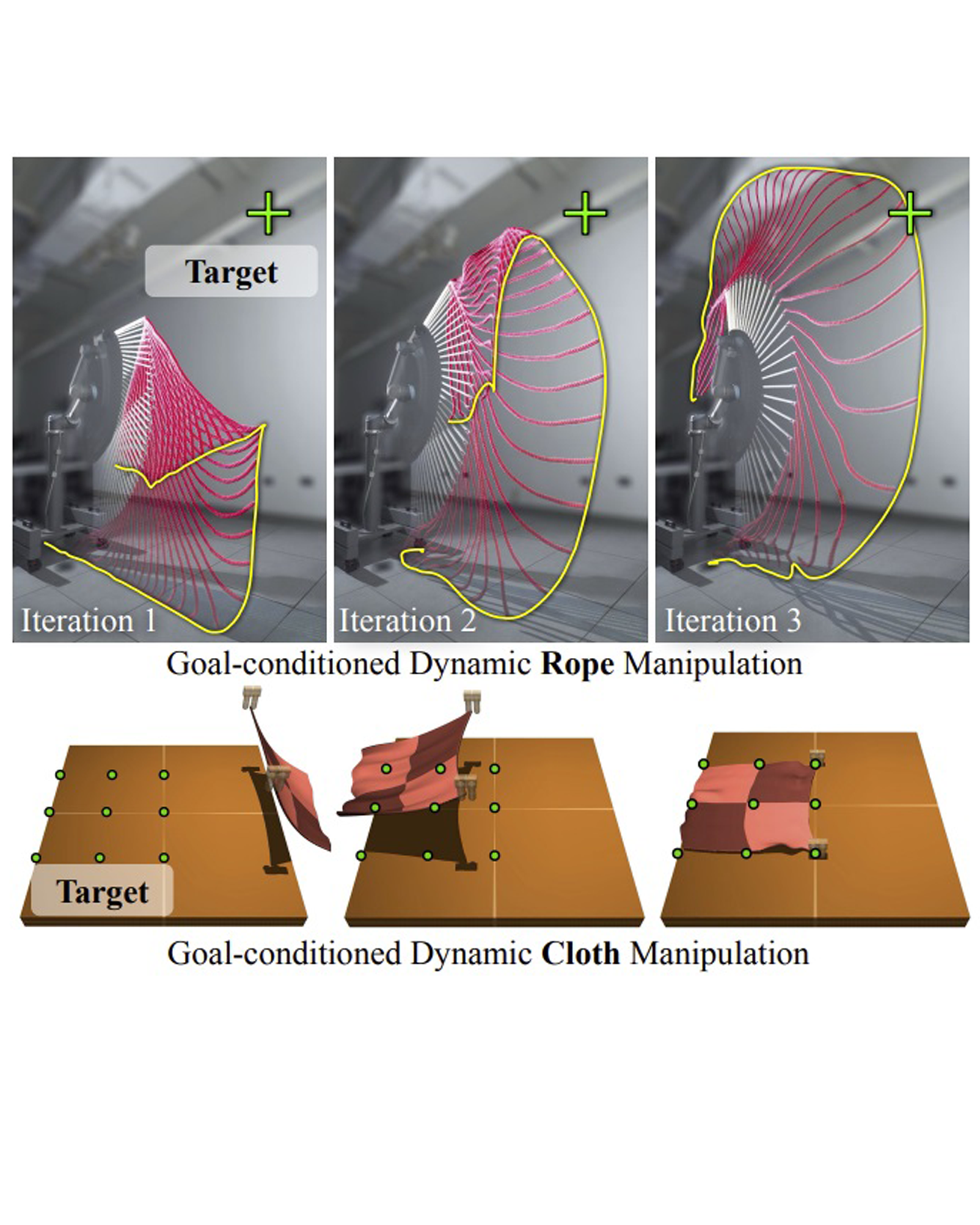
This paper tackles the task of goal-conditioned dynamic manipulation of deformable objects. This task is highly challenging due to its complex dynamics (introduced by object deformation and high-speed action) and strict task requirements (defined by a precise goal specification). To address these challenges, we present Iterative Residual Policy (IRP), a general learning framework applicable to repeatable tasks with complex dynamics. IRP learns an implicit policy via delta dynamics -- instead of modeling the entire dynamical system and inferring actions from that model, IRP learns delta dynamics that predict the effects of delta action on the previously-observed trajectory. When combined with adaptive action sampling, the system can quickly optimize its actions online to reach a specified goal. We demonstrate the effectiveness of IRP on two tasks: whipping a rope to hit a target point and swinging a cloth to reach a target pose. Despite being trained only in simulation on a fixed robot setup, IRP is able to efficiently generalize to noisy real-world dynamics, new objects with unseen physical properties, and even different robot hardware embodiments, demonstrating its excellent generalization capability relative to alternative approaches. READ MORE