Featured Publications
All Publications
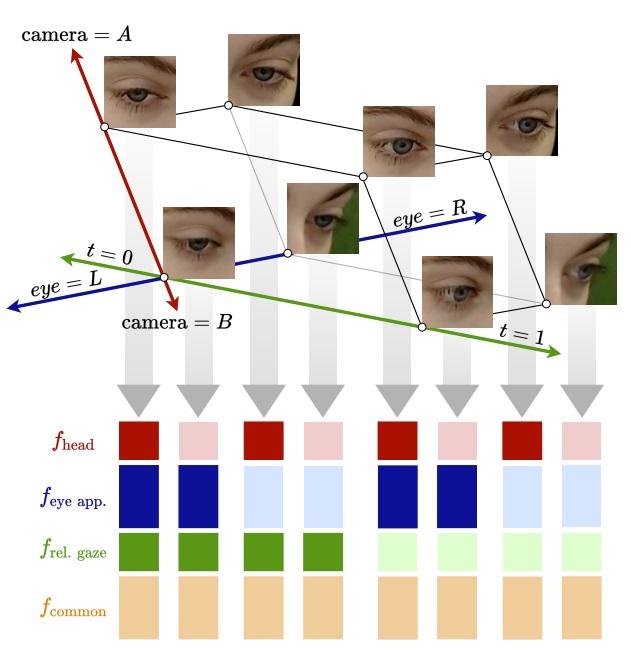
We present a method for unsupervised gaze representation learning from multiple synchronized views of a person's face. The key assumption is that images of the same eye captured from different viewpoints differ in certain respects while remaining similar in others. Specifically, the absolute gaze and absolute head pose of the same subject should be different from different viewpoints, while appearance characteristics and gaze angle relative to the head coordinate frame should remain constant. To leverage this, we adopt a cross-encoder learning framework, in which our encoding space consists of head pose, relative eye gaze, eye appearance and other common features. Image pairs which are assumed to have matching subsets of features should be able to swap those subsets among themselves without any loss of information, computed by decoding the mixed features back into images and measuring reconstruction loss. We show that by applying these assumptions to an unlabelled multi-view video dataset, we can generate more powerful representations than a standard gaze cross-encoder for few-shot gaze estimation. Furthermore, we introduce a new feature-mixing method which results in higher performance, faster training, improved testing flexibility with multiple views, and added interpretability with learned confidence. READ MORE
The growing field of data-driven materials research poses a challenge to educators: teaching machine learning to materials scientists. We share our recent experiences and lessons learnt from organizing educational sessions at the fall 2021 meeting of the Materials Research Society. READ MORE

When predicting trajectories of road agents, motion predictors usually approximate the future distribution by a limited number of samples. This constraint requires the predictors to generate samples that best support the task given task specifications. However, existing predictors are often optimized and evaluated via task-agnostic measures without accounting for the use of predictions in downstream tasks, and thus could result in sub-optimal task performance.
In this paper, we propose a task-informed motion prediction model that better supports the tasks through its predictions, by jointly reasoning about prediction accuracy and the utility of the downstream tasks, which is commonly used to evaluate the task performance. The task utility function does not require the full task information, but rather a specification of the utility of the task, resulting in predictors that serve a wide range of downstream tasks. We demonstrate our approach on two use cases of common decision making tasks and their utility functions, in the context of autonomous driving and parallel autonomy. Experiment results show that our predictor produces accurate predictions that improve the task performance by a large margin in both tasks when compared to task-agnostic baselines on the Waymo Open Motion dataset. READ MORE
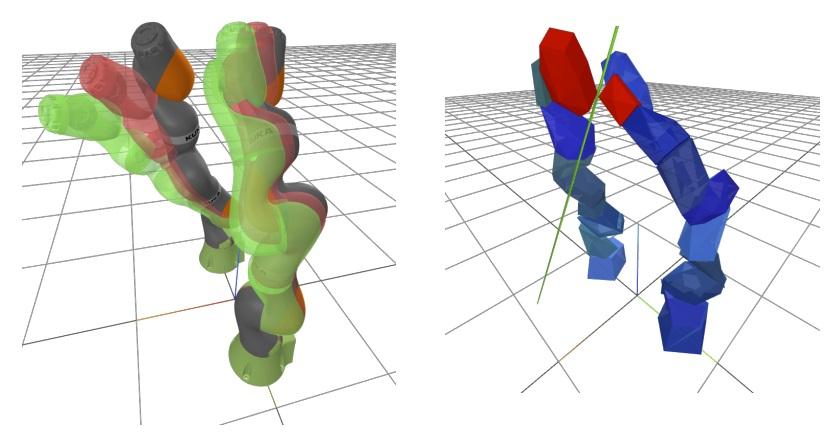
Configuration space (C-space) has played a central role in collision-free motion planning, particularly for robot manipulators. While it is possible to check for collisions at a point using standard algorithms, to date no practical method exists for computing collision-free C-space regions with rigorous certificates due to the complexities of mapping task-space obstacles through the kinematics. In this work, we present the first to our knowledge method for generating such regions and certificates through convex optimization. Our method, called C-Iris (C-space Iterative Regional Inflation by Semidefinite programming), generates large, convex polytopes in a rational parametrization of the configuration space which are guaranteed to be collision-free. Such regions have been shown to be useful for both optimization-based and randomized motion planning. Our regions are generated by alternating between two convex optimization problems: (1) a simultaneous search for a maximal-volume ellipse inscribed in a given polytope and a certificate that the polytope is collision-free and (2) a maximal expansion of the polytope away from the ellipse which does not violate the certificate. The volume of the ellipse and size of the polytope are allowed to grow over several iterations while being collision-free by construction. Our method works in arbitrary dimensions, only makes assumptions about the convexity of the obstacles in the task space, and scales to realistic problems in manipulation. We demonstrate our algorithm's ability to fill a non-trivial amount of collision-free C-space in a 3-DOF example where the C-space can be visualized, as well as the scalability of our algorithm on a 7-DOF KUKA iiwa and a 12-DOF bimanual manipulator. READ MORE
People consider recommendations from AI systems in diverse domains ranging from recognizing tumors in medical images to deciding which shoes look cute with an outfit. Implicit in the decision process is the perceived expertise of the AI system. In this paper, we investigate how people trust and rely on an AI assistant that performs with different levels of expertise relative to the person, ranging from completely overlapping expertise to perfectly complementary expertise. Through a series of controlled online lab studies where participants identified objects with the help of an AI assistant, we demonstrate that participants were able to perceive when the assistant was an expert or non-expert within the same task and calibrate their reliance on the AI to improve team performance. We also demonstrate that communicating expertise through the linguistic properties of the explanation text was effective, where embracing language increased reliance and distancing language reduced reliance on AI. READ MORE

Autonomous vehicle software is typically structured as a modular pipeline of individual components (e.g., perception, prediction, and planning) to help separate concerns into interpretable sub-tasks. Even when end-to-end training is possible, each module has its own set of objectives used for safety assurance, sample efficiency, regularization, or interpretability. However, intermediate objectives do not always align with overall system performance. For example, optimizing the likelihood of a trajectory prediction module might focus more on easy-to-predict agents than safety-critical or rare behaviors (e.g., jaywalking). In this paper, we present control-aware prediction objectives (CAPOs), to evaluate the downstream effect of predictions on control without requiring the planner be differentiable. We propose two types of importance weights that weight the predictive likelihood: one using an attention model between agents, and another based on control variation when exchanging predicted trajectories for ground truth trajectories. Experimentally, we show our objectives improve overall system performance in suburban driving scenarios using the CARLA simulator. READ MORE

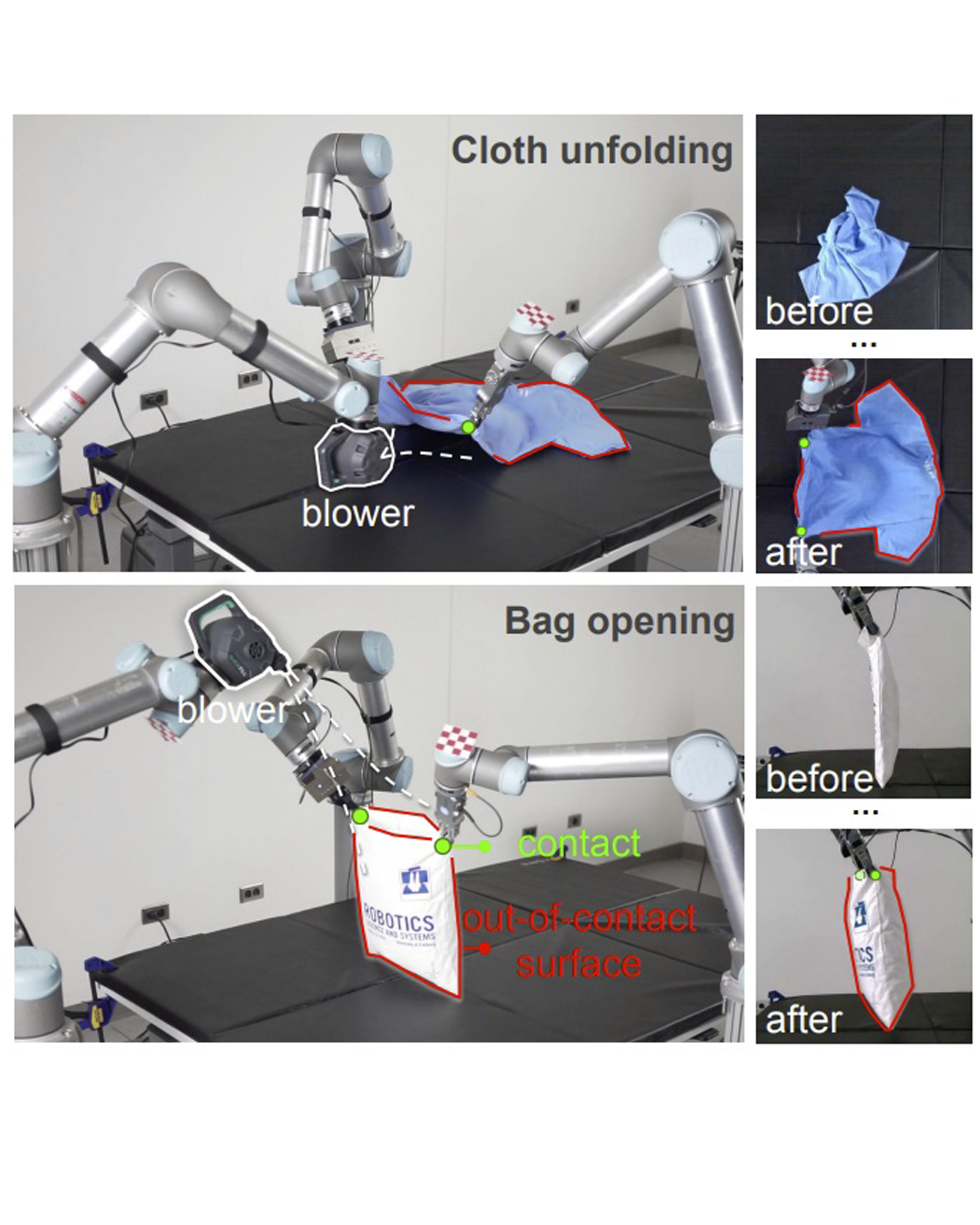
This paper introduces DextAIRity, an approach to manipulate deformable objects using active airflow. In contrast to conventional contact-based quasi-static manipulations, DextAIRity allows the system to apply dense forces on out-of-contact surfaces, expands the system's reach range, and provides safe high-speed interactions. These properties are particularly advantageous when manipulating under-actuated deformable objects with large surface areas or volumes. We demonstrate the effectiveness of DextAIRity through two challenging deformable object manipulation tasks: cloth unfolding and bag opening. We present a self-supervised learning framework that learns to effectively perform a target task through a sequence of grasping or air-based blowing actions. By using a closed-loop formulation for blowing, the system continuously adjusts its blowing direction based on visual feedback in a way that is robust to the highly stochastic dynamics. We deploy our algorithm on a real-world three-arm system and present evidence suggesting that DextAIRity can improve system efficiency for challenging deformable manipulation tasks, such as cloth unfolding, and enable new applications that are impractical to solve with quasi-static contact-based manipulations (e.g., bag opening). READ MORE
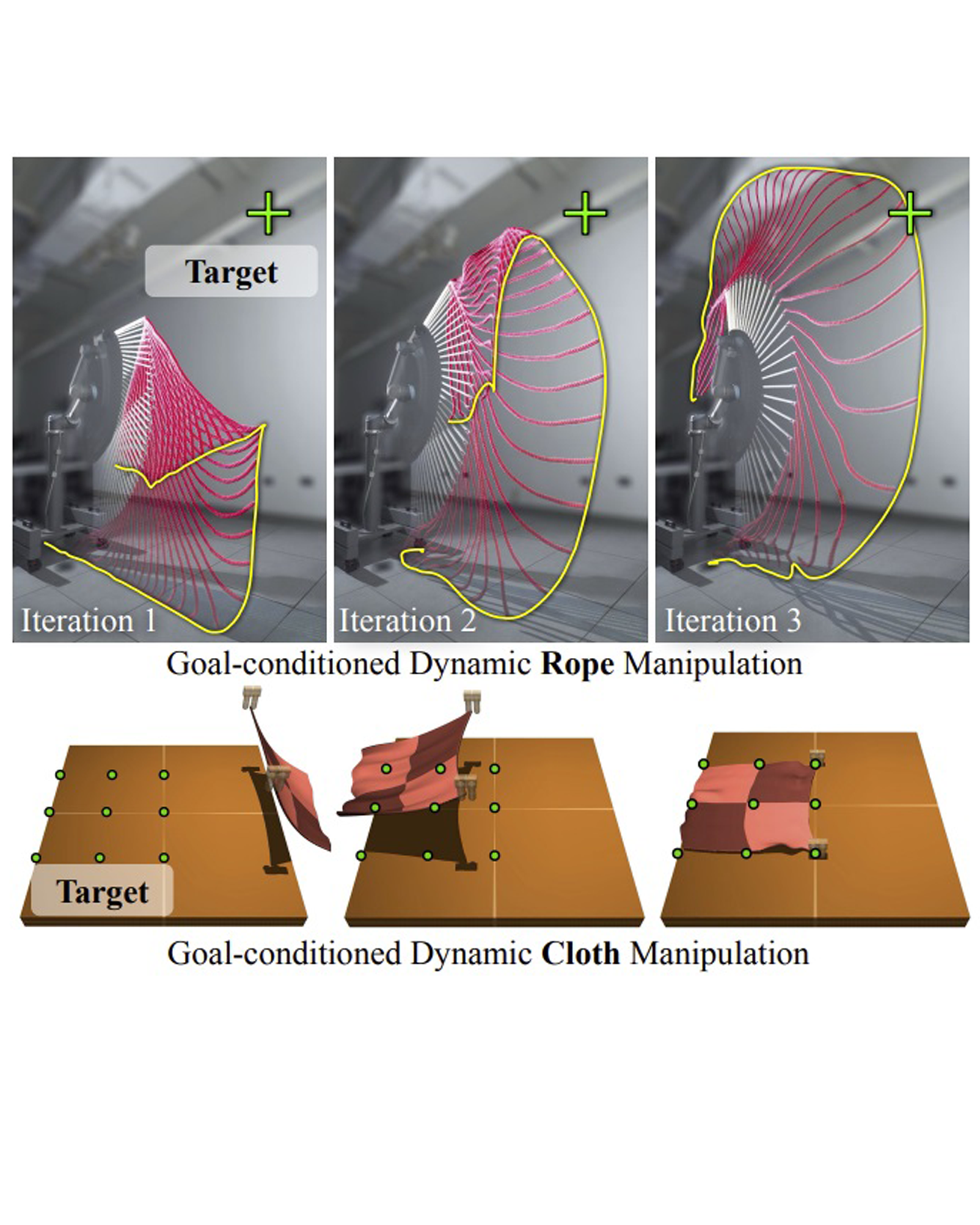
This paper tackles the task of goal-conditioned dynamic manipulation of deformable objects. This task is highly challenging due to its complex dynamics (introduced by object deformation and high-speed action) and strict task requirements (defined by a precise goal specification). To address these challenges, we present Iterative Residual Policy (IRP), a general learning framework applicable to repeatable tasks with complex dynamics. IRP learns an implicit policy via delta dynamics -- instead of modeling the entire dynamical system and inferring actions from that model, IRP learns delta dynamics that predict the effects of delta action on the previously-observed trajectory. When combined with adaptive action sampling, the system can quickly optimize its actions online to reach a specified goal. We demonstrate the effectiveness of IRP on two tasks: whipping a rope to hit a target point and swinging a cloth to reach a target pose. Despite being trained only in simulation on a fixed robot setup, IRP is able to efficiently generalize to noisy real-world dynamics, new objects with unseen physical properties, and even different robot hardware embodiments, demonstrating its excellent generalization capability relative to alternative approaches. READ MORE
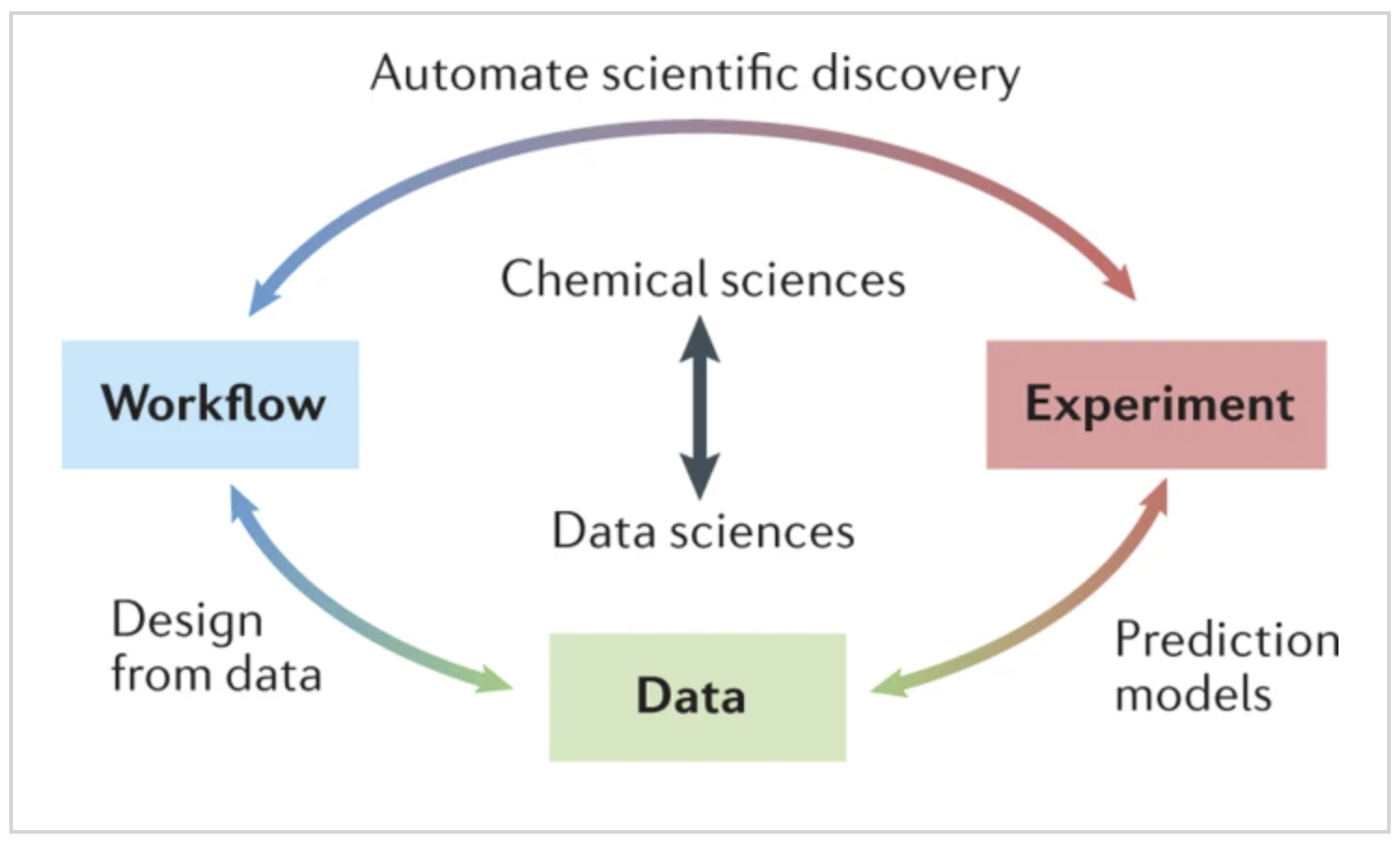
The physical sciences community is increasingly taking advantage of the possibilities offered by modern data science to solve problems in experimental chemistry and potentially to change the way we design, conduct and understand results from experiments. Successfully exploiting these opportunities involves considerable challenges. In this Expert Recommendation, we focus on experimental co-design and its importance to experimental chemistry. We provide examples of how data science is changing the way we conduct experiments, and we outline opportunities for further integration of data science and experimental chemistry to advance these fields. Our recommendations include establishing stronger links between chemists and data scientists; developing chemistry-specific data science methods; integrating algorithms, software and hardware to ‘co-design’ chemistry experiments from inception; and combining diverse and disparate data sources into a data network for chemistry research. READ MORE
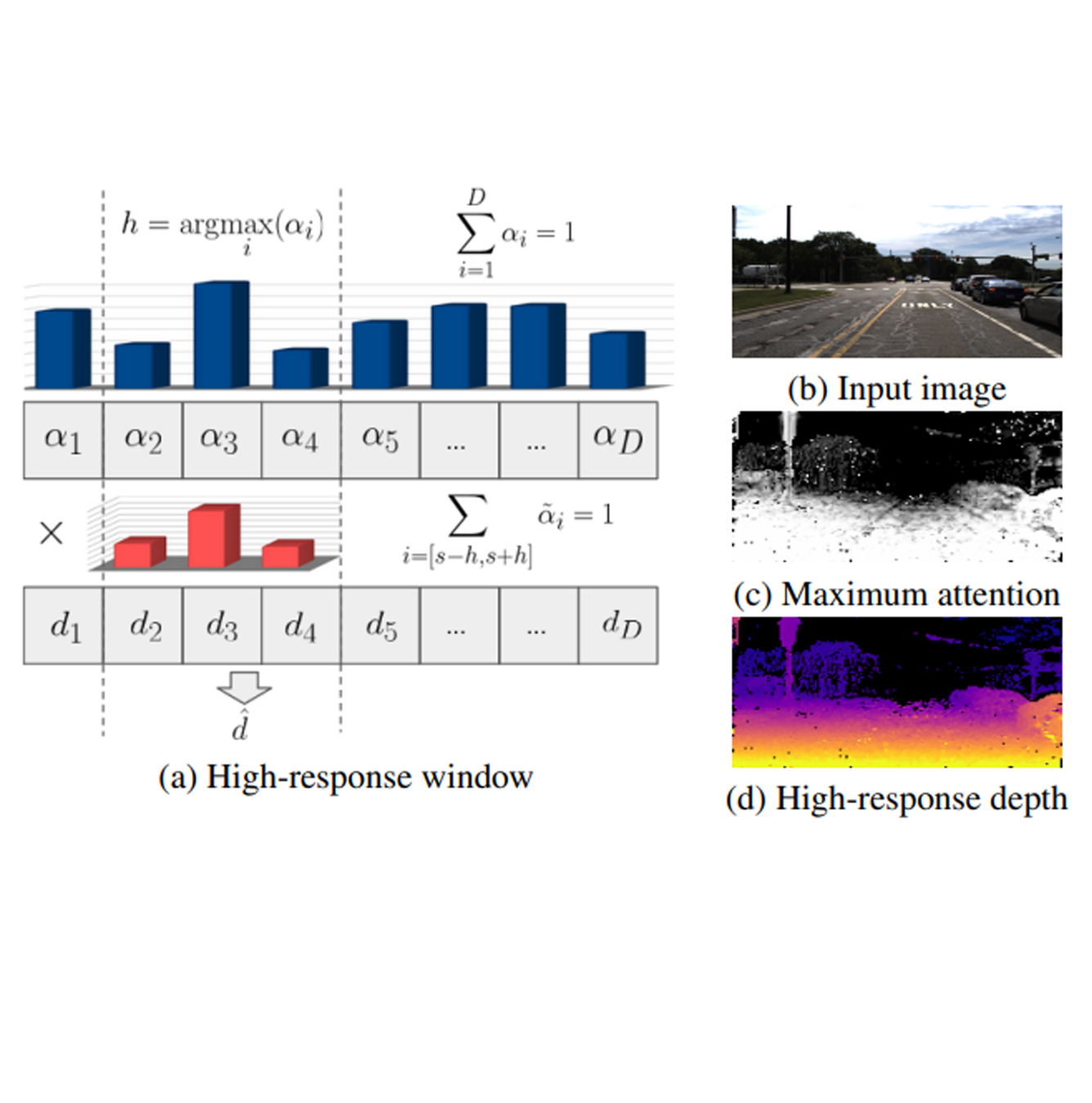
Multi-frame depth estimation improves over single-frame approaches by also leveraging geometric relationships between images via feature matching, in addition to learning appearance-based features. In this paper we revisit feature matching for self-supervised monocular depth estimation, and propose a novel transformer architecture for cost volume generation. We use depth-discretized epipolar sampling to select matching candidates, and refine predictions through a series of self- and cross-attention layers. These layers sharpen the matching probability between pixel features, improving over standard similarity metrics prone to ambiguities and local minima. The refined cost volume is decoded into depth estimates, and the whole pipeline is trained end-to-end from videos using only a photometric objective. Experiments on the KITTI and DDAD datasets show that our DepthFormer architecture establishes a new state of the art in self-supervised monocular depth estimation, and is even competitive with highly specialized supervised single-frame architectures. We also show that our learned cross-attention network yields representations transferable across datasets, increasing the effectiveness of pre-training strategies. READ MORE