
Featured Publications
All Publications
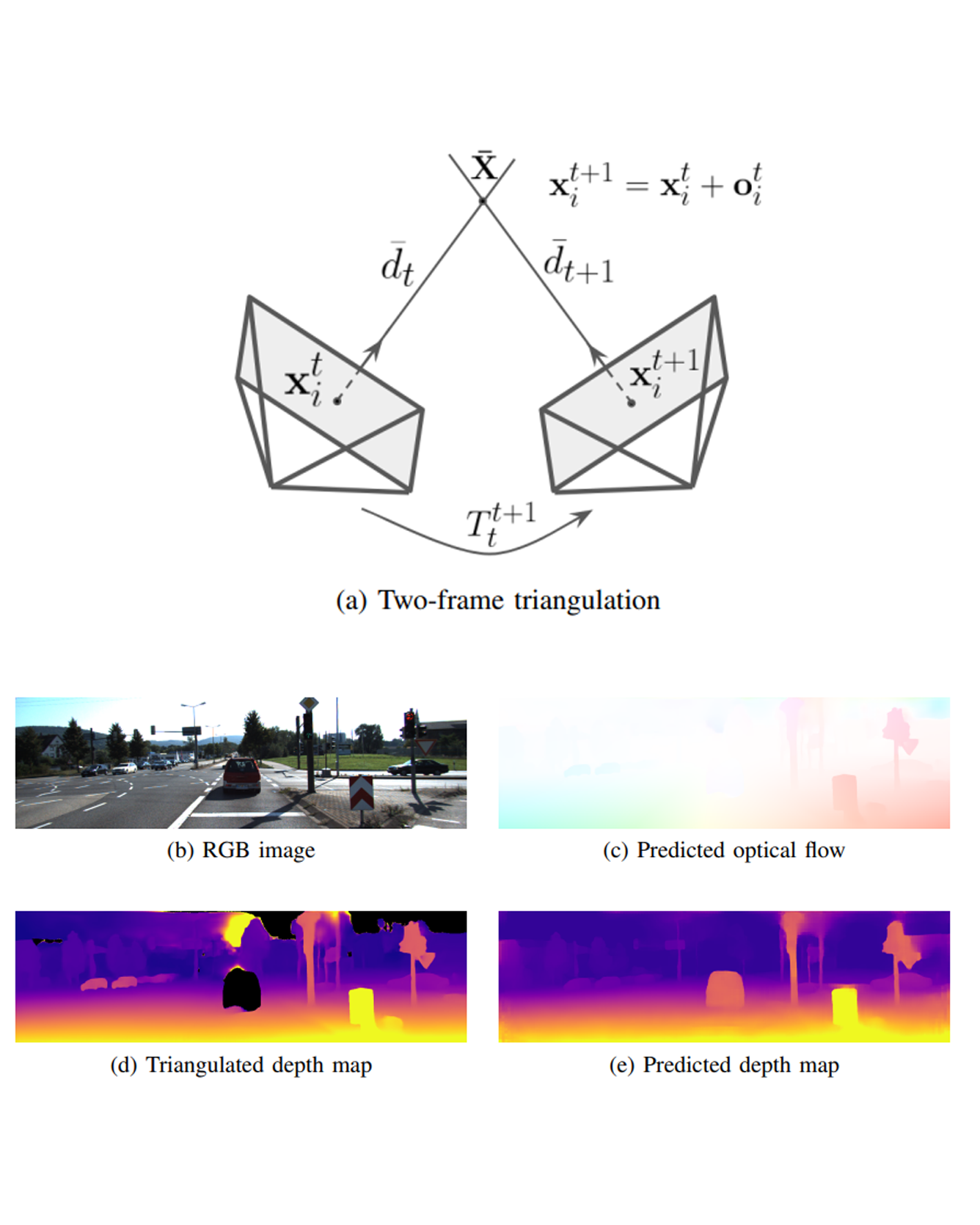
Self-supervised monocular depth estimation enables robots to learn 3D perception from raw video streams. This scalable approach leverages projective geometry and ego-motion to learn via view synthesis, assuming the world is mostly static. Dynamic scenes, which are common in autonomous driving and human-robot interaction, violate this assumption. Therefore, they require modeling dynamic objects explicitly, for instance via estimating pixel-wise 3D motion, i.e. scene flow. However, the simultaneous self-supervised learning of depth and scene flow is ill-posed, as there are infinitely many combinations that result in the same 3D point. In this paper we propose DRAFT, a new method capable of jointly learning depth, optical flow, and scene flow by combining synthetic data with geometric self-supervision. Building upon the RAFT architecture, we learn optical flow as an intermediate task to bootstrap depth and scene flow learning via triangulation. Our algorithm also leverages temporal and geometric consistency losses across tasks to improve multi-task learning. Our DRAFT architecture simultaneously establishes a new state of the art in all three tasks in the self-supervised monocular setting on the standard KITTI benchmark. READ MORE
This paper studies the problem of object discovery -- separating objects from the background without manual labels. Existing approaches utilize appearance cues, such as color, texture, and location, to group pixels into object-like regions. However, by relying on appearance alone, these methods fail to separate objects from the background in cluttered scenes. This is a fundamental limitation since the definition of an object is inherently ambiguous and context-dependent. To resolve this ambiguity, we choose to focus on dynamic objects -- entities that can move independently in the world. We then scale the recent auto-encoder based frameworks for unsupervised object discovery from toy synthetic images to complex real-world scenes. To this end, we simplify their architecture, and augment the resulting model with a weak learning signal from general motion segmentation algorithms. Our experiments demonstrate that, despite only capturing a small subset of the objects that move, this signal is enough to generalize to segment both moving and static instances of dynamic objects. We show that our model scales to a newly collected, photo-realistic synthetic dataset with street driving scenarios. Additionally, we leverage ground truth segmentation and flow annotations in this dataset for thorough ablation and evaluation. Finally, our experiments on the real-world KITTI benchmark demonstrate that the proposed approach outperforms both heuristic- and learning-based methods by capitalizing on motion cues. READ MORE

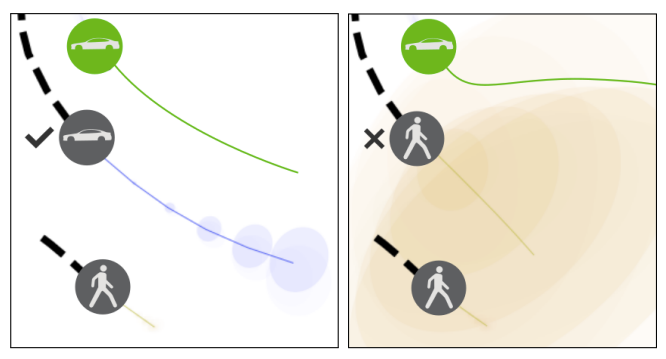
Reasoning about the future behavior of other agents is critical to safe robot navigation. The multiplicity of plausible futures is further amplified by the uncertainty inherent to agent state estimation from data, including positions, velocities, and semantic class. Forecasting methods, however, typically neglect class uncertainty, conditioning instead only on the agent's most likely class, even though perception models often return full class distributions. To exploit this information, we present HAICU, a method for heterogeneous-agent trajectory forecasting that explicitly incorporates agents' class probabilities. We additionally present PUP, a new challenging real-world autonomous driving dataset, to investigate the impact of Perceptual Uncertainty in Prediction. It contains challenging crowded scenes with unfiltered agent class probabilities that reflect the long-tail of current state-of-the-art perception systems. We demonstrate that incorporating class probabilities in trajectory forecasting significantly improves performance in the face of uncertainty, and enables new forecasting capabilities such as counterfactual predictions. READ MORE
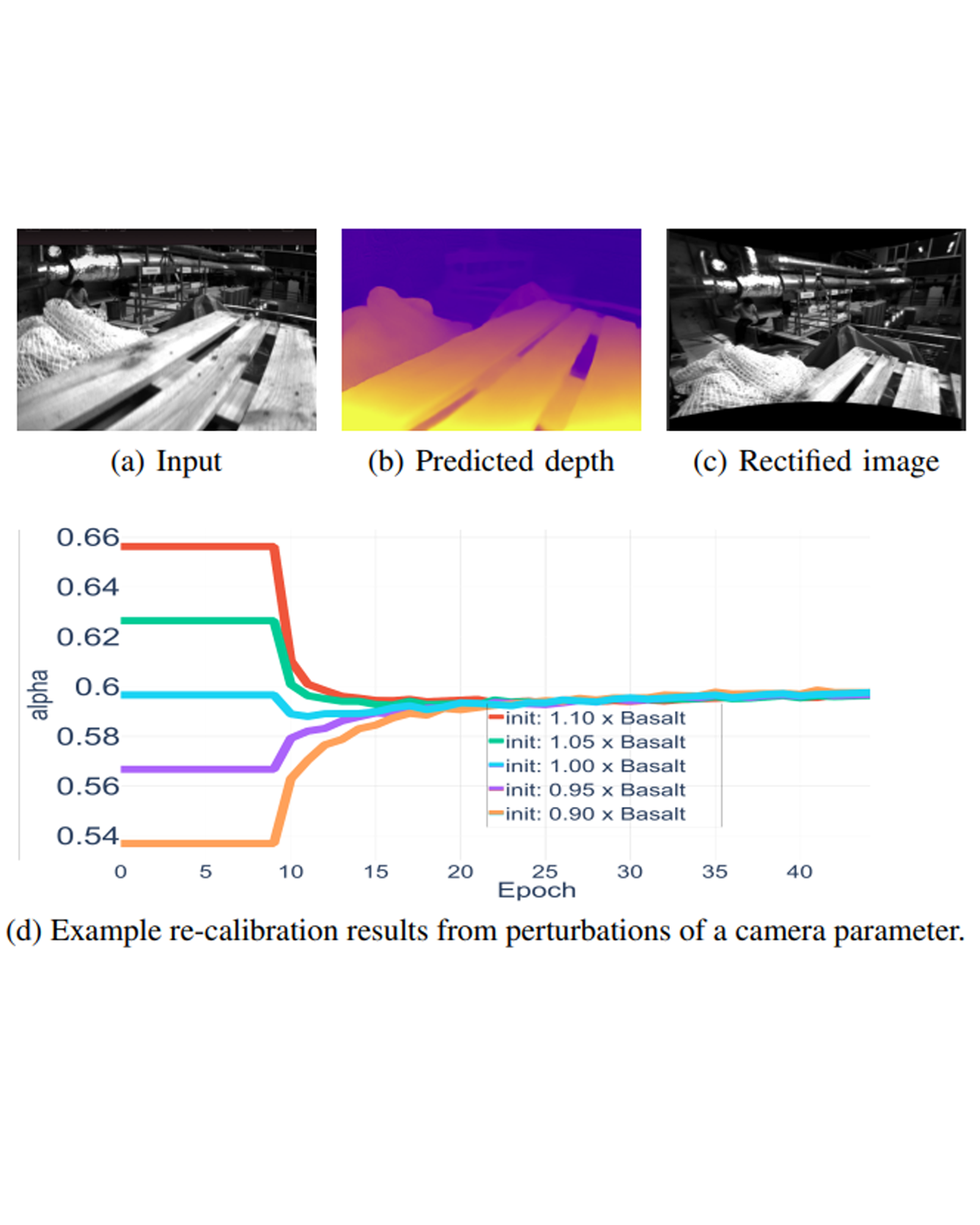
Camera calibration is integral to robotics and computer vision algorithms that seek to infer geometric properties of the scene from visual input streams. In practice, calibration is a laborious procedure requiring specialized data collection and careful tuning. This process must be repeated whenever the parameters of the camera change, which can be a frequent occurrence for mobile robots and autonomous vehicles. In contrast, self-supervised depth and ego-motion estimation approaches can bypass explicit calibration by inferring per-frame projection models that optimize a view synthesis objective. In this paper, we extend this approach to explicitly calibrate a wide range of cameras from raw videos in the wild. We propose a learning algorithm to regress per-sequence calibration parameters using an efficient family of general camera models. Our procedure achieves self-calibration results with sub-pixel reprojection error, outperforming other learning-based methods. We validate our approach on a wide variety of camera geometries, including perspective, fisheye, and catadioptric. Finally, we show that our approach leads to improvements in the downstream task of depth estimation, achieving state-of-the-art results on the EuRoC dataset with greater computational efficiency than contemporary methods. READ MORE
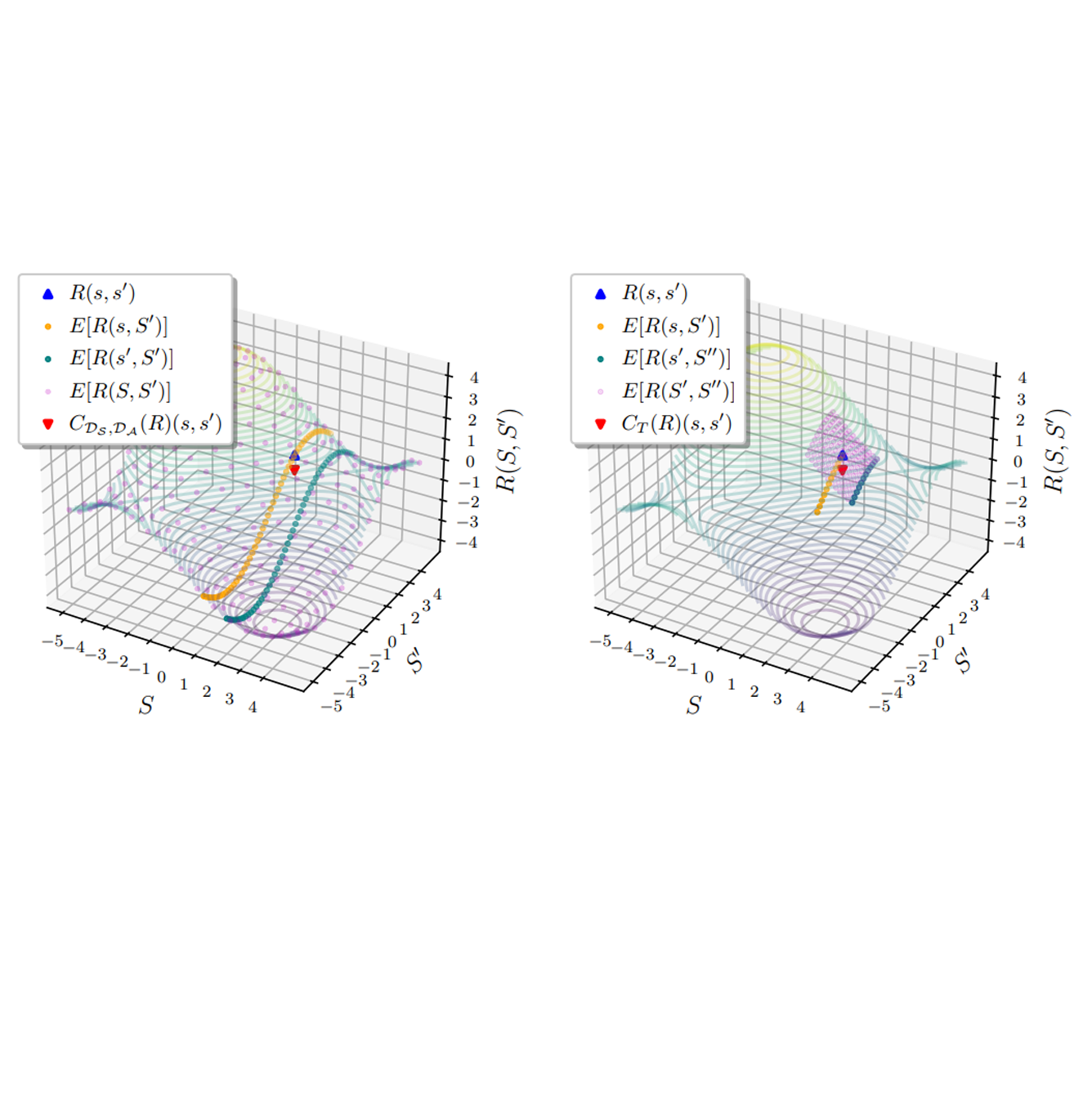
The ability to learn reward functions plays an important role in enabling the deployment of intelligent agents in the real world. However, comparing reward functions, for example as a means of evaluating reward learning methods, presents a challenge. Reward functions are typically compared by considering the behavior of optimized policies, but this approach conflates deficiencies in the reward function with those of the policy search algorithm used to optimize it. To address this challenge, Gleave et al. (2020) propose the Equivalent-Policy Invariant Comparison (EPIC) distance. EPIC avoids policy optimization, but in doing so requires computing reward values at transitions that may be impossible under the system dynamics. This is problematic for learned reward functions because it entails evaluating them outside of their training distribution, resulting in inaccurate reward values that we show can render EPIC ineffective at comparing rewards. To address this problem, we propose the Dynamics-Aware Reward Distance (DARD), a new reward pseudometric. DARD uses an approximate transition model of the environment to transform reward functions into a form that allows for comparisons that are invariant to reward shaping while only evaluating reward functions on transitions close to their training distribution. Experiments in simulated physical domains demonstrate that DARD enables reliable reward comparisons without policy optimization and is significantly more predictive than baseline methods of downstream policy performance when dealing with learned reward functions. READ MORE
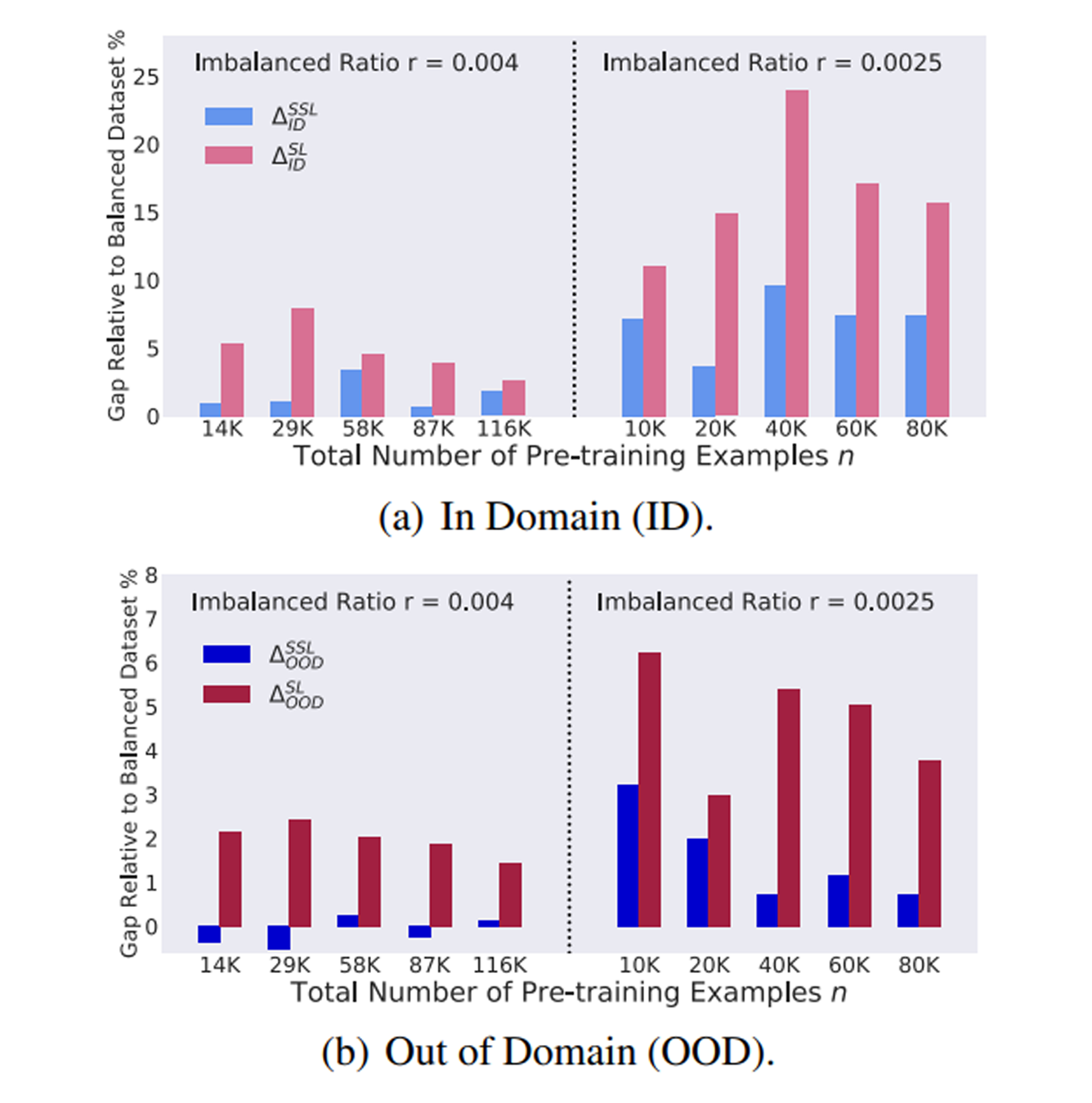
Self-supervised learning (SSL) is a scalable way to learn general visual representations since it learns without labels. However, large-scale unlabeled datasets in the wild often have long-tailed label distributions, where we know little about the behavior of SSL. In this work, we systematically investigate self-supervised learning under dataset imbalance. First, we find out via extensive experiments that off-the-shelf self-supervised representations are already more robust to class imbalance than supervised representations. The performance gap between balanced and imbalanced pre-training with SSL is significantly smaller than the gap with supervised learning, across sample sizes, for both in-domain and, especially, out-of-domain evaluation. Second, towards understanding the robustness of SSL, we hypothesize that SSL learns richer features from frequent data: it may learn label-irrelevant-but-transferable features that help classify the rare classes and downstream tasks. In contrast, supervised learning has no incentive to learn features irrelevant to the labels from frequent examples. We validate this hypothesis with semi-synthetic experiments and theoretical analyses on a simplified setting. Third, inspired by the theoretical insights, we devise a re-weighted regularization technique that consistently improves the SSL representation quality on imbalanced datasets with several evaluation criteria, closing the small gap between balanced and imbalanced datasets with the same number of examples. READ MORE
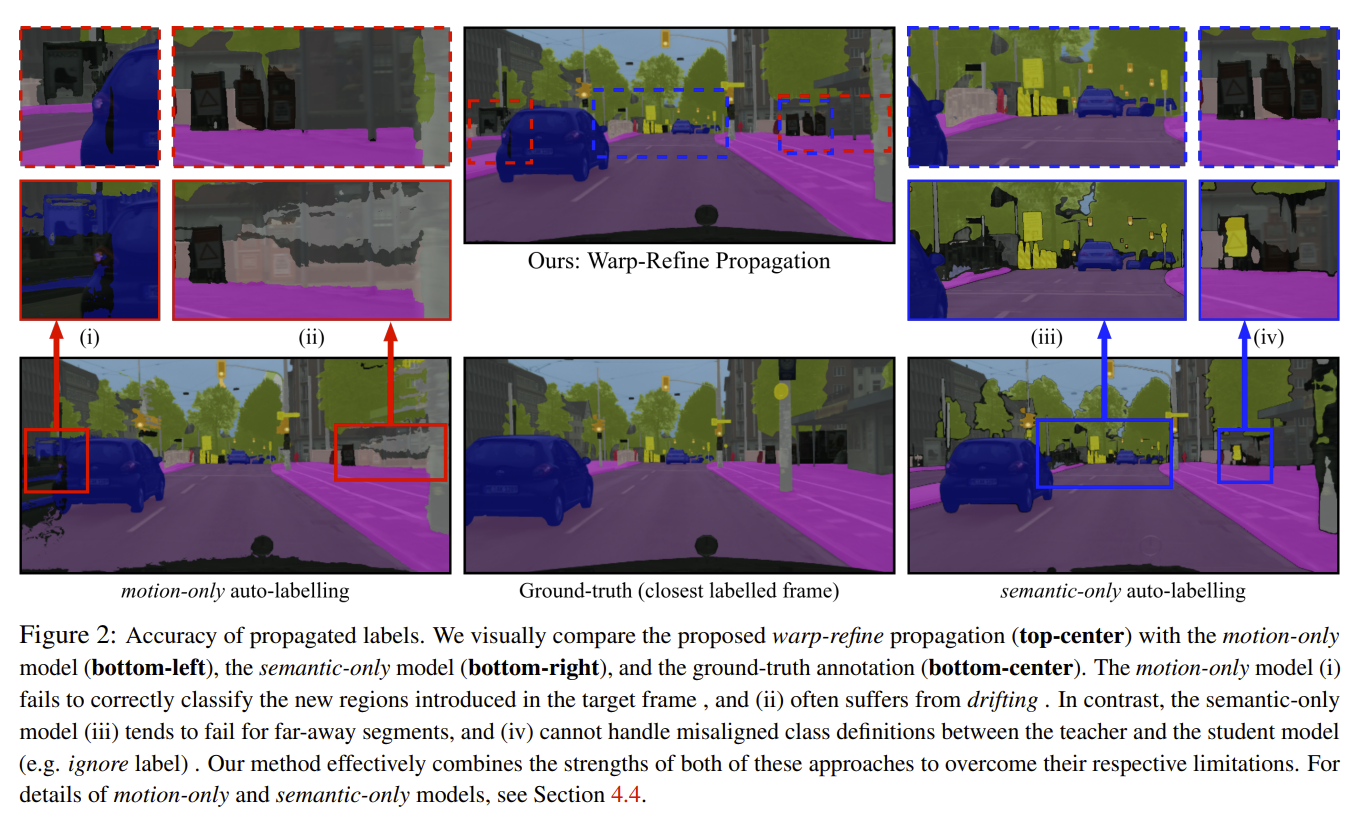
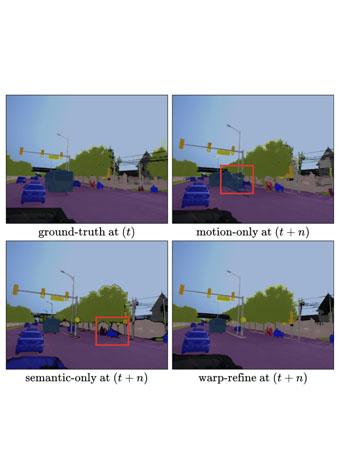
Deep learning models for semantic segmentation rely on expensive, large-scale, manually annotated datasets. Labelling is a tedious process that can take hours per image. Automatically annotating video sequences by propagating sparsely labeled frames through time is a more scalable alternative. In this work, we propose a novel label propagation method, termed Warp-Refine Propagation, that combines semantic cues with geometric cues to efficiently auto-label videos. Our method learns to refine geometrically-warped labels and infuse them with learned semantic priors in a semi-supervised setting by leveraging cycle consistency across time. We quantitatively show that our method improves label-propagation by a noteworthy margin of 13.1 mIoU on the ApolloScape dataset. Furthermore, by training with the auto-labelled frames, we achieve competitive results on three semantic-segmentation benchmarks, improving the state-of-the-art by a large margin of 1.8 and 3.61 mIoU on NYU-V2 and KITTI, while matching the current best results on Cityscapes. READ MORE
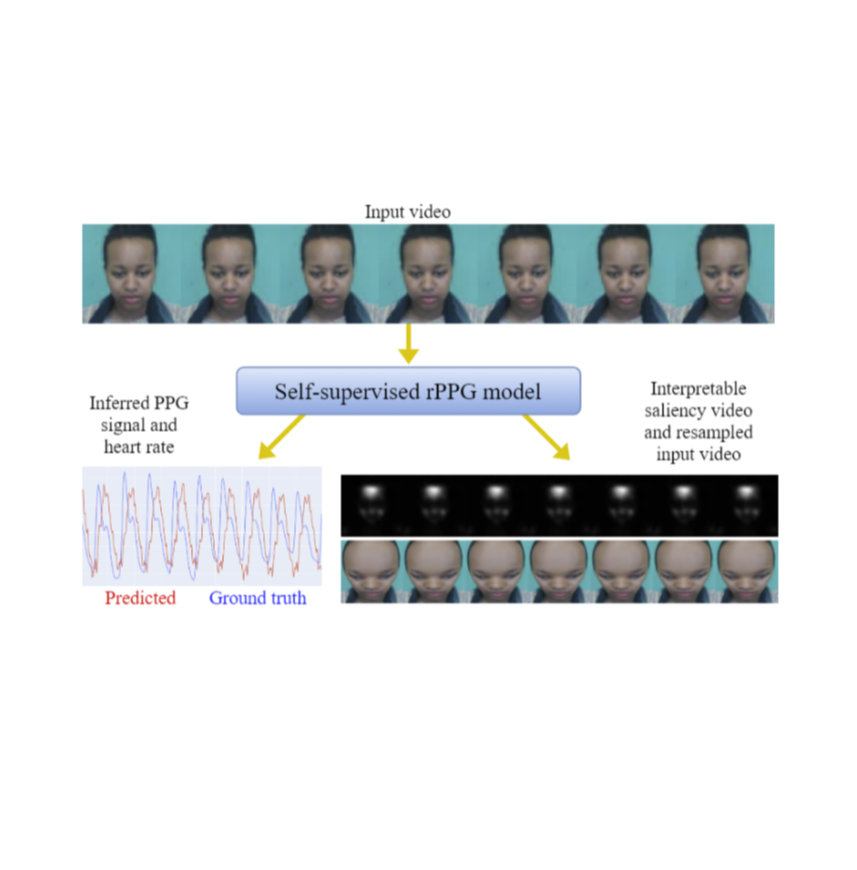
The ability to reliably estimate physiological signals from video is a powerful tool in low-cost, pre-clinical health monitoring. In this work we propose a new approach to remote photoplethysmography (rPPG) – the measurement of blood volume changes from observations of a person's face or skin. Similar to current state-of-the-art methods for rPPG, we apply neural networks to learn deep representations with invariance to nuisance image variation. In contrast to such methods, we employ a fully self-supervised training approach, which has no reliance on expensive ground truth physiological training data. Our proposed method uses contrastive learning with a weak prior over the frequency and temporal smoothness of the target signal of interest. We evaluate our approach on four rPPG datasets, showing that comparable or better results can be achieved compared to recent supervised deep learning methods but without using any annotation. In addition, we incorporate a learned saliency resampling module into both our unsupervised approach and supervised baseline. We show that by allowing the model to learn where to sample the input image, we can reduce the need for hand-engineered features while providing some interpretability into the model's behavior and possible failure modes. We release code for our complete training and evaluation pipeline to encourage reproducible progress in this exciting new direction. In addition, we used our proposed approach as the basis of our winning entry to the ICCV 2021 Vision 4 Vitals Workshop Challenge. READ MORE
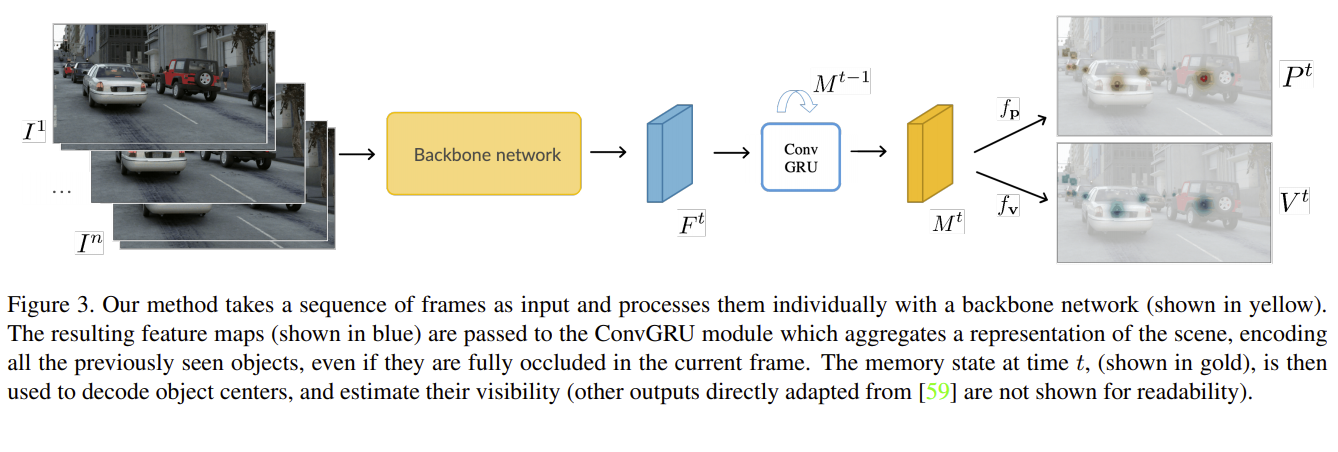
Tracking by detection, the dominant approach for online multi-object tracking, alternates between localization and re-identification steps. As a result, it strongly depends on the quality of instantaneous observations, often failing when objects are not fully visible. In contrast, tracking in humans is underlined by the notion of object permanence: once an object is recognized, we are aware of its physical existence and can approximately localize it even under full occlusions. In this work, we introduce an end-to-end trainable approach for joint object detection and tracking that is capable of such reasoning. We build on top of the recent CenterTrack architecture, which takes pairs of frames as input, and extend it to videos of arbitrary length. To this end, we augment the model with a spatio-temporal, recurrent memory module, allowing it to reason about object locations and identities in the current frame using all the previous history. It is, however, not obvious how to train such an approach. We study this question on a new, large-scale, synthetic dataset for multi-object tracking, which provides ground truth annotations for invisible objects, and propose several approaches for supervising tracking behind occlusions. Our model, trained jointly on synthetic and real data, outperforms the state of the art on KITTI, and MOT17 datasets thanks to its robustness to occlusions. READ MORE

Recent progress in 3D object detection from single images leverages monocular depth estimation as a way to produce 3D pointclouds, turning cameras into pseudo-lidar sensors. These two-stage detectors improve with the accuracy of the intermediate depth estimation network, which can itself be improved without manual labels via large-scale self-supervised learning. However, they tend to suffer from overfitting more than end-to-end methods, are more complex, and the gap with similar lidar-based detectors remains significant. In this work, we propose an end-to-end, single stage, monocular 3D object detector, DD3D, that can benefit from depth pre-training like pseudo-lidar methods, but without their limitations. Our architecture is designed for effective information transfer between depth estimation and 3D detection, allowing us to scale with the amount of unlabeled pre-training data. Our method achieves state-of-the-art results on two challenging benchmarks, with 16.34% and 9.28% AP for Cars and Pedestrians (respectively) on the KITTI-3D benchmark, and 41.5% mAP on NuScenes. READ MORE

