysis to the online trajectory optimization of legged robots." IEEE Robotics and Automation Letters 3, no. 4 (2018): 3363-3370.
TRI Author: Adrien Gaidon
All Authors: Adrien Gaidon, Antonio Lopez, Florent Perronnin
The recent successes in many visual recognition tasks, such as image classification, object detection, and semantic segmentation can be attributed in large part to three factors: (i) advances in end-to-end trainable deep learning models (LeCun 2015), (ii) the progress of computing hardware, and (iii) the introduction of increasingly larger labeled datasets such as PASCAL VOC (Everingham et al. 2010), KITTI (Geiger et al. 2012), ImageNet (Russakovsky et al. 2015), MS-COCO (Lin et al. 2014), and Cityscapes (Cordts et al. 2016), among others. In fact, recent results (Sun et al. 2017; Hestness et al. 2017) indicate that the reliability of current visual models might not be limited by the algorithms themselves but by the type and amount of supervised data available. Therefore, to tackle more challenging tasks, such as video scene understanding, progress is needed not only on the algorithmic and hardware fronts but also on the data front, both for learning and quantitative evaluation. However, acquiring and densely labeling a large visual dataset with ground truth information (e.g. semantic labels, depth, optical flow) for each new problem is not a scalable alternative. Read More
Citation: Gaidon, Adrien, Antonio Lopez, and Florent Perronnin. "The reasonable effectiveness of synthetic visual data." International Journal of Computer Vision 126, no. 9 (2018): 899-901.

TRI Author: Katherine M. Tsui
All Authors: Suresh Kumaar Jayaraman, Chandler Creech, Lionel P. Robert Jr., Dawn M. Tilbury, X Jessie Yang, Anuj K. Pradhan, Katherine M. Tsui
Autonomous vehicles (AVs) have the potential to improve road safety. Trust in AVs, especially among pedestrians, is vital to alleviate public skepticism. Yet much of the research has focused on trust between the AV and its driver/passengers. To address this shortcoming, we examined the interactions between AVs and pedestrians using uncertainty reduction theory (URT). We empirically verified this model with a user study in an immersive virtual reality environment (IVE). The study manipulated two factors: AV driving behavior (defensive, normal and aggressive) and the traffic situation (signalized and unsignalized). Results suggest that the impact of aggressive driving on trust in AVs depends on the type of crosswalk. At signalized crosswalks the AV»s driving behavior had little impact on trust, but at unsignalized crosswalks the AV»s driving behavior was a major determinant of trust. Our findings shed new insights on trust between AVs and pedestrians. Read more
Citation: Jayaraman, Suresh Kumaar, Chandler Creech, Lionel P. Robert Jr, Dawn M. Tilbury, X. Jessie Yang, Anuj K. Pradhan, and Katherine M. Tsui. "Trust in AV: An uncertainty reduction model of AV-pedestrian interactions." In Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, pp. 133-134. 2018.
TRI Authors: Astrid Jackson, Brandon D. Northcutt
All Authors: Astrid Jackson, Brandon D. Northcutt, Gita Sukthankar
One of the advantages of teaching robots by demonstration is that it can be more intuitive for users to demonstrate rather than describe the desired robot behavior. However, when the human demonstrates the task through an interface, the training data may inadvertently acquire artifacts unique to the interface, not the desired execution of the task. Being able to use one»s own body usually leads to more natural demonstrations, but those examples can be more difficult to translate to robot control policies. This paper quantifies the benefits of using a virtual reality system that allows human demonstrators to use their own body to perform complex manipulation tasks. We show that our system generates superior demonstrations for a deep neural network without introducing a correspondence problem. The effectiveness of this approach is validated by comparing the learned policy to that of a policy learned from data collected via a Sony Play Station~3 (PS3) DualShock 3 wireless controller. Read more
Citation: Jackson, Astrid, Brandon D. Northcutt, and Gita Sukthankar. "The Benefits of Teaching Robots using VR Demonstrations." In Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, pp. 129-130. 2018.
TRI Authors: Kuan-Hui Lee, Adrien Gaidon
All Authors: Karttikeya Mangalam, Ehsan Adeli, Kuan-Hui Lee, Adrien Gaidon, and Juan Carlos Niebles We tackle the problem of Human Locomotion Forecasting, a task for jointly predicting the spatial positions of several keypoints on human body in the near future under an egocentric setting. In contrast to the previous work that aims to solve either the task of pose prediction or trajectory forecasting in isolation, we propose a framework to unify these two problems and address the practically useful task of pedestrian locomotion prediction in the wild. Among the major challenges in solving this task is the scarcity of annotated egocentric video datasets with dense annotations for pose, depth, or egomotion. To surmount this difficulty, we use state-of-the-art models to generate (noisy) annotations and propose robust forecasting models that can learn from this noisy supervision. We present a method to disentangle the overall pedestrian motion into easier to learn subparts by utilizing a pose completion and a decomposition module. The completion module fills in the missing key-point annotations and the decomposition module breaks the cleaned locomotion down to global (trajectory) and local (pose keypoint movements). Further, with Quasi RNN as our backbone, we propose a novel hierarchical trajectory forecasting network that utilizes low-level vision domain specific signals like egomotion and depth to predict the global trajectory. Our method leads to state-of-the-art results for the prediction of human locomotion in the egocentric view. Read more
Citations: Mangalam, Karttikeya, Ehsan Adeli, Kuan-Hui Lee, Adrien Gaidon, and Juan Carlos Niebles. "Disentangling human dynamics for pedestrian locomotion forecasting with noisy supervision." In The IEEE Winter Conference on Applications of Computer Vision, pp. 2784-2793. 2020.
