
Featured Publications
All Publications
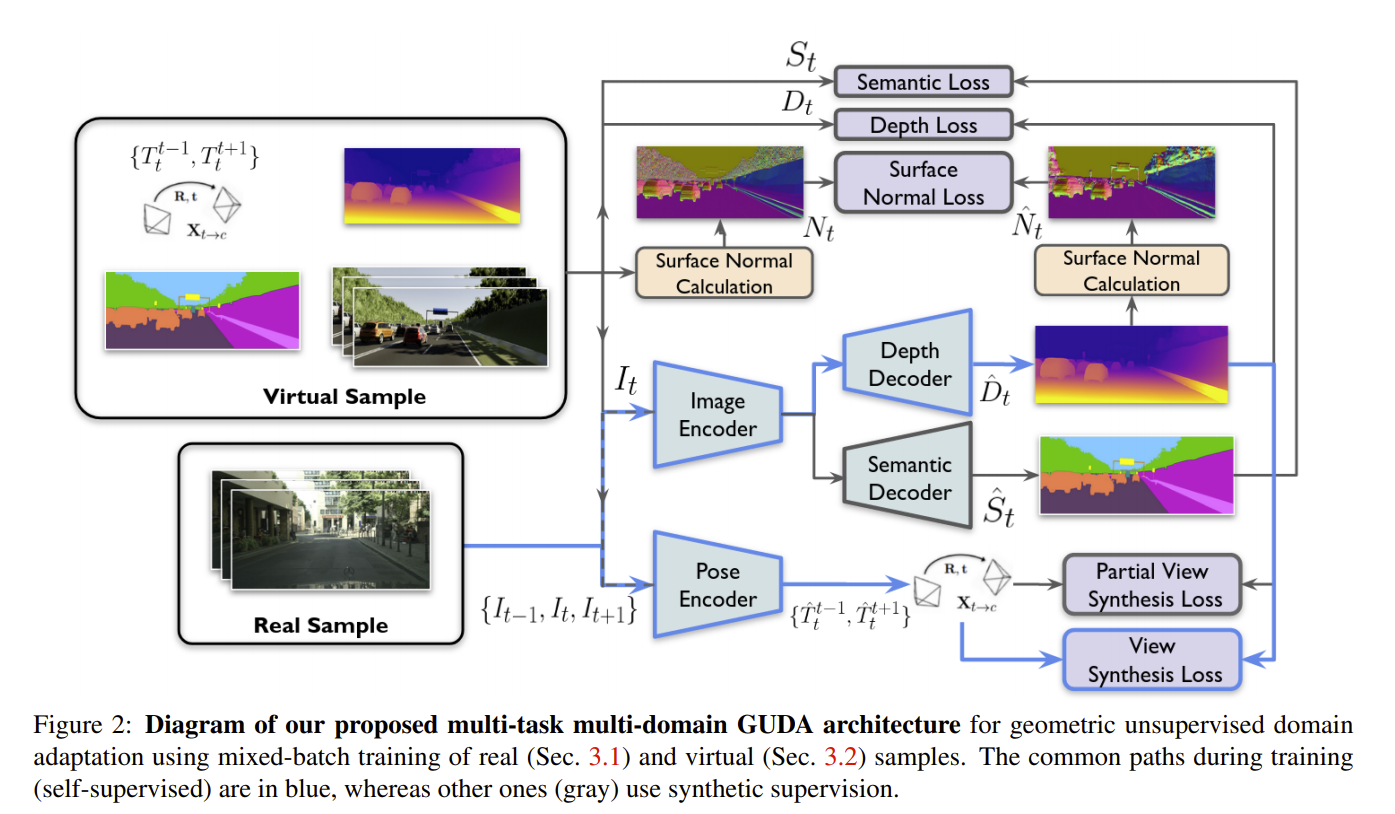
Simulators can efficiently generate large amounts of labeled synthetic data with perfect supervision for hard-to-label tasks like semantic segmentation. However, they introduce a domain gap that severely hurts real-world performance. We propose to use self-supervised monocular depth estimation as a proxy task to bridge this gap and improve sim-to-real unsupervised domain adaptation (UDA). Our Geometric Unsupervised Domain Adaptation method (GUDA) learns a domain-invariant representation via a multi-task objective combining synthetic semantic supervision with real-world geometric constraints on videos. GUDA establishes a new state of the art in UDA for semantic segmentation on three benchmarks, outperforming methods that use domain adversarial learning, self-training, or other self-supervised proxy tasks. Furthermore, we show that our method scales well with the quality and quantity of synthetic data while also improving depth prediction. READ MORE

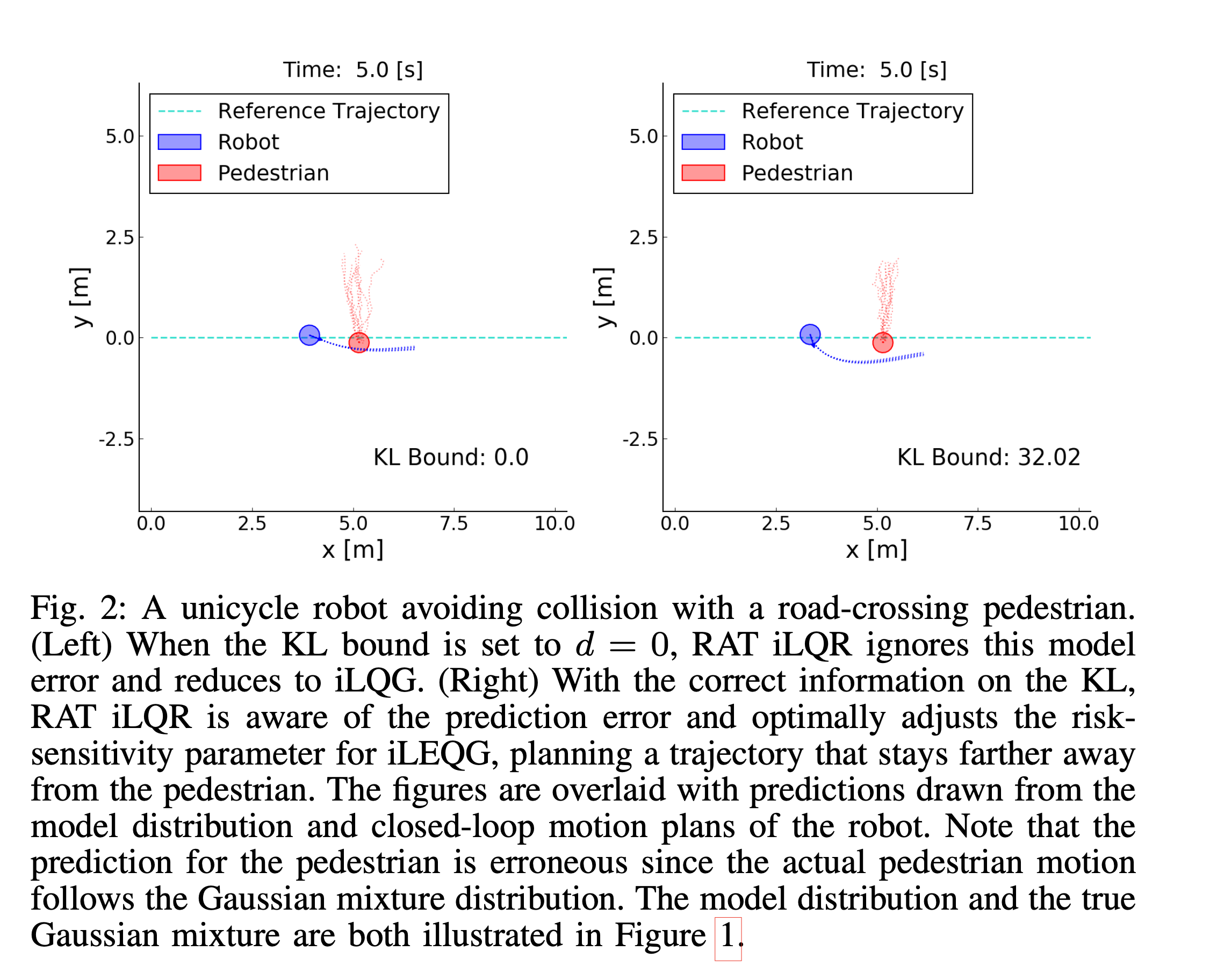
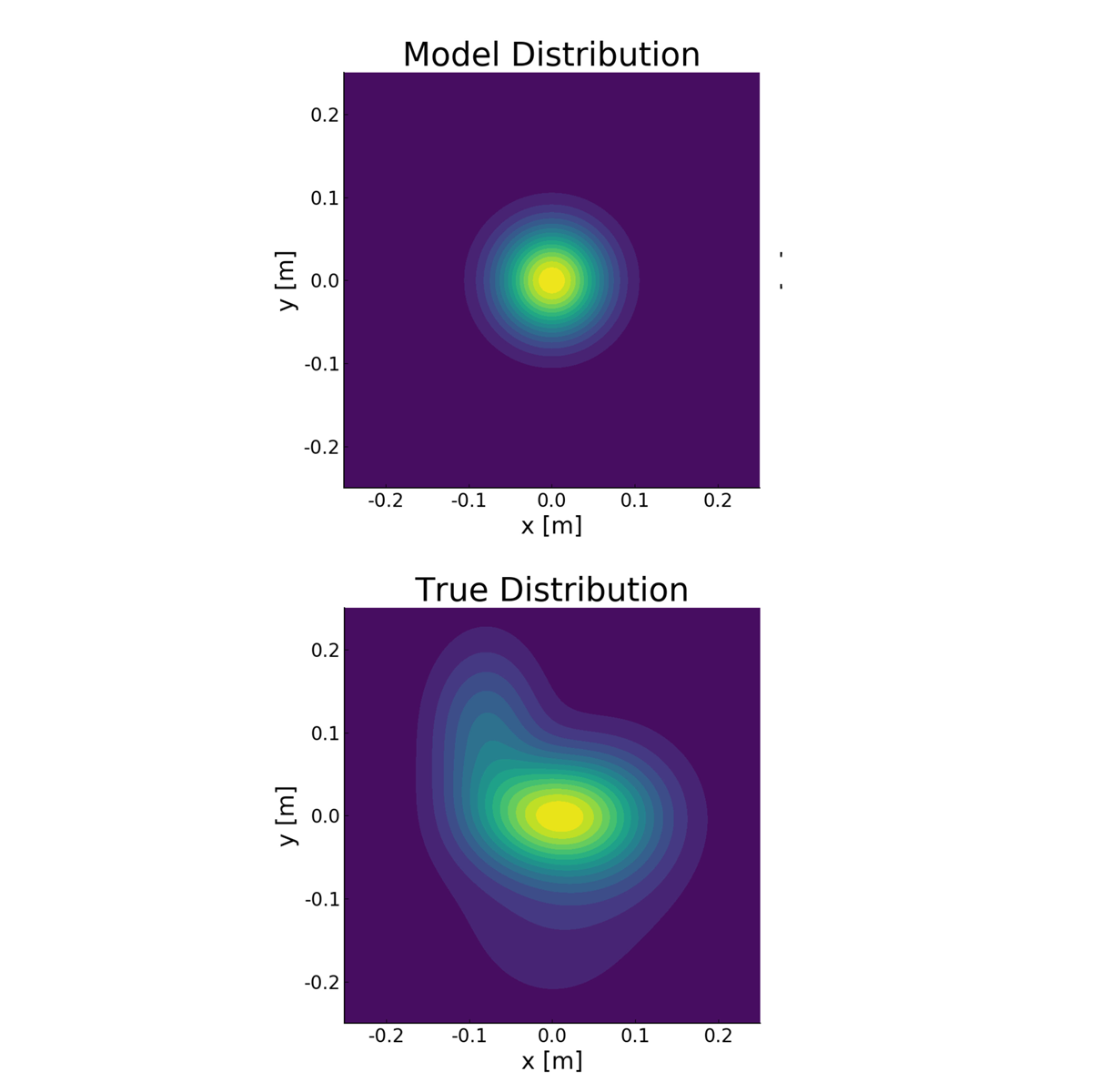
Successful robotic operation in stochastic environ- ments relies on accurate characterization of the underlying probability distributions, yet this is often imperfect due to limited knowledge. This work presents a control algorithm that is capable of handling such distributional mismatches. Specifically, we propose a novel nonlinear MPC for distributionally robust control, which plans locally optimal feedback policies against a worst-case distribution within a given KL divergence bound from a Gaussian distribution. Leveraging mathematical equivalence between distributionally robust control and risk-sensitive optimal control, our framework also provides an algorithm to dynam- ically adjust the risk-sensitivity level online for risk-sensitive control. The benefits of the distributional robustness as well as the automatic risk-sensitivity adjustment are demonstrated in a dynamic collision avoidance scenario where the predictive distribution of human motion is erroneous. READ MORE
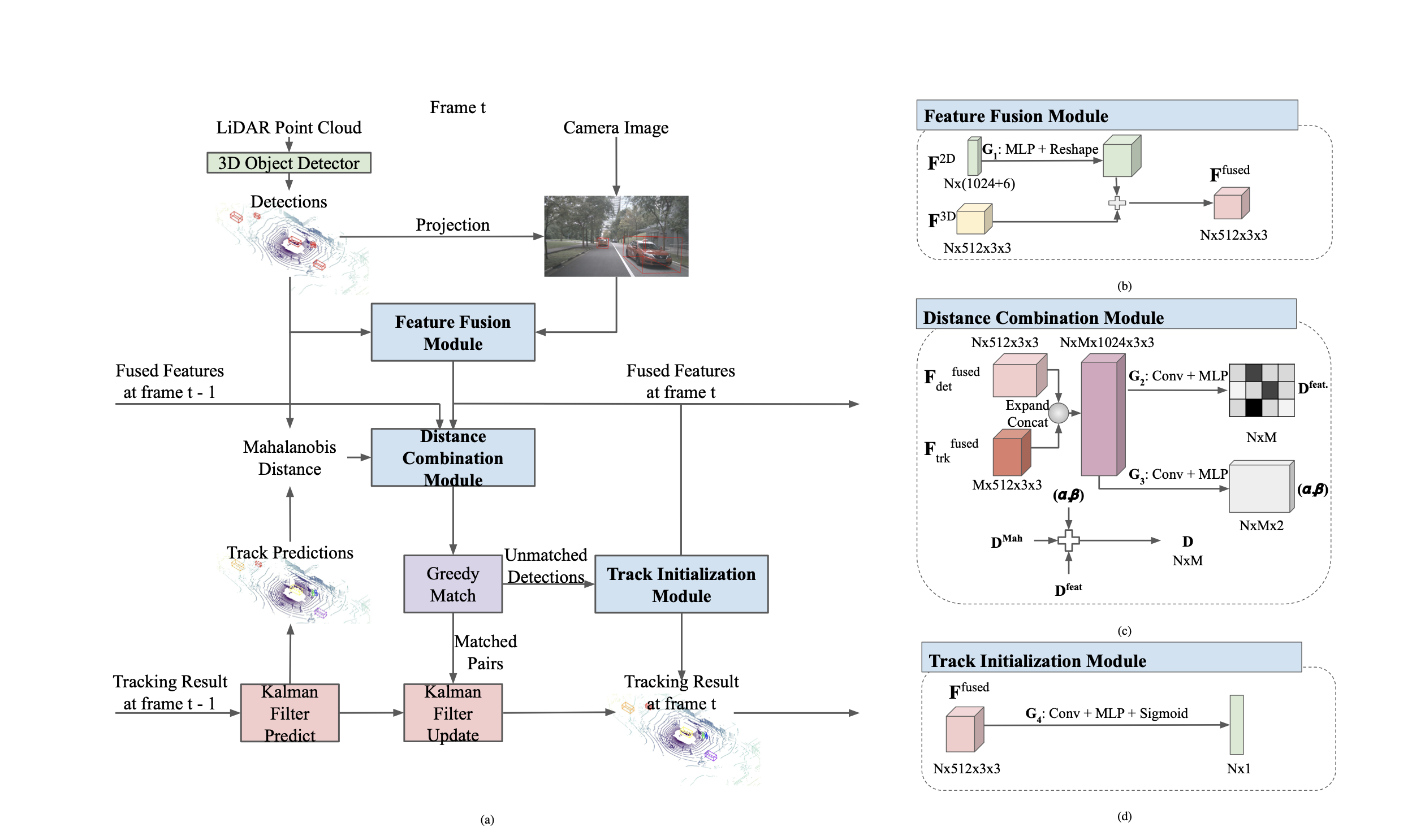
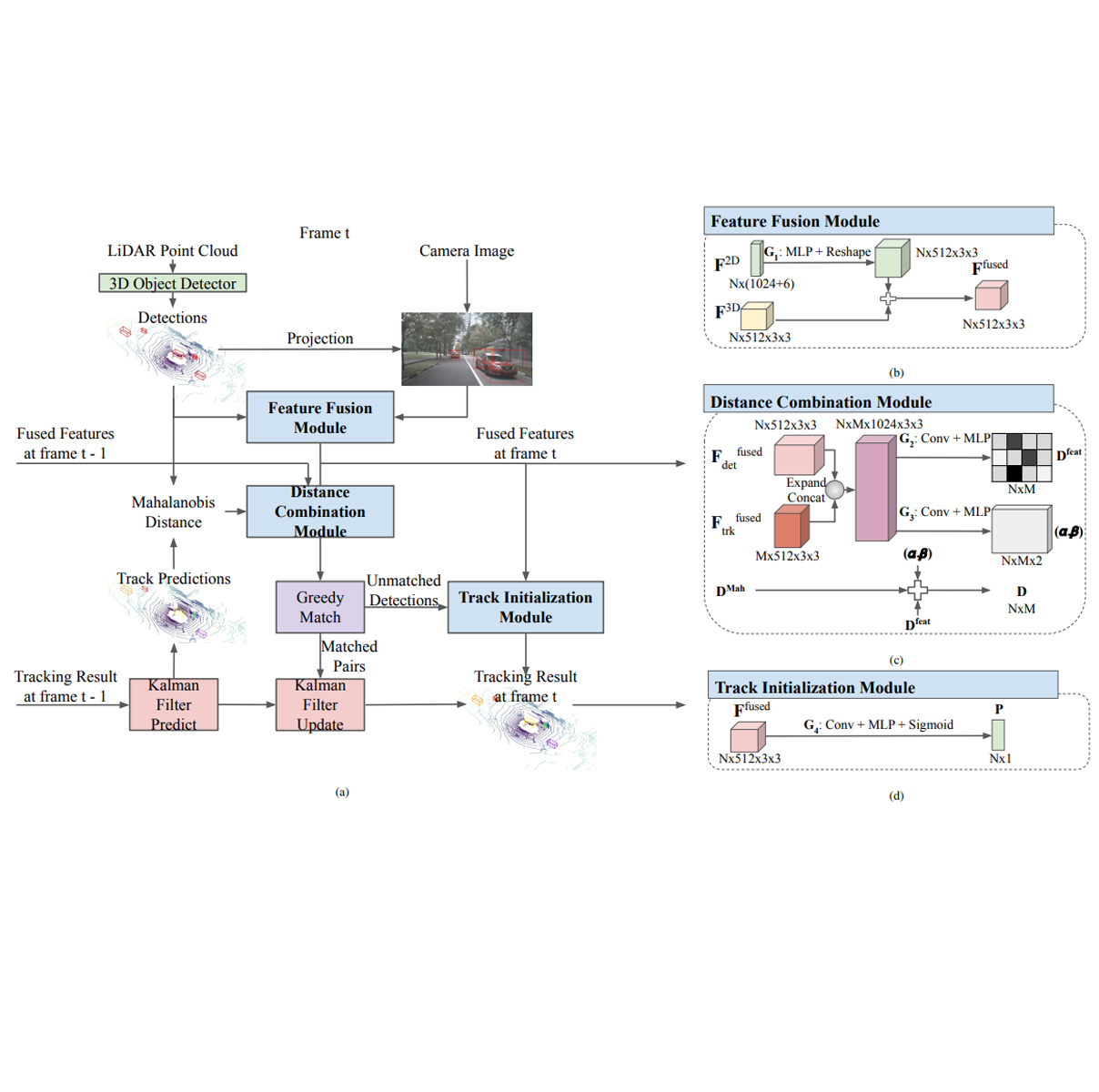
Multi-object tracking is an important ability for an autonomous vehicle to safely navigate a traffic scene. Cur- rent state-of-the-art follows the tracking-by-detection paradigm where existing tracks are associated with detected objects through some distance metric. The key challenges to increase tracking accuracy lie in data association and track life cycle management. We propose a probabilistic, multi-modal, multi- object tracking system consisting of different trainable modules to provide robust and data-driven tracking results. First, we learn how to fuse features from 2D images and 3D LiDAR point clouds to capture the appearance and geometric information of an object. Second, we propose to learn a metric that combines the Mahalanobis and feature distances when comparing a track and a new detection in data association. And third, we propose to learn when to initialize a track from an unmatched object detection. Through extensive quantitative and qualitative results, we show that our method outperforms current state- of-the-art on the NuScenes Tracking dataset. READ MORE
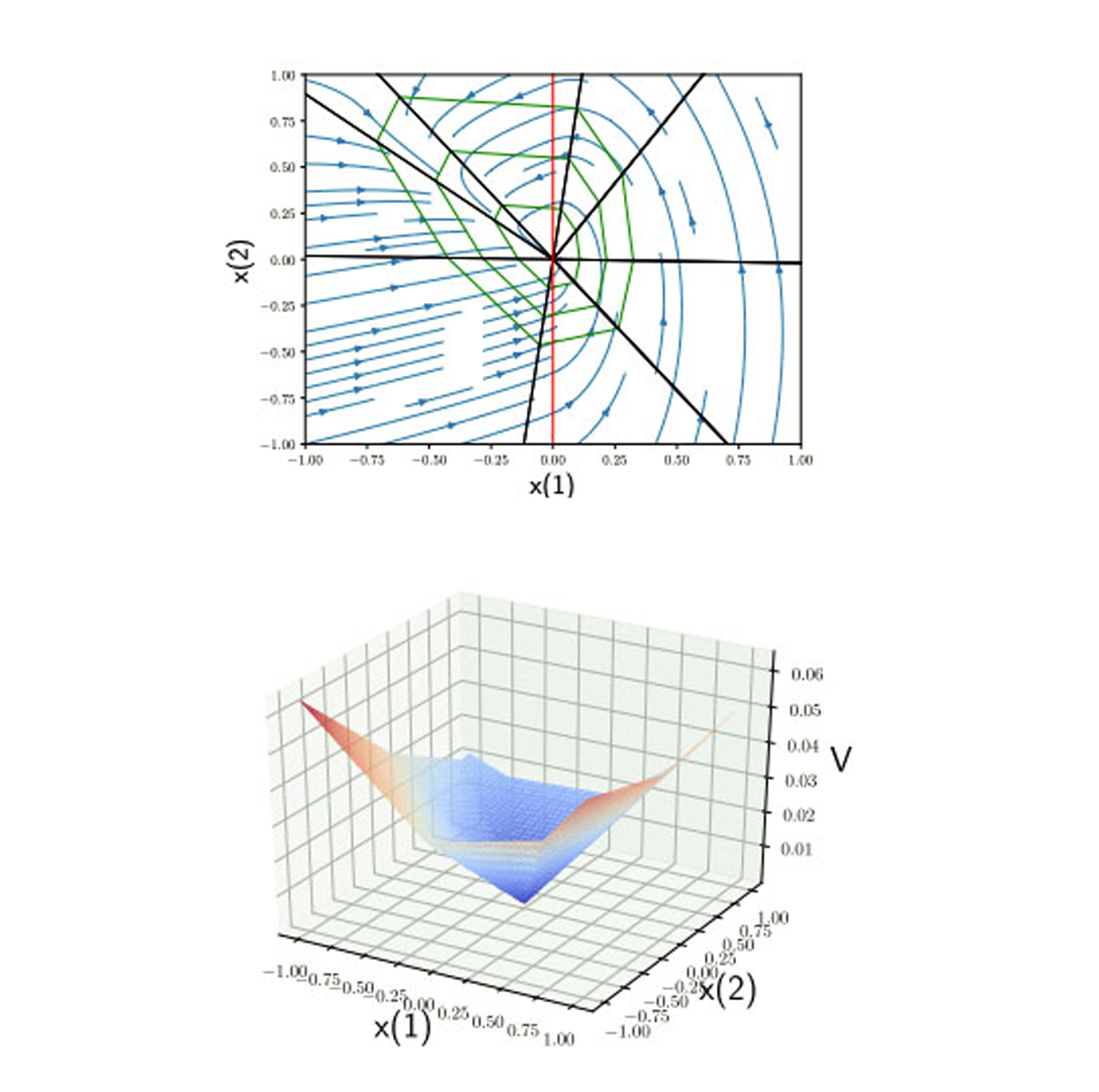
We introduce an algorithm for synthesizing and verifying piecewise linear Lyapunov functions to prove global exponential stability of piecewise linear dynamical systems. The Lyapunov functions we synthesize are parameterized by feedforward neural networks with leaky ReLU activation units. To train these neural networks, we design a loss function that measures the maximal violation of the Lyapunov conditions in the state space. We show that this maximal violation can be computed by solving a mixed-integer linear program (MILP). Compared to previous learning-based approaches, our learning approach is able to certify with high precision that the learned neural network satisfies the Lyapunov conditions not only for sampled states, but over the entire state space. Moreover, compared to previous optimization-based approaches that require a pre-specified partition of the state space when synthesizing piecewise Lyapunov functions, our method can automatically search for both the partition and the Lyapunov function simultaneously. We demonstrate our algorithm on both continuous and discrete-time systems, including some for which known strategies for partitioning of the Lyapunov function would require introducing higher order Lyapunov functions.
TRI Authors: Kuan-Hui Lee, Matthew Kliemann, Adrien Gaidon, Jie Li, Chao Fang, Sudeep Pillai, Wolfram Burgard
All Authors: KH Lee, M. Kliemann, A. Gaidon, J. Li, C. Fang, S. Pillai, W. Burgard
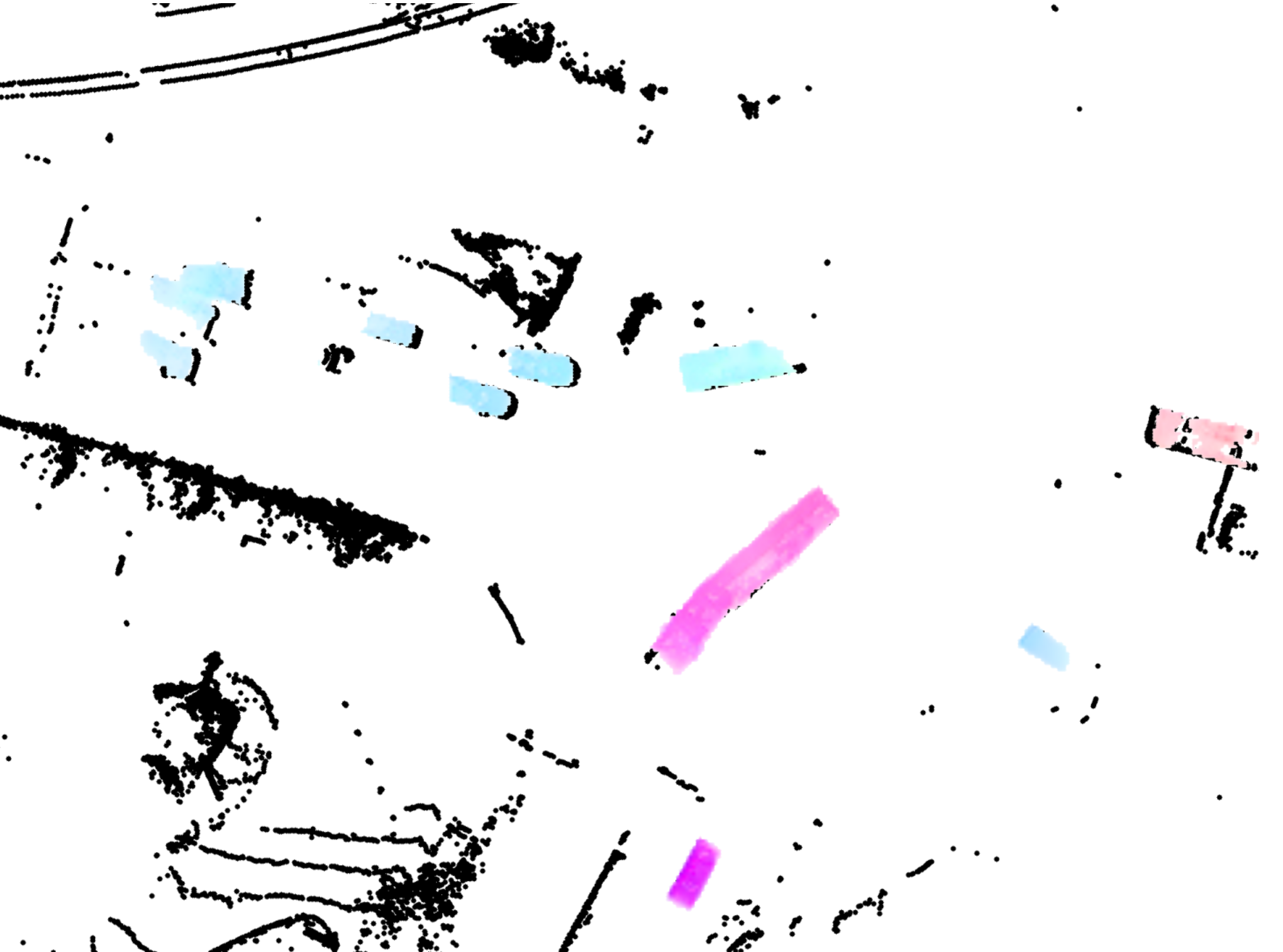
In autonomous driving, accurately estimating the state of surrounding obstacles is critical for safe and robust path planning. However, this perception task is difficult, particularly for generic obstacles/objects, due to appearance and occlusion changes. To tackle this problem, we propose an end-to-end deep learning framework for LIDAR-based flow estimation in bird's eye view (BeV). Our method takes consecutive point cloud pairs as input and produces a 2-D BeV flow grid describing the dynamic state of each cell. The experimental results show that the proposed method not only estimates 2-D BeV flow accurately but also improves tracking performance of both dynamic and static objects. Read More
Citation: Lee, Kuan-Hui, Matthew Kliemann, Adrien Gaidon, Jie Li, Chao Fang, Sudeep Pillai, and Wolfram Burgard. "PillarFlow: End-to-end Birds-eye-view Flow Estimation for Autonomous Driving." arXiv e-prints (2020) To appear in IROS, 2020
TRI Authors: Adrien Gaidon, Rares Ambrus, Guy Rosman, Wolfram Burgard.
All Authors: Buhler, Andreas, Adrien Gaidon, Andrei Cramariuc, Rares Ambrus, Guy Rosman, Wolfram Burgard.
Safe autonomous driving requires robust detection of other traffic participants. However, robust does not mean perfect, and safe systems typically minimize missed detections at the expense of a higher false positive rate. This results in conservative and yet potentially dangerous behavior such as avoiding imaginary obstacles. In the context of behavioral cloning, perceptual errors at training time can lead to learning difficulties or wrong policies, as expert demonstrations might be inconsistent with the perceived world state. In this work, we propose a behavioral cloning approach that can safely leverage imperfect perception without being conservative. Our core contribution is a novel representation of perceptual uncertainty for learning to plan. We propose a new probabilistic birds-eye-view semantic grid to encode the noisy output of object perception systems. We then leverage expert demonstrations to learn an imitative driving policy using this probabilistic representation. Using the CARLA simulator, we show that our approach can safely overcome critical false positives that would otherwise lead to catastrophic failures or conservative behavior. Read More
Citation: Buhler, Andreas, Adrien Gaidon, Andrei Cramariuc, Rares Ambrus, Guy Rosman, Wolfram Burgard. "Driving Through Ghosts: Behavioral Cloning with False Positives." To appear in International Conference on Intelligent Robots and Systems (IROS) 2020.

TRI Authors: Kuan-Hui Lee, Adrien Gaidon All Authors: K. Mangalam, H. Girase, S. Agarwal, K-H. Lee, E. Adeli, J. Malik, A. Gaidon
Human trajectory forecasting with multiple socially interacting agents is of critical importance for autonomous navigation in human environments, e.g., for self-driving cars and social robots. In this work, we present Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction. PECNet infers distant trajectory endpoints to assist in long-range multi-modal trajectory prediction. A novel non-local social pooling layer enables PECNet to infer diverse yet socially compliant trajectories. Additionally, we present a simple "truncation-trick" for improving few-shot multi-modal trajectory prediction performance. We show that PECNet improves state-of-the-art performance on the Stanford Drone trajectory prediction benchmark by ~20.9% and on the ETH/UCY benchmark by ~40.8%. Read more
Citation: Mangalam, Karttikeya, Harshayu Girase, Shreyas Agarwal, Kuan-Hui Lee, Ehsan Adeli, Jitendra Malik, and Adrien Gaidon. "It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction." ECCV, 2020 arXiv preprint arXiv:2004.02025 (2020).

TRI Authors: Allan Raventos, Adrien Gaidon, Guy Rosman
All Authors: Cao, Zhangjie, Erdem Biyik, Woodrow Wang, Allan Raventos, Adrien Gaidon, Guy Rosman, and Dorsa Sadigh
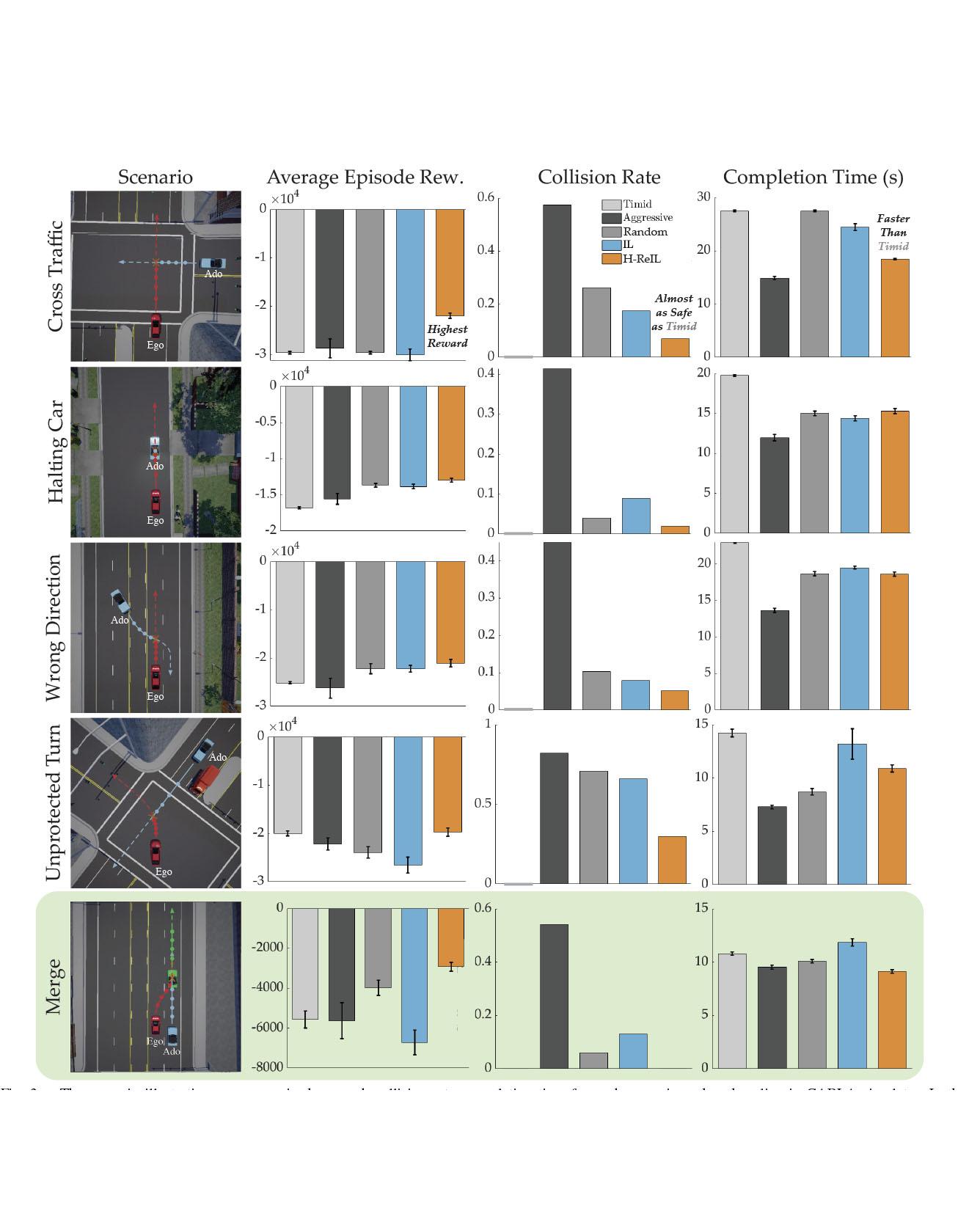
Autonomous driving has achieved significant progress in recent years, but autonomous cars are still unable to tackle high-risk situations where a potential accident is likely. In such near-accident scenarios, even a minor change in the vehicle's actions may result in drastically different consequences. To avoid unsafe actions in near-accident scenarios, we need to fully explore the environment. However, reinforcement learning (RL) and imitation learning (IL), two widely-used policy learning methods, cannot model rapid phase transitions and are not scalable to fully cover all the states. To address driving in near-accident scenarios, we propose a hierarchical reinforcement and imitation learning (H-ReIL) approach that consists of low-level policies learned by IL for discrete driving modes, and a high-level policy learned by RL that switches between different driving modes. Our approach exploits the advantages of both IL and RL by integrating them into a unified learning framework. Experimental results and user studies suggest our approach can achieve higher efficiency and safety compared to other methods. Analyses of the policies demonstrate our high-level policy appropriately switches between different low-level policies in near-accident driving situations. Read More
Citation: Cao, Zhangjie, Erdem Biyik, Woodrow Wang, Allan Raventos, Adrien Gaidon, Guy Rosman, and Dorsa Sadigh, "Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving," Robotics: Science and Systems (RSS) (2020).
TRI Authors: KH Lee, A. Gaidon
All Authors: B. Pan, H. Cai, DA Huang, KH Lee, A. Gaidon, E. Adeli, JC Niebles
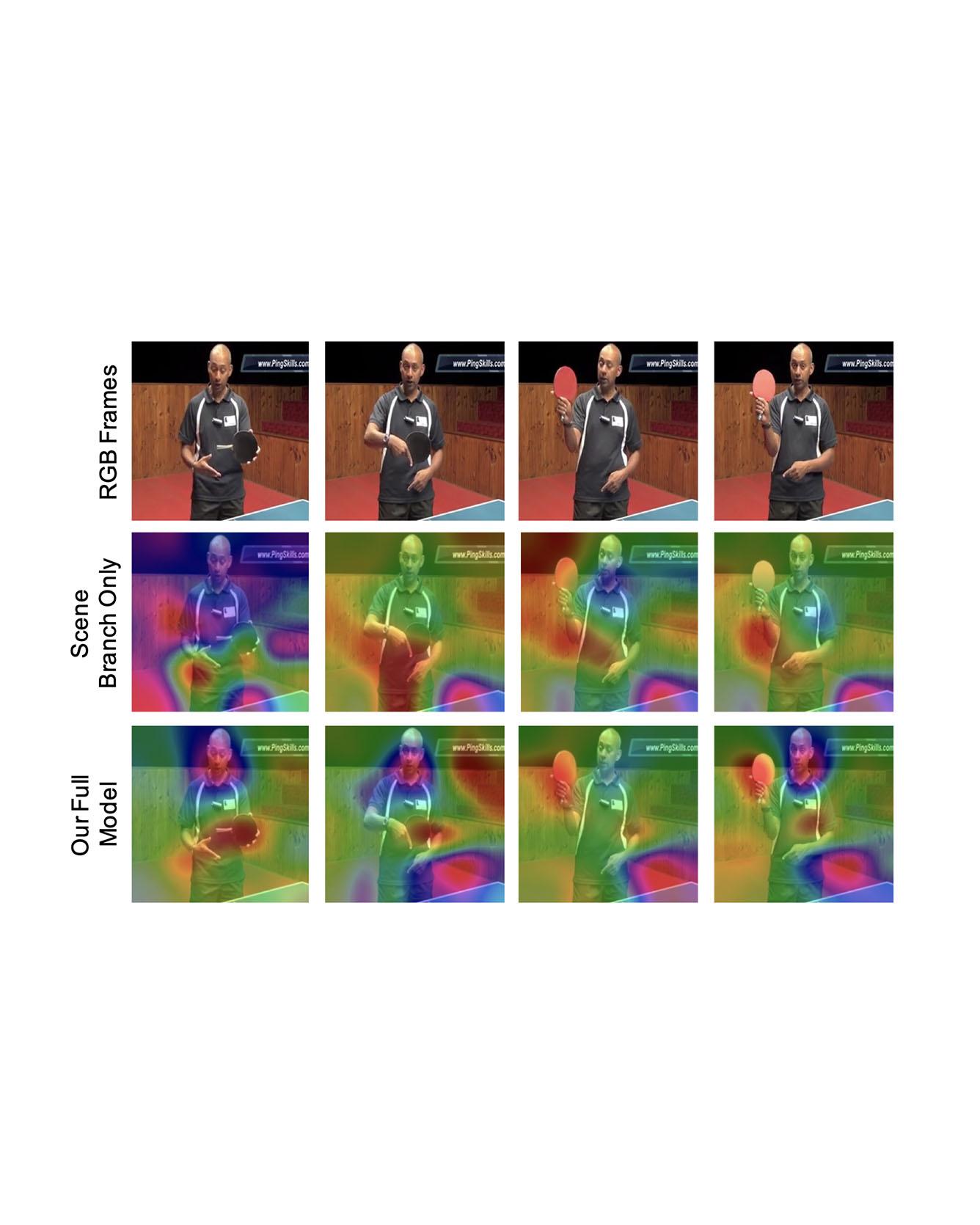
Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions. Read More
Citation: Pan, Boxiao, Haoye Cai, De-An Huang, Kuan-Hui Lee, Adrien Gaidon, Ehsan Adeli, and Juan Carlos Niebles. "Spatio-Temporal Graph for Video Captioning with Knowledge Distillation." CVPR, 2020.
TRI Authors: J. Li, A. Bhargava, A. Raventos, V. Guizilini, C. Fang, A. Gaidon
All Authors: R. Hou, J. Li, A. Bhargava, A. Raventos, V. Guizilini, C. Fang, J Lynch, A. Gaidon
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference. Read More
Citation: Hou, Rui, Jie Li, Arjun Bhargava, Allan Raventos, Vitor Guizilini, Chao Fang, Jerome Lynch, and Adrien Gaidon. "Real-Time Panoptic Segmentation from Dense Detections." CVPR 2020.
