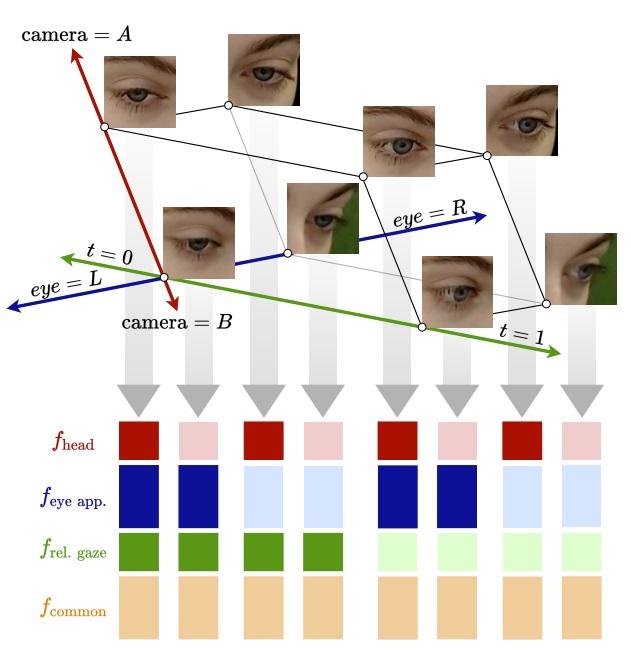
We present a method for unsupervised gaze representation learning from multiple synchronized views of a person's face. The key assumption is that images of the same eye captured from different viewpoints differ in certain respects while remaining similar in others. Specifically, the absolute gaze and absolute head pose of the same subject should be different from different viewpoints, while appearance characteristics and gaze angle relative to the head coordinate frame should remain constant. To leverage this, we adopt a cross-encoder learning framework, in which our encoding space consists of head pose, relative eye gaze, eye appearance and other common features. Image pairs which are assumed to have matching subsets of features should be able to swap those subsets among themselves without any loss of information, computed by decoding the mixed features back into images and measuring reconstruction loss. We show that by applying these assumptions to an unlabelled multi-view video dataset, we can generate more powerful representations than a standard gaze cross-encoder for few-shot gaze estimation. Furthermore, we introduce a new feature-mixing method which results in higher performance, faster training, improved testing flexibility with multiple views, and added interpretability with learned confidence. READ MORE