
Featured Publications
All Publications
TRI Authors: Jonathan DeCastro, Russ Tedrake
All Authors: J. DeCastro, L. Liebenwein, C.-I. Vasile, R. Tedrake, S. Karaman and D. Rus
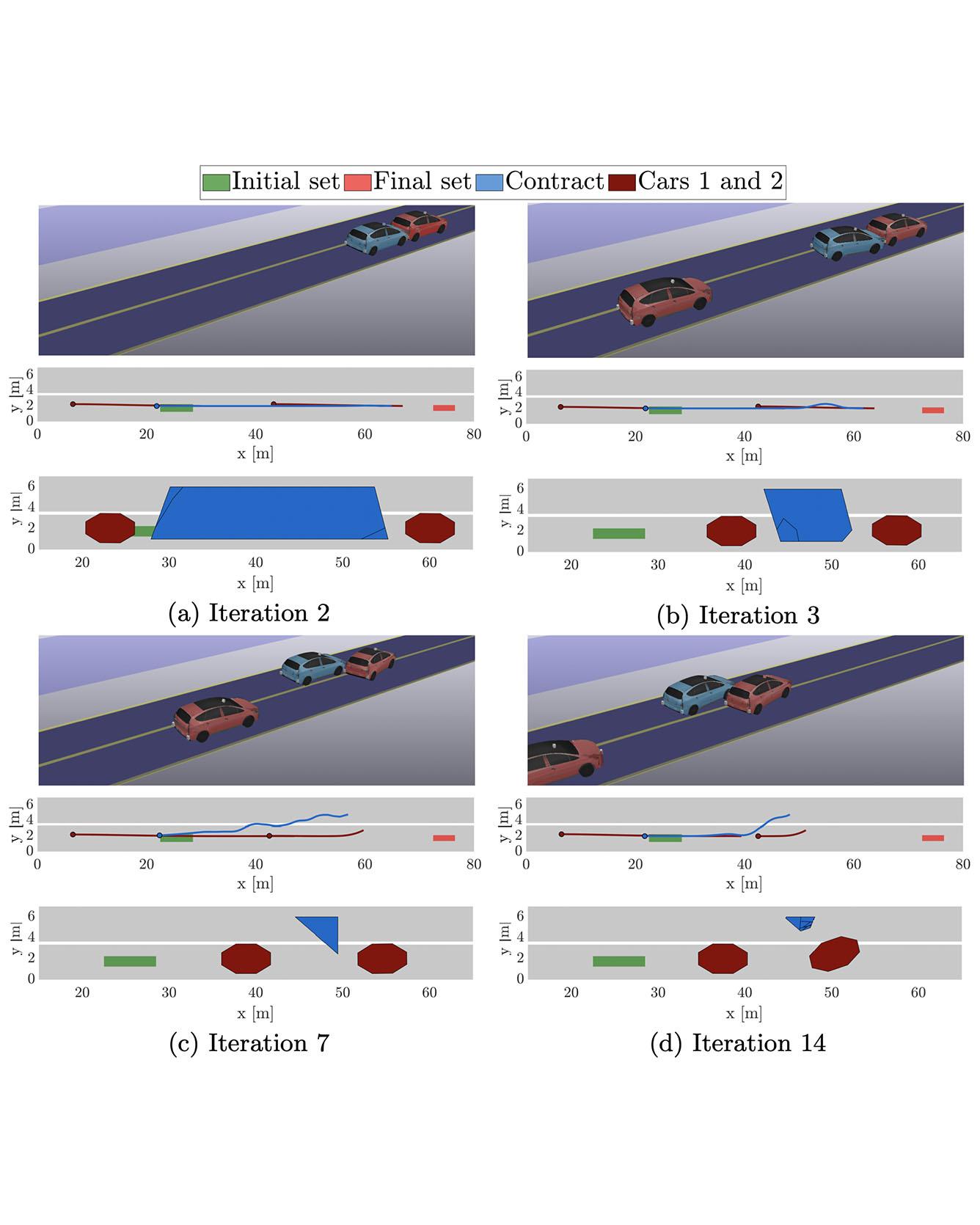
Ensuring the safety of autonomous vehicles is paramount for their successful deployment. However, formally verifying autonomous driving decisions systems is difficult. In this paper, we propose a framework for constructing a set of safety contracts that serve as design requirements for controller synthesis for a given scenario. The contracts guarantee that the controlled system will remain safe with respect to probabilistic models of traffic behavior, and, furthermore, that it will follow rules of the road. We create contracts using an iterative approach that alternates between falsification and reachable set computation. Counterexamples to collision-free behavior are found by solving a gradientbased trajectory optimization problem. We treat these counterexamples as obstacles in a reach-avoid problem that quantifies the set of behaviors an ego vehicle can make while avoiding the counterexample. Contracts are then derived directly from the reachable set. We demonstrate that the resulting design requirements are able to separate safe from unsafe behaviors in an interacting multi-car traffic scenario, and further illustrate their utility in analyzing the safety impact of relaxing traffic rules. Read More
Citation: DeCastro, Jonathan, Lucas Liebenwein, Cristian-Ioan Vasile, Russ Tedrake, Sertac Karaman, and Daniela Rus. "Counterexample-guided safety contracts for autonomous driving." In International Workshop on the Algorithmic Foundations of Robotics, 2018.
TRI Authors: Jie Li, Allan Raventos, Arjun Bhargava, Takaaki Tagawa, Adrien Gaidon
All Authors: Jie Li, Allan Raventos, Arjun Bhargava, Takaaki Tagawa, Adrien Gaidon
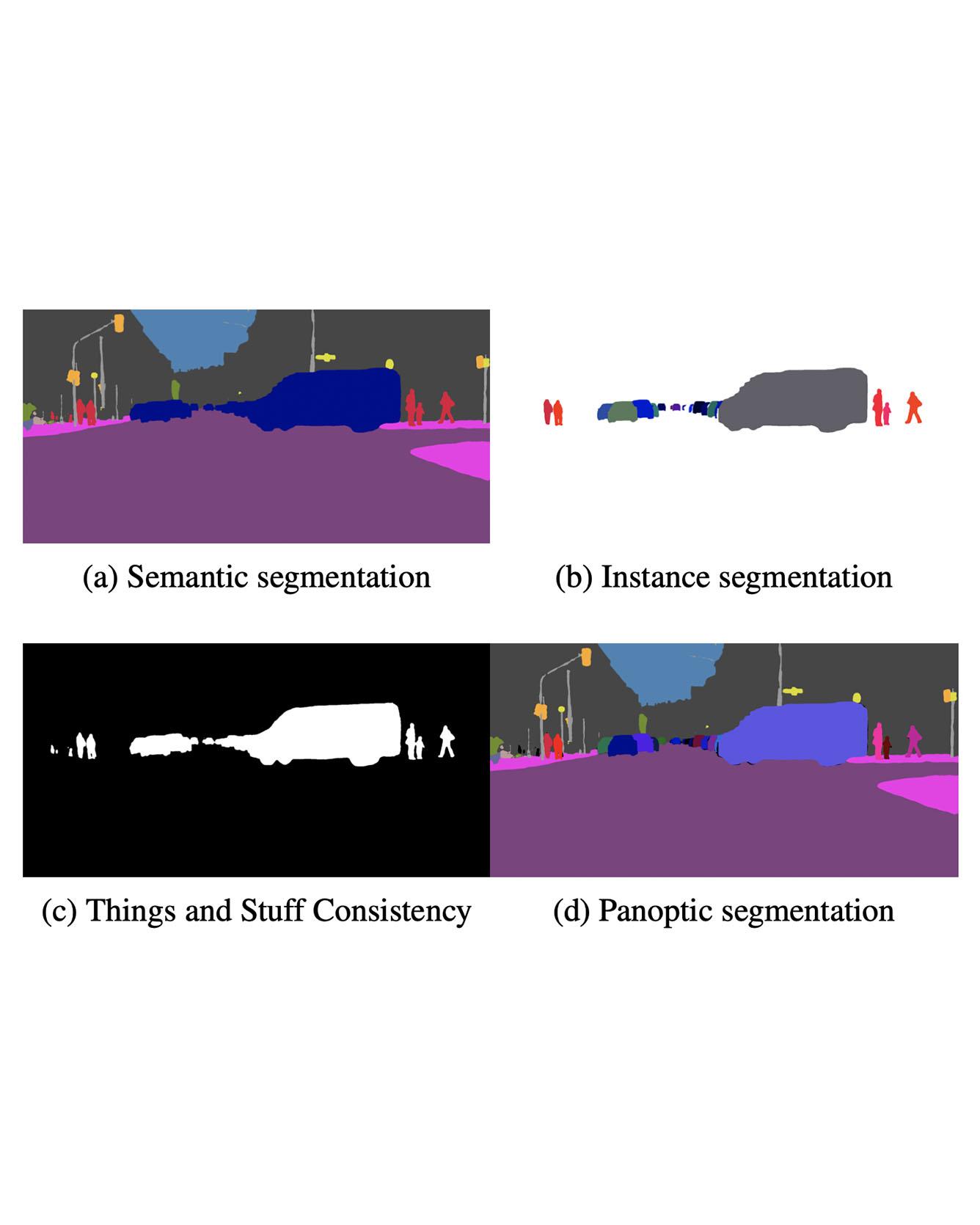
We propose an end-to-end learning approach for panoptic segmentation, a novel task unifying instance (things) and semantic (stuff) segmentation. Our model, TASCNet, uses feature maps from a shared backbone network to predict in a single feed-forward pass both things and stuff segmentations. We explicitly constrain these two output distributions through a global things and stuff binary mask to enforce cross-task consistency. Our proposed unified network is competitive with the state of the art on several benchmarks for panoptic segmentation as well as on the individual semantic and instance segmentation tasks. Read more
Citation: Li, Jie, Allan Raventos, Arjun Bhargava, Takaaki Tagawa, and Adrien Gaidon. "Learning to fuse things and stuff." arXiv preprint arXiv:1812.01192 (2018).
TRI Author: Rares Ambrus
All Authors: Cristiano Premebida, Rares Ambrus, Zoltan-Csaba Marton
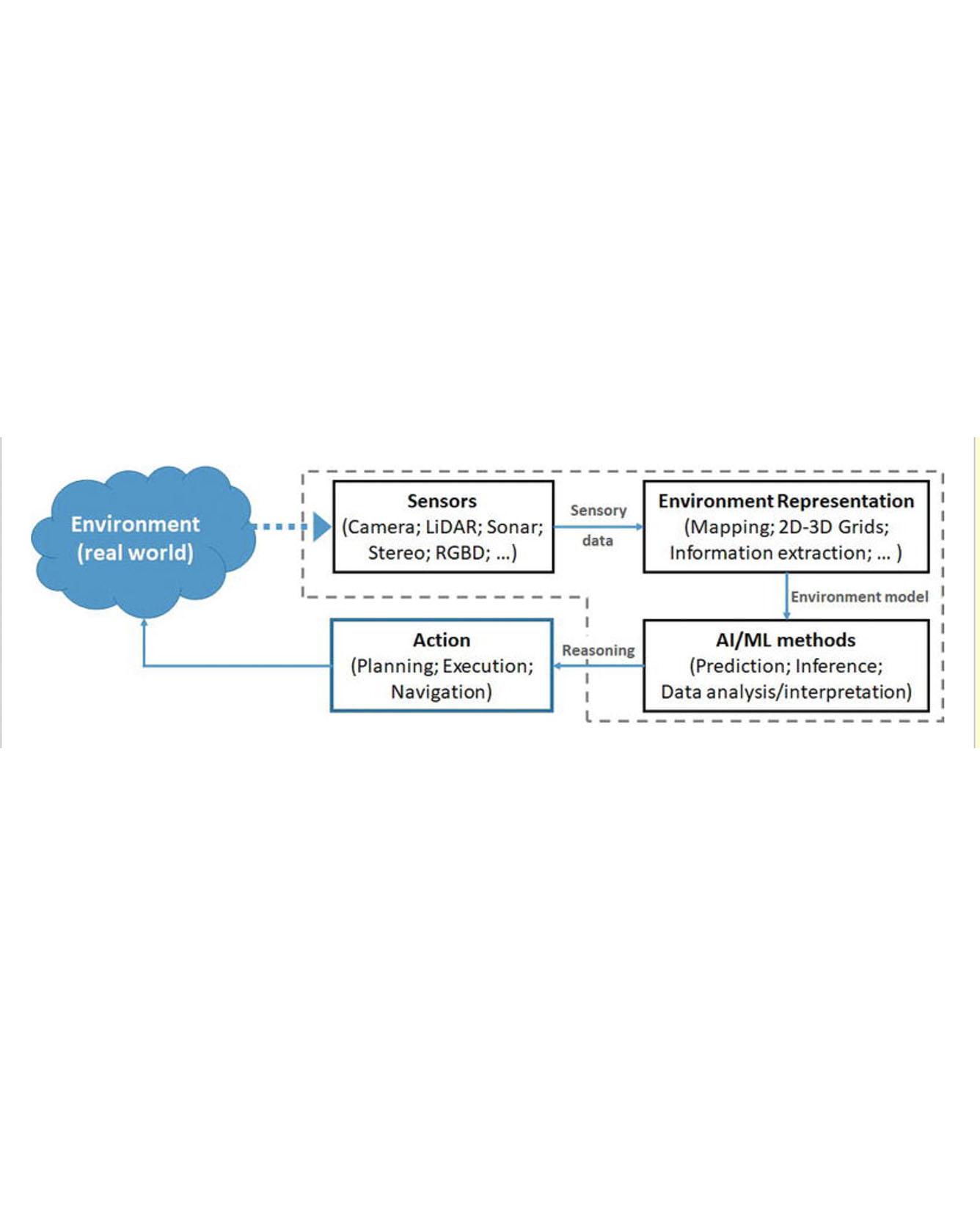
Robotic perception is related to many applications in robotics where sensory data and artificial intelligence/machine learning (AI/ML) techniques are involved. Examples of such applications are object detection, environment representation, scene understanding, human/pedestrian detection, activity recognition, semantic place classification, object modeling, among others. Robotic perception, in the scope of this chapter, encompasses the ML algorithms and techniques that empower robots to learn from sensory data and, based on learned models, to react and take decisions accordingly. The recent developments in machine learning, namely deep-learning approaches, are evident and, consequently, robotic perception systems are evolving in a way that new applications and tasks are becoming a reality. Recent advances in human-robot interaction, complex robotic tasks, intelligent reasoning, and decision-making are, at some extent, the results of the notorious evolution and success of ML algorithms. This chapter will cover recent and emerging topics and use-cases related to intelligent perception systems in robotics. Read More
Citation:Premebida, Cristiano, Rares Ambrus, and Zoltan-Csaba Marton. "Intelligent Robotic Perception Systems." In Applications of Mobile Robots. IntechOpen, 2018.
TRI Authors: Guy Rosman
All Authors: F. Naser, I. Gilitschenski, G. Rosman, A. Amini, F. Durand, A. Torralba, G. W. Wornell, W. T. Freeman, S. Karaman, and D. Rus
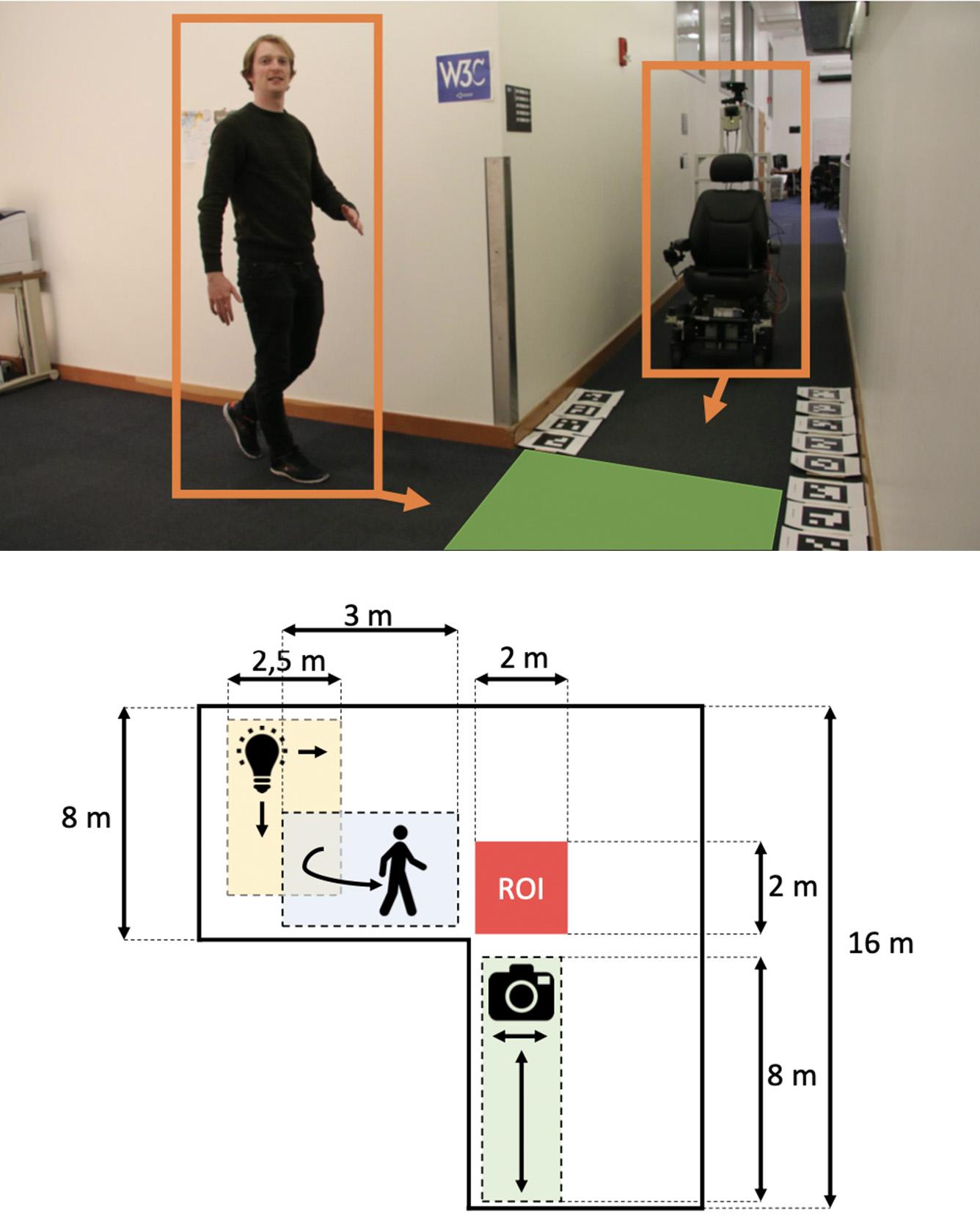
Moving obstacles occluded by corners are a potential source for collisions in mobile robotics applications such as autonomous vehicles. In this paper, we address the problem of anticipating such collisions by proposing a vision-based detection algorithm for obstacles which are outside of a vehicle's direct line of sight. Our method detects shadows of obstacles hidden around corners and automatically classifies these unseen obstacles as “dynamic” or “static”. We evaluate our proposed detection algorithm on real-world corners and a large variety of simulated environments to assess generalizability in different challenging surface and lighting conditions. The mean classification accuracy on simulated data is around 80% and on real-world corners approximately 70%. Additionally, we integrate our detection system on a full-scale autonomous wheelchair and demonstrate its feasibility as an additional safety mechanism through real-world experiments. We release our real-time-capable implementation of the proposed ShadowCam algorithm and the dataset containing simulated and real-world data under an open-source license. Read more
Citation: Naser, Felix, Igor Gilitschenski, Guy Rosman, Alexander Amini, Fredo Durand, Antonio Torralba, Gregory W. Wornell, William T. Freeman, Sertac Karaman, and Daniela Rus. "Shadowcam: Real-time detection of moving obstacles behind A corner for autonomous vehicles." In 2018 21st International Conference on Intelligent Transportation Systems (ITSC), pp. 560-567. IEEE, 2018.
TRI Authors: Kuan-Hui Lee, Jie Li, Adrien Gaidon
All Authors: Kuan-Hui Lee, German Ros, Jie Li, Adrien Gaidon
Deep Learning for Computer Vision depends mainly on the source of supervision.Photo-realistic simulators can generate large-scale automatically labeled syntheticdata, but introduce a domain gap negatively impacting performance. We propose anew unsupervised domain adaptation algorithm, called SPIGAN, relying on Sim-ulator Privileged Information (PI) and Generative Adversarial Networks (GAN).We use internal data from the simulator as PI during the training of a target tasknetwork. We experimentally evaluate our approach on semantic segmentation. Wetrain the networks on real-world Cityscapes and Vistas datasets, using only unla-beled real-world images and synthetic labeled data with z-buffer (depth) PI fromthe SYNTHIA dataset. Our method improves over no adaptation and state-of-the-art unsupervised domain adaptation techniques. Read More
Citation: Lee, Kuan-Hui, German Ros, Jie Li, and Adrien Gaidon. "SPIGAN: Privileged adversarial learning from simulation." In International Conference on Learning Representations, 2019.

TRI Authors: Sudeep Pillai, Rares Ambrus, Adrien Gaidon
All Authors: Sudeep Pillai, Rares Ambrus, Adrien Gaidon
Recent techniques in self-supervised monocular depth estimation are approaching the performance of supervised methods, but operate in low resolution only. We show that high resolution is key towards high-fidelity self-supervised monocular depth prediction. Inspired by recent deep learning methods for Single-Image Super-Resolution, we propose a sub-pixel convolutional layer extension for depth super-resolution that accurately synthesizes high-resolution disparities from their corresponding low-resolution convolutional features. In addition, we introduce a differentiable flip-augmentation layer that accurately fuses predictions from the image and its horizontally flipped version, reducing the effect of left and right shadow regions generated in the disparity map due to occlusions. Both contributions provide significant performance gains over the state-of-the-art in self-supervised depth and pose estimation on the public KITTI benchmark. A video of our approach can be found at this https URL. Read More
Citation: Pillai, Sudeep, Rareş Ambruş, and Adrien Gaidon. "Superdepth: Self-supervised, super-resolved monocular depth estimation." In 2019 International Conference on Robotics and Automation (ICRA), pp. 9250-9256. IEEE, 2019.

TRI Author: Guy Rosman
All Authors: Alexander Amini, Wilko Schwarting, Guy Rosman, Brandon Araki, Sertac Karaman, Daniela Rus
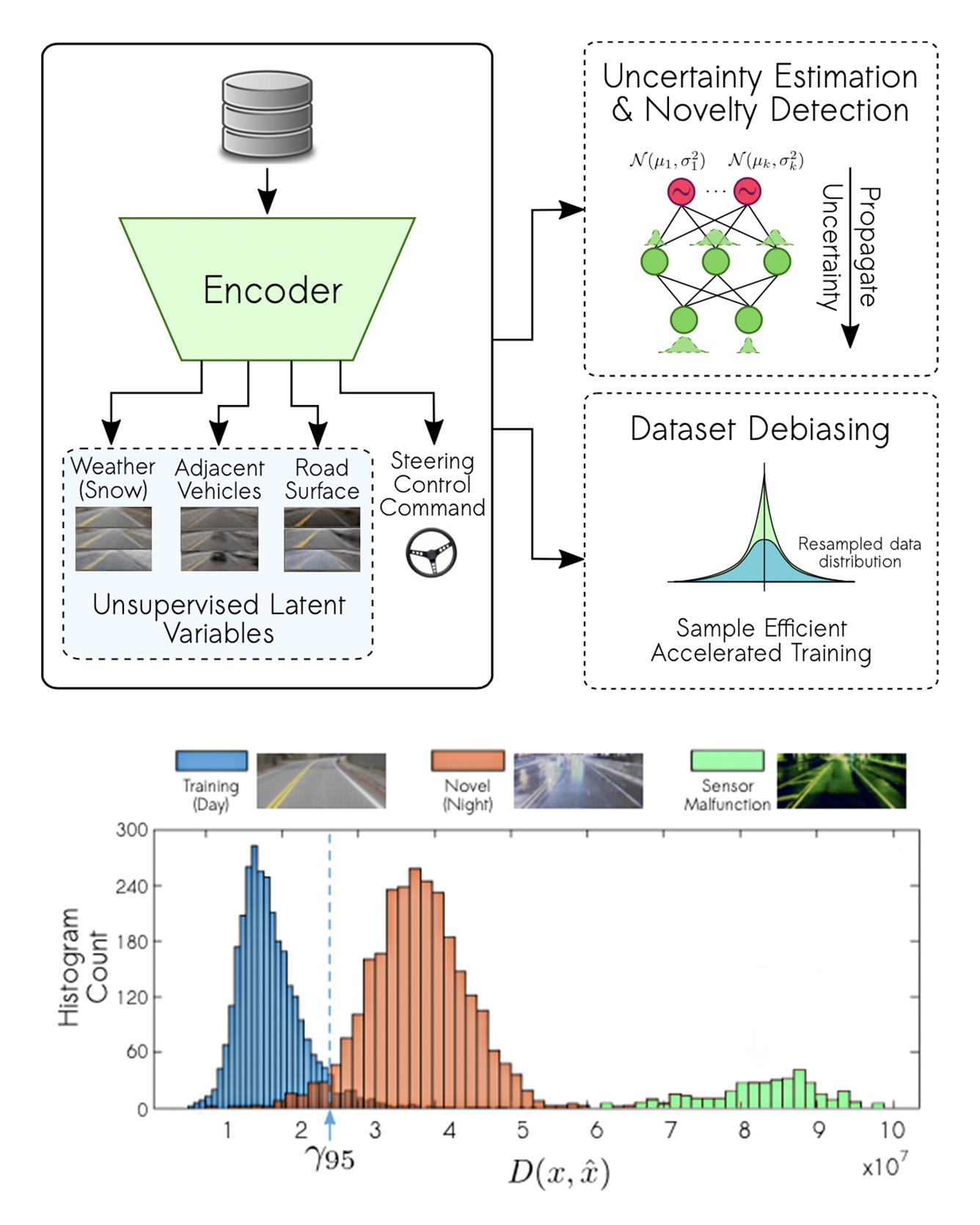
This paper introduces a new method for end-to-end training of deep neural networks (DNNs) and evaluates it in the context of autonomous driving. DNN training has been shown to result in high accuracy for perception to action learning given sufficient training data. However, the trained models may fail without warning in situations with insufficient or biased training data. In this paper, we propose and evaluate a novel architecture for self-supervised learning of latent variables to detect the insufficiently trained situations. Our method also addresses training data imbalance, by learning a set of underlying latent variables that characterize the training data and evaluate potential biases. We show how these latent distributions can be leveraged to adapt and accelerate the training pipeline by training on only a fraction of the total dataset. We evaluate our approach on a challenging dataset for driving. The data is collected from a full-scale autonomous vehicle. Our method provides qualitative explanation for the latent variables learned in the model. Finally, we show how our model can be additionally trained as an end-to-end controller, directly outputting a steering control command for an autonomous vehicle. Read more
Citation: Amini, Alexander, Wilko Schwarting, Guy Rosman, Brandon Araki, Sertac Karaman, and Daniela Rus. "Variational autoencoder for end-to-end control of autonomous driving with novelty detection and training de-biasing." In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 568-575. IEEE, 2018.
TRI Authors: Muratahan Aykol, Santosh Suram
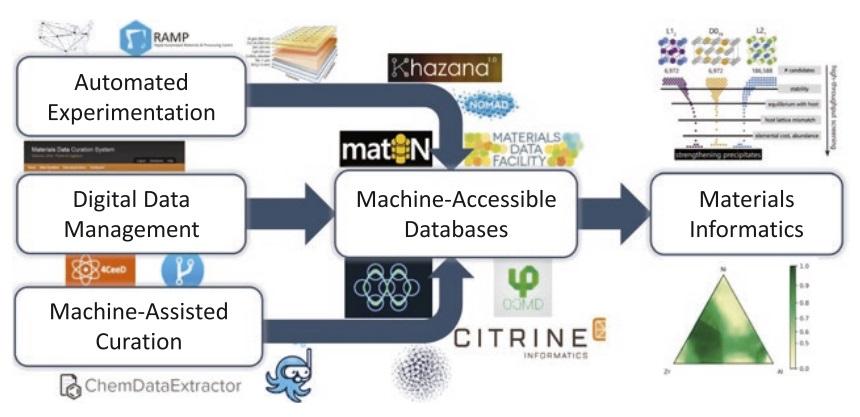
All Authors: Logan Ward, Muratahan Aykol, Ben Blaiszik, Ian Foster, Bryce Meredig, James Saal, Santosh Suram Ongoing, rapid innovations in fields ranging from microelectronics, aerospace, and automotive to defense, energy, and health demand new advanced materials at even greater rates and lower costs. Traditional materials R&D methods offer few paths to achieve both outcomes simultaneously. Materials informatics, while a nascent field, offers such a promise through screening, growing databases of materials for new applications, learning new relationships from existing data resources, and building fast predictive models. We highlight key materials informatics successes from the atomic-scale modeling community, and discuss the ecosystem of open data, software, services, and infrastructure that have led to broad adoption of materials informatics approaches. We then examine emerging opportunities for informatics in materials science and describe an ideal data ecosystem capable of supporting similar widespread adoption of materials informatics, which we believe will enable the faster design of materials. Read More
Citation: Ward, Logan, Muratahan Aykol, Ben Blaiszik, Ian Foster, Bryce Meredig, James Saal, and Santosh Suram. "Strategies for accelerating the adoption of materials informatics." MRS Bulletin 43, no. 9 (2018): 683-689.
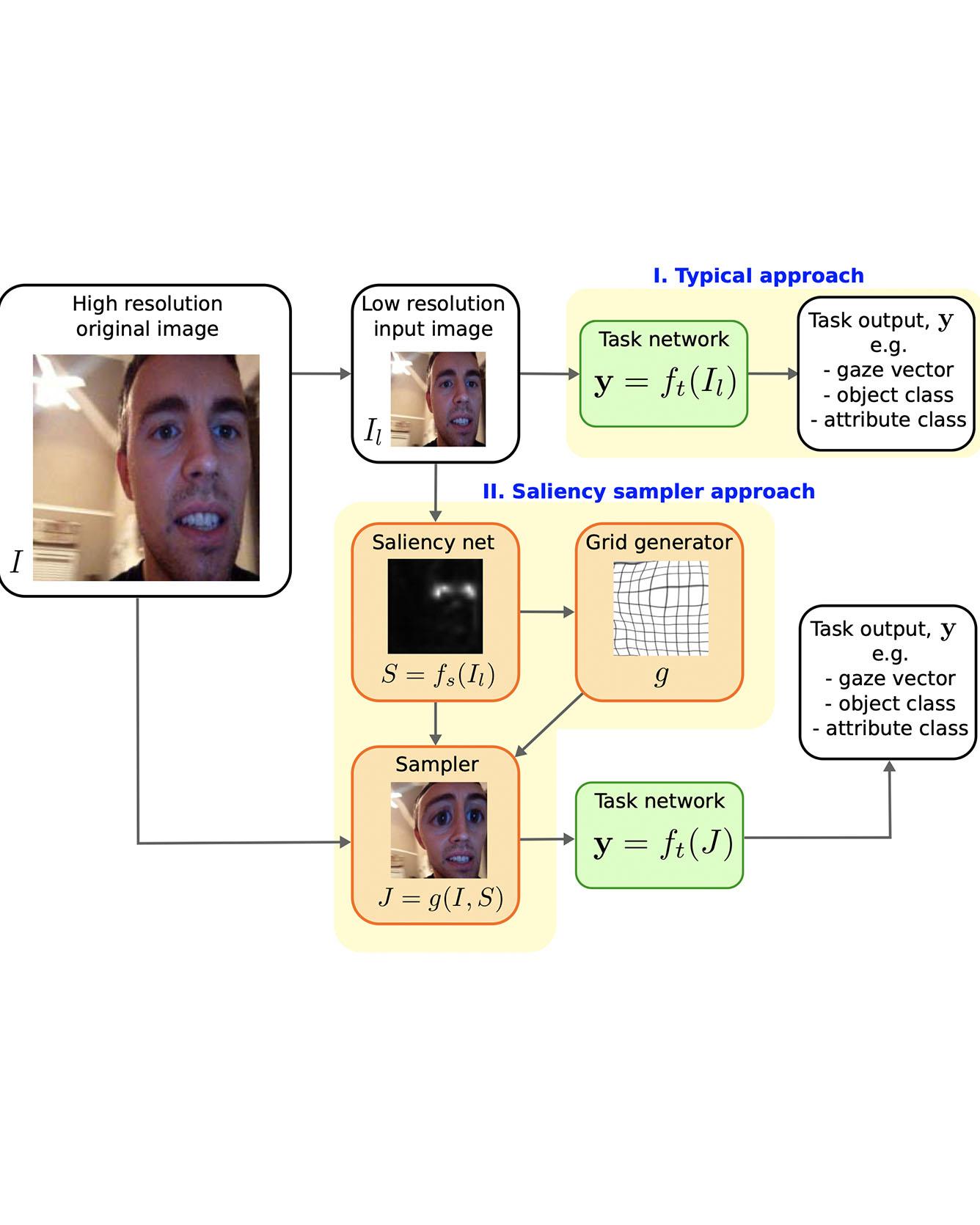
TRI Author: Simon Stent All Authors: Recasens, Adria, Petr Kellnhofer, Simon Stent, Wojciech Matusik, and Antonio Torralba
We introduce a saliency-based distortion layer for convolutional neural networks that helps to improve the spatial sampling of input data for a given task. Our differentiable layer can be added as a preprocessing block to existing task networks and trained altogether in an end-to-end fashion. The effect of the layer is to efficiently estimate how to sample from the original data in order to boost task performance. For example, for an image classification task in which the original data might range in size up to several megapixels, but where the desired input images to the task network are much smaller, our layer learns how best to sample from the underlying high resolution data in a manner which preserves task-relevant information better than uniform downsampling. This has the effect of creating distorted, caricature-like intermediate images, in which idiosyncratic elements of the image that improve task performance are zoomed and exaggerated. Unlike alternative approaches such as spatial transformer networks, our proposed layer is inspired by image saliency, computed efficiently from uniformly downsampled data, and degrades gracefully to a uniform sampling strategy under uncertainty. We apply our layer to improve existing networks for the tasks of human gaze estimation and fine-grained object classification. Code for our method is available in: http://github.com/recasens/Saliency-Sampler. Read More
Citation: Recasens, Adria, Petr Kellnhofer, Simon Stent, Wojciech Matusik, and Antonio Torralba. "Learning to zoom: a saliency-based sampling layer for neural networks." In Proceedings of the European Conference on Computer Vision (ECCV), pp. 51-66. 2018.
TRI Author: Wadim Kehl
All Authors: Fabian Manhardt, Wadim Kehl, Nassir Navab, Federico Tombari
We present a novel approach for model-based 6D pose refinement in color data. Building on the established idea of contour-based pose tracking, we teach a deep neural network to predict a translational and rotational update. At the core, we propose a new visual loss that drives the pose update by aligning object contours, thus avoiding the definition of any explicit appearance model. In contrast to previous work our method is correspondence-free, segmentation-free, can handle occlusion and is agnostic to geometrical symmetry as well as visual ambiguities. Additionally, we observe a strong robustness towards rough initialization. The approach can run in real-time and produces pose accuracies that come close to 3D ICP without the need for depth data. Furthermore, our networks are trained from purely synthetic data and will be published together with the refinement code to ensure reproducibility. Read More
Citation: Manhardt, Fabian, Wadim Kehl, Nassir Navab, and Federico Tombari. "Deep model-based 6d pose refinement in rgb." In Proceedings of the European Conference on Computer Vision (ECCV), pp. 800-815. 2018.
