Featured Publications
All Publications
TRI Authors: Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Jie Li and Adrien Gaidon
All Authors: Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Jie Li and Adrien Gaidon
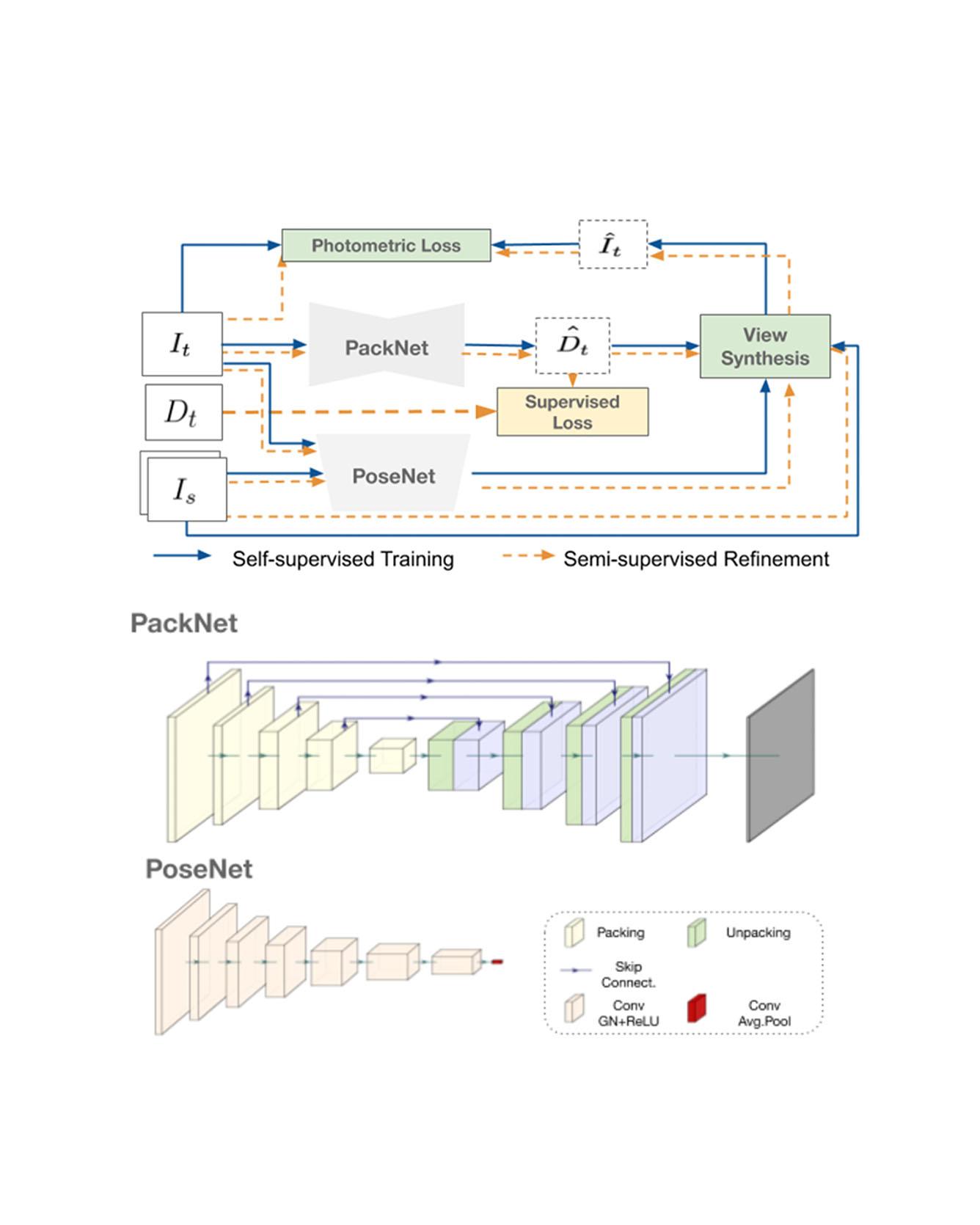
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art. Read More
Citation: Guizilini, Vitor, Jie Li, Rares Ambrus, Sudeep Pillai, and Adrien Gaidon. "Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances." In Conference on Robot Learning (CoRL) 2019.
TRI Authors: Simon Stent
All Authors: Petr Kellnhofer, Adrià Recasens, Simon Stent, Wojciech Matusik and Antonio Torralba
Understanding where people are looking is an informative social cue. In this work, we present Gaze360, a large-scale remote gaze-tracking dataset and method for robust 3D gaze estimation in unconstrained images. Our dataset consists of 238 subjects in indoor and outdoor environments with labelled 3D gaze across a wide range of head poses and distances. It is the largest publicly available dataset of its kind by both subject and variety, made possible by a simple and efficient collection method. Our proposed 3D gaze model extends existing models to include temporal information and to directly output an estimate of gaze uncertainty. We demonstrate the benefits of our model via an ablation study, and show its generalization performance via a cross-dataset evaluation against other recent gaze benchmark datasets. We furthermore propose a simple self-supervised approach to improve cross-dataset domain adaptation. Finally, we demonstrate an application of our model for estimating customer attention in a supermarket setting. Our dataset and models will be made available at http://gaze360.csail.mit.edu. Read More
Citation: Kellnhofer, Petr, Adria Recasens, Simon Stent, Wojciech Matusik, and Antonio Torralba. "Gaze360: Physically unconstrained gaze estimation in the wild." In Proceedings of the IEEE International Conference on Computer Vision, pp. 6912-6921. 2019.

TRI Authors: Max Bajracharya, James Borders, Dan Helmick, Thomas Kollar, Michael Laskey, John Leighty, Jeremy Ma, Umashankar Nagarajan, Akiyoshi Ochiai, Josh Peterson, Krishna Shankar, Kevin Stone, Yutaka Takaoka
All Authors: Max Bajracharya, James Borders, Dan Helmick, Thomas Kollar, Michael Laskey, John Leighty, Jeremy Ma, Umashankar Nagarajan, Akiyoshi Ochiai, Josh Peterson, Krishna Shankar, Kevin Stone, Yutaka Takaoka
We describe a mobile manipulation hardware and software system capable of autonomously performing complex human-level tasks in real homes, after being taught the task with a single demonstration from a person in virtual reality. This is enabled by a highly capable mobile manipulation robot, whole-body task space hybrid position/force control, teaching of parameterized primitives linked to a robust learned dense visual embeddings representation of the scene, and a task graph of the taught behaviors. We demonstrate the robustness of the approach by presenting results for performing a variety of tasks, under different environmental conditions, in multiple real homes. Our approach achieves 85% overall success rate on three tasks that consist of an average of 45 behaviors each. Read More
Citation: Bajracharya, Max, James Borders, Dan Helmick, Thomas Kollar, Michael Laskey, John Leichty, Jeremy Ma et al. "A Mobile Manipulation System for One-Shot Teaching of Complex Tasks in Homes." arXiv preprint arXiv:1910.00127 (2019).

TRI Author: Joseph Montoya
All Authors: Anjli Patel, Jens Nørskov, Kristin Persson, Joseph Montoya
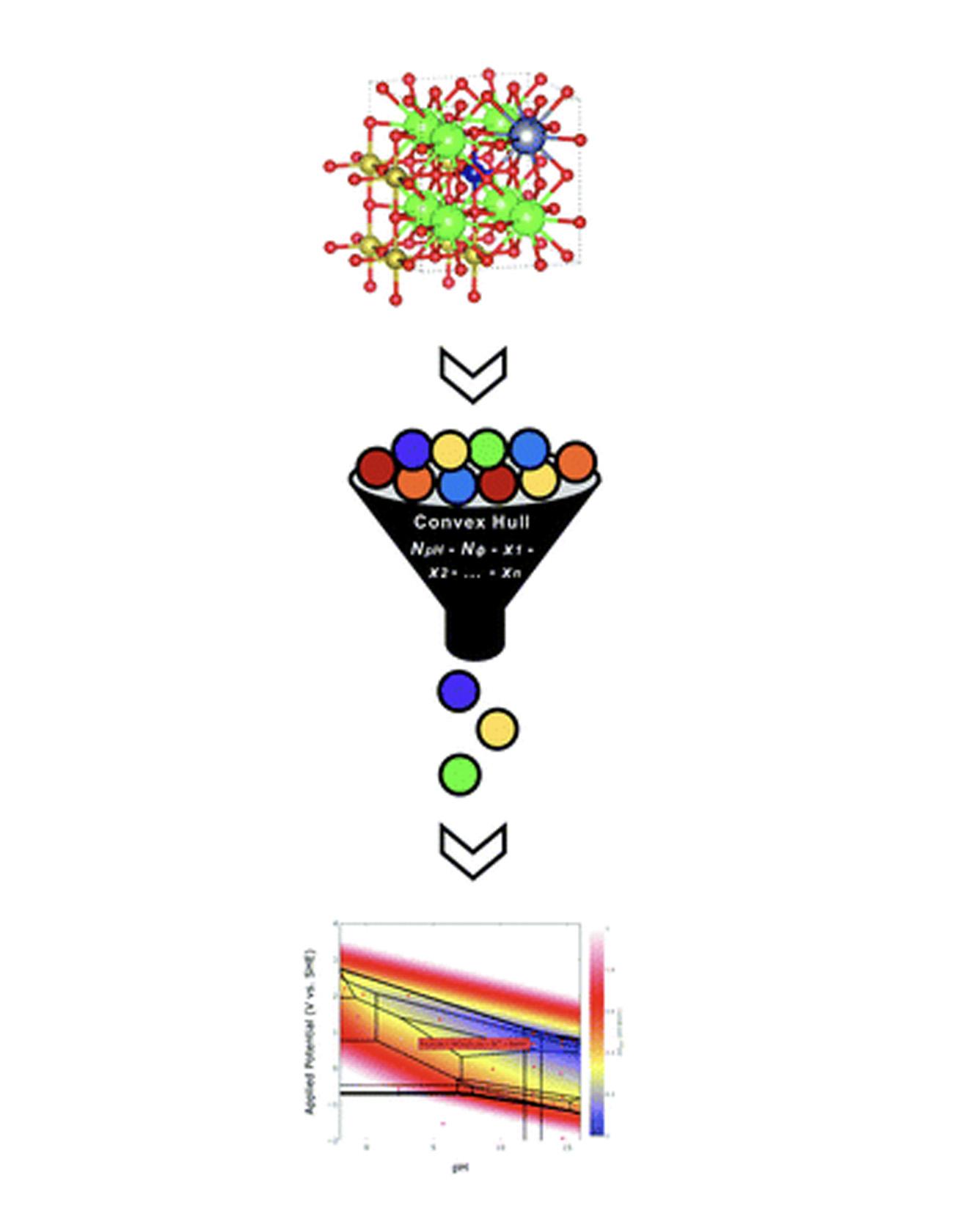
Pourbaix diagrams have been used extensively to evaluate stability regions of materials subject to varying potential and pH conditions in aqueous environments. However, both recent advances in high-throughput material exploration and increasing complexity of materials of interest for electrochemical applications pose challenges for performing Pourbaix analysis on multidimensional systems. Specifically, current Pourbaix construction algorithms incur significant computational costs for systems consisting of four or more elemental components. Herein, we propose an alternative Pourbaix construction method that filters all potential combinations of species in a system to only those present on a compositional convex hull. By including axes representing the quantities of H+ and e− required to form a given phase, one can ensure every stable phase mixture is included in the Pourbaix diagram and reduce the computational time required to construct the resultant Pourbaix diagram by several orders of magnitude. This new Pourbaix algorithm has been incorporated into the pymatgen code and the Materials Project website, and it extends the ability to evaluate the Pourbaix stability of complex multicomponent systems. Read More
Citation: Patel, Anjli M., Jens K. Nørskov, Kristin A. Persson, and Joseph H. Montoya. "Efficient Pourbaix diagrams of many-element compounds." Physical Chemistry Chemical Physics 21, no. 45 (2019): 25323-25327.
TRI Author: Adrien Gaidon
All Authors: Felipe Codevilla and Eder Santana and Antonio M. López and Adrien Gaidon
Driving requires reacting to a wide variety of complex environment conditions and agent behaviors. Explicitly modeling each possible scenario is unrealistic. In contrast, imitation learning can, in theory, leverage data from large fleets of human-driven cars. Behavior cloning in particular has been successfully used to learn simple visuomotor policies end-to-end, but scaling to the full spectrum of driving behaviors remains an unsolved problem. In this paper, we propose a new benchmark to experimentally investigate the scalability and limitations of behavior cloning. We show that behavior cloning leads to state-of-the-art results, executing complex lateral and longitudinal maneuvers, even in unseen environments, without being explicitly programmed to do so. However, we confirm some limitations of the behavior cloning approach: some well-known limitations (e.g., dataset bias and overfitting), new generalization issues (e.g., dynamic objects and the lack of a causal modeling), and training instabilities, all requiring further research before behavior cloning can graduate to real-world driving. The code, dataset, benchmark, and agent studied in this paper can be found at github.com/felipecode/coiltraine/blob/master/docs/exploring_limitations.md Read more
Citation: Codevilla, Felipe, Eder Santana, Antonio M. López, and Adrien Gaidon. "Exploring the limitations of behavior cloning for autonomous driving." In Proceedings of the IEEE International Conference on Computer Vision, pp. 9329-9338. 2019.

TRI Author: Wadim Kehl
All Authors: Sergey Zakharov, Wadim Kehl, Slobodan Ilic
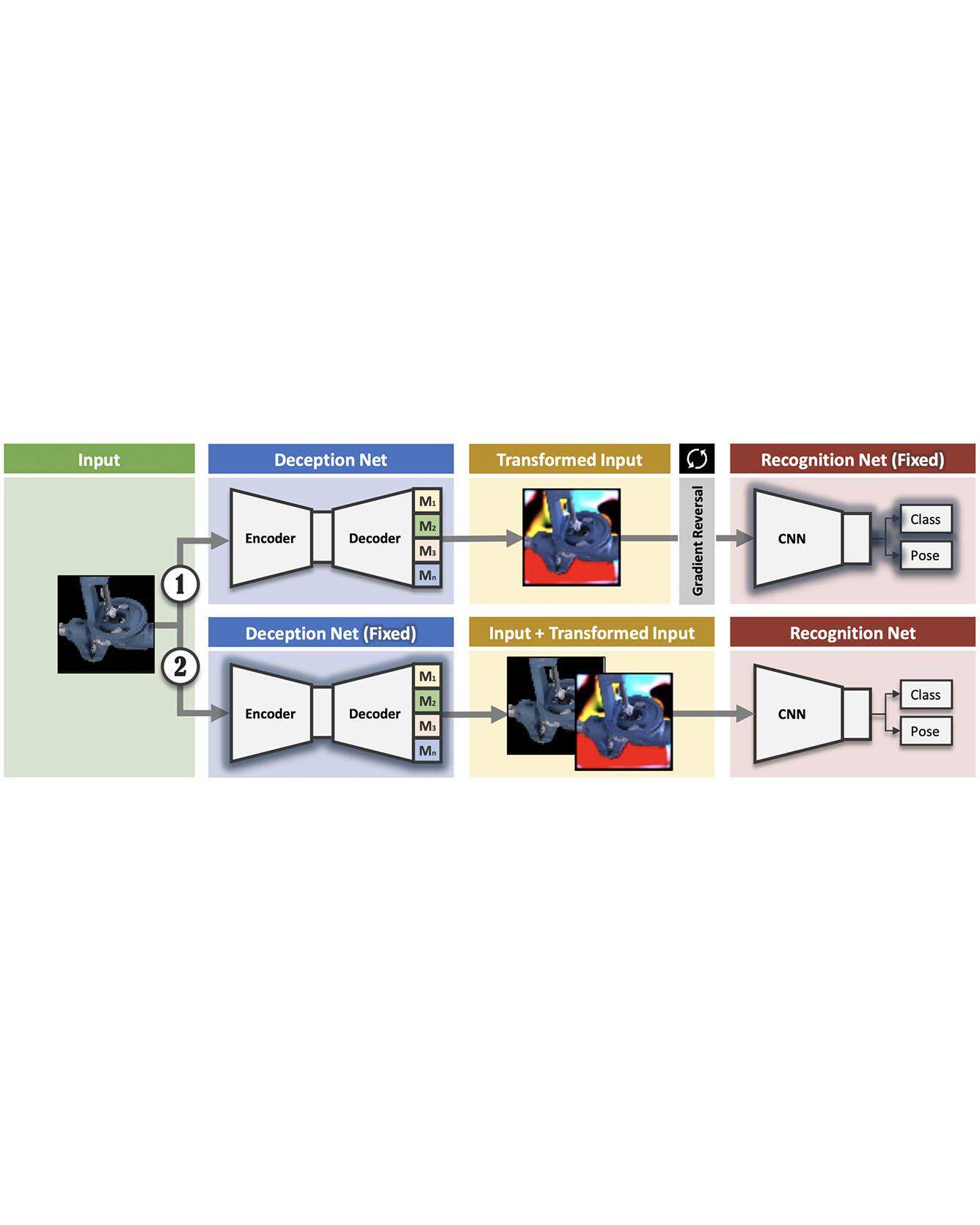
We present a novel approach to tackle domain adaptation between synthetic and real data. Instead, of employing "blind" domain randomization, i.e., augmenting synthetic renderings with random backgrounds or changing illumination and colorization, we leverage the task network as its own adversarial guide toward useful augmentations that maximize the uncertainty of the output. To this end, we design a min-max optimization scheme where a given task competes against a special deception network to minimize the task error subject to the specific constraints enforced by the deceiver. The deception network samples from a family of differentiable pixel-level perturbations and exploits the task architecture to find the most destructive augmentations. Unlike GAN-based approaches that require unlabeled data from the target domain, our method achieves robust mappings that scale well to multiple target distributions from source data alone. We apply our framework to the tasks of digit recognition on enhanced MNIST variants, classification and object pose estimation on the Cropped LineMOD dataset as well as semantic segmentation on the Cityscapes dataset and compare it to a number of domain adaptation approaches, thereby demonstrating similar results with superior generalization capabilities. Read More
Citation: Zakharov, Sergey, Wadim Kehl, and Slobodan Ilic. "Deceptionnet: Network-driven domain randomization." In Proceedings of the IEEE International Conference on Computer Vision, pp. 532-541. 2019.
SHARE
TRI Author: Adrien Gaidon
All Authors: Cesar Roberto de Souza, Adrien Gaidon, Yohann Cabon, Naila Murray, Antonio Manuel Lopez
Deep video action recognition models have been highly successful in recent years but require large quantities of manually-annotated data, which are expensive and laborious to obtain. In this work, we investigate the generation of synthetic training data for video action recognition, as synthetic data have been successfully used to supervise models for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation, physics models and other components of modern game engines. With this model we generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for “Procedural Human Action Videos”. PHAV contains a total of 39,982 videos, with more than 1000 examples for each of 35 action categories. Our video generation approach is not limited to existing motion capture sequences: 14 of these 35 categories are procedurally-defined synthetic actions. In addition, each video is represented with 6 different data modalities, including RGB, optical flow and pixel-level semantic labels. These modalities are generated almost simultaneously using the Multiple Render Targets feature of modern GPUs. In order to leverage PHAV, we introduce a deep multi-task (i.e. that considers action classes from multiple datasets) representation learning architecture that is able to simultaneously learn from synthetic and real video datasets, even when their action categories differ. Our experiments on the UCF-101 and HMDB-51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance. Our approach also significantly outperforms video representations produced by fine-tuning state-of-the-art unsupervised generative models of videos. Read More
Citation: de Souza, César Roberto, Adrien Gaidon, Yohann Cabon, Naila Murray, and Antonio Manuel López. "Generating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models." International Journal of Computer Vision (2019): 1-32.

TRI Authors: Nikos Arechiga, Soonho Kong
All Authors: Sicun Gao, James Kapinski, Jyotirmoy Deshmukh, Nima Roohi, Armando Solar-Lezama, Nikos Arechiga, and Soonho Kong
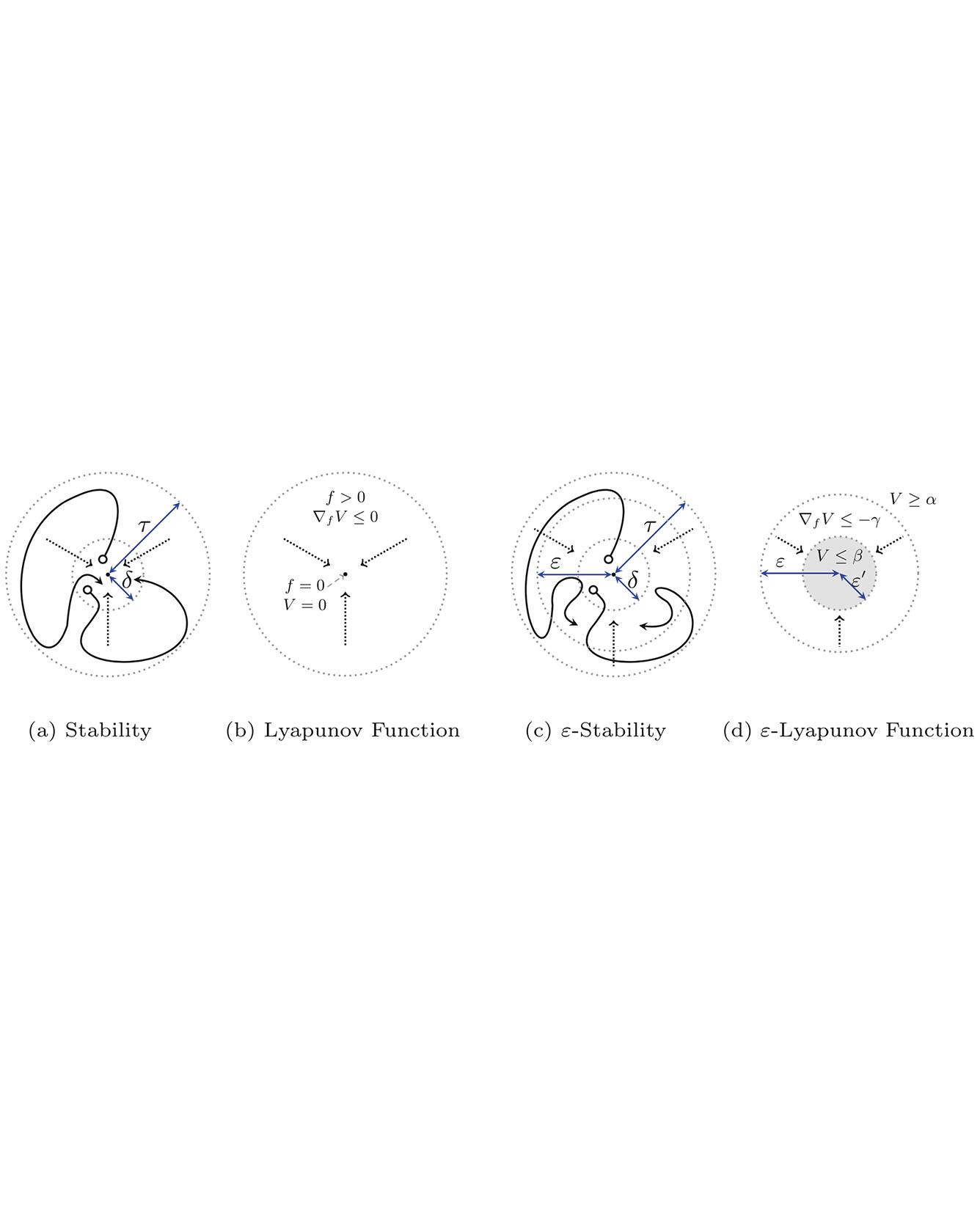
We formulate numerically-robust inductive proof rules for unbounded stability and safety properties of continuous dynamical systems. These induction rules robustify standard notions of Lyapunov functions and barrier certificates so that they can tolerate small numerical errors. In this way, numerically-driven decision procedures can establish a sound and relative-complete proof system for unbounded properties of very general nonlinear systems. We demonstrate the effectiveness of the proposed rules for rigorously verifying unbounded properties of various nonlinear systems, including a challenging powertrain control model. Read More
Citation: Gao, Sicun, James Kapinski, Jyotirmoy Deshmukh, Nima Roohi, Armando Solar-Lezama, Nikos Arechiga, and Soonho Kong. "Numerically-Robust Inductive Proof Rules for Continuous Dynamical Systems." In International Conference on Computer Aided Verification, pp. 137-154. Springer, Cham, 2019.
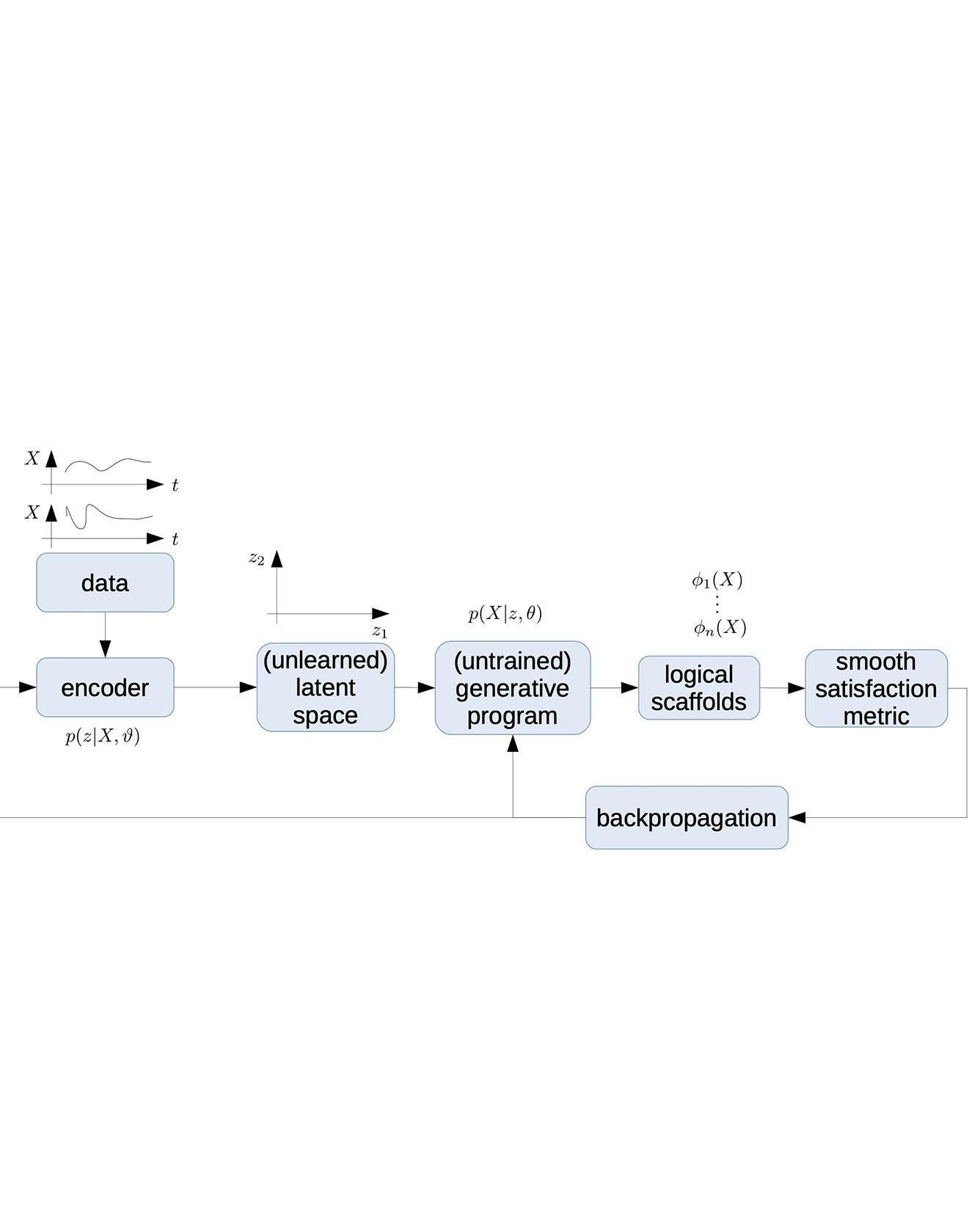
TRI Authors: Nikos Arechiga, Jonathan DeCastro, Soonho Kong All Authors: Nikos Arechiga, Jonathan DeCastro, Soonho Kong, Karen Leung We describe the concept of logical scaffolds, which can be used to improve the quality of software that relies on AI components. We explain how some of the existing ideas on runtime monitors for perception systems can be seen as a specific instance of logical scaffolds. Furthermore, we describe how logical scaffolds may be useful for improving AI programs beyond perception systems, to include general prediction systems and agent behavior models. Read More Citation: Arechiga, Nikos, Jonathan DeCastro, Soonho Kong, and Karen Leung. "Better AI through Logical Scaffolding." In FoMLaS 2019 Workshop at CAV 2019, (2019).
TRI Author: Soonho Kong
All Authors: Calvin Huang, Soonho Kong, Sicun Gao, and Damien Zufferey
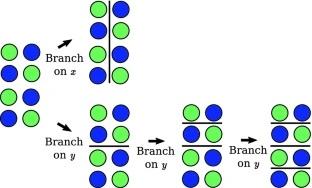
Interval Constraint Propagation (ICP) is a powerful method for solving general nonlinear constraints over real numbers. ICP uses interval arithmetic to prune the space of potential solutions and, when the constraint propagation fails, divides the space into smaller regions and continues recursively. The original goal is to find paving boxes of all solutions to a problem. Already when the whole domain needs to be considered, branching methods do matter much. However, recent applications of ICP in decision procedures over the reals need only a single solution. Consequently, variable ordering in branching operations becomes even more important.
In this work, we compare three different branching heuristics for ICP. The first method, most commonly used, splits the problem in the dimension with the largest lower and upper bound. The two other types of branching methods try to exploit an integration of analytical/numerical properties of real functions and search-based methods. The second method, called smearing, uses gradient information of constraints to choose variables that have the highest local impact on pruning. The third method, lookahead branching, designs a measure function to compare the effect of all variables on pruning operations in the next several steps.
We evaluate the performance of our methods on over 11,000 benchmarks from various sources. While the different branching methods exhibit significant differences on larger instance, none is consistently better. This shows the need for further research on branching heuristics when ICP is used to find an unique solution rather than all solutions. Read more
Citation: Huang, Calvin, Soonho Kong, Sicun Gao, and Damien Zufferey. "Evaluating Branching Heuristics in Interval Constraint Propagation for Satisfiability." In International Workshop on Numerical Software Verification, pp. 85-100. Springer, Cham, 2019.