Featured Publications

All Publications
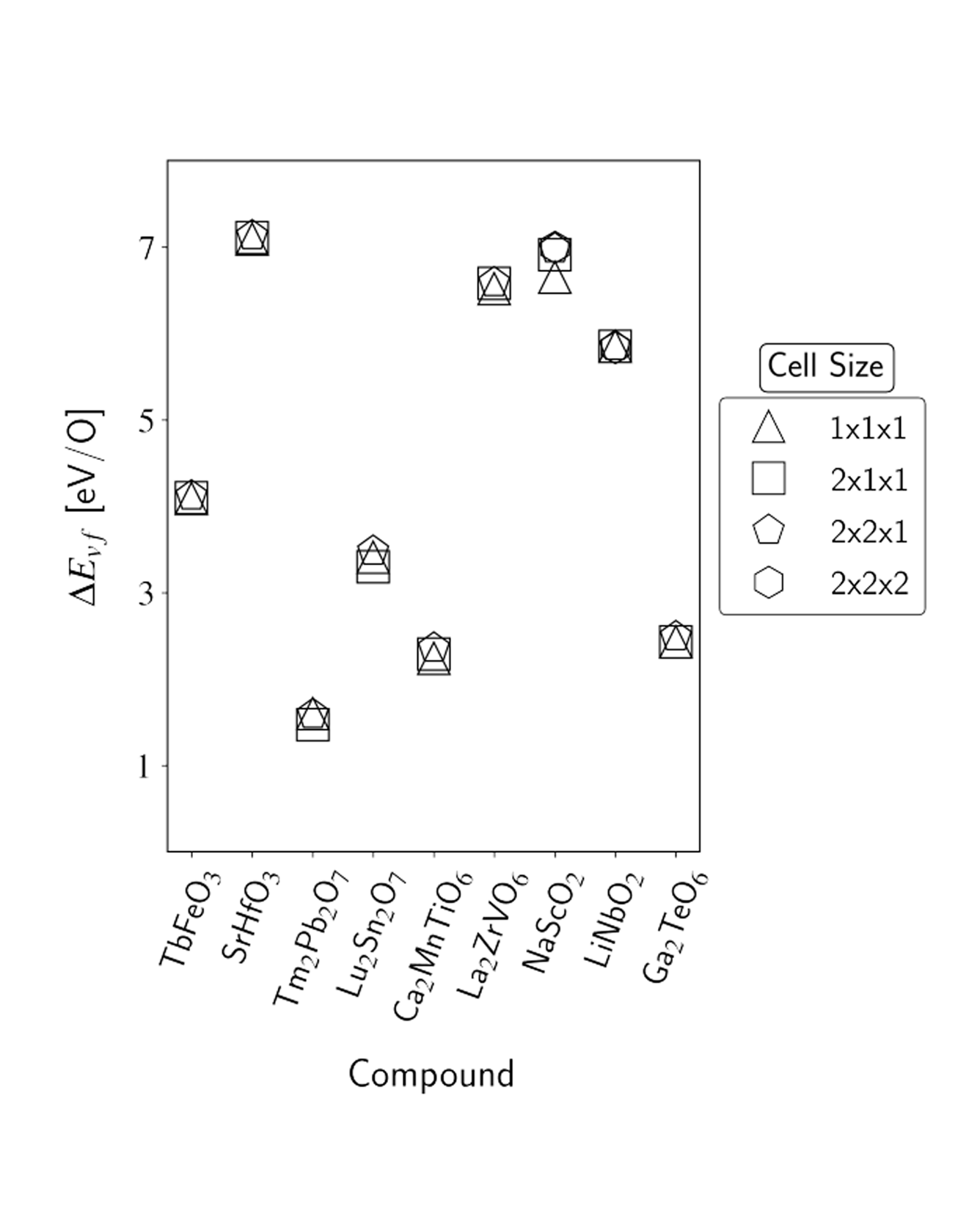
The oxygen vacancy formation energy (ΔEvf) governs defect concentrations alongside the entropy and is a useful metric to perform materials selection for a variety of applications. However, density functional theory (DFT) calculations of ΔEvf come at a greater computational cost than the typical bulk calculations available in materials databases due to the involvement of multiple vacancy-containing supercells. As a result, available repositories of direct calculations of ΔEvf remain relatively scarce, and the development of machine-learning models capable of delivering accurate predictions is of interest. In the present work, we address both such points. We first report the results of new high-throughput DFT calculations of oxygen vacancy formation energies of the different unique oxygen sites in over 1000 different oxide materials, with a large portion of the calculations, and of the discussion, focusing on perovskite-type and pyrochlore-type oxides. Together, the over 2500 ΔEvf calculations form the largest data set of directly computed oxygen vacancy formation energies to date, to our knowledge. We then utilize such a data set to train random forest models with different sets of features, examining both novel features introduced in this work and ones previously employed in the literature. We demonstrate the benefits of including features that contain information specific to the vacancy site and account for both cation identity and oxidation state and achieve a mean absolute error upon prediction of ∼0.3 eV/O, which is comparable to the accuracy observed upon comparison of DFT computations of oxygen vacancy formation energy and experimental results. Finally, we exemplify the predictive power of the developed models in the search for new compounds for solar-thermochemical water-splitting applications, finding over 250 new AA′BB′O6 double perovskite candidates. READ MORE
Automobile racing provides a unique and challenging environment for studying competitive multi-agent behavior. In creating autonomous racing agents, one consideration is the effect that modeling one’s opponents has on finding high-performance policies. In this paper, we study the overall effectiveness of opponent modeling in the context of autonomous racing, as well as the value of different information about one’s opponents. We propose a new approach for learning salient characteristics of one’s opponent: Learn Thy Enemy (LTE), an algorithmic framework that combines reinforcement learning with self-supervised learning about one’s opponents. We evaluate LTE against multiple baselines in a CARLA-based simulation of an actual major racetrack. The results demonstrate that LTE substantially outperforms baselines, showing LTE’s effectiveness in extracting relevant opponent information automatically during interactions with the aim of better accomplishing the task. READ MORE

Social group cohesion and social support are critical for positive mental health. People may use technology to maintain existing, or even create new, social groups – particularly when in-person contact is limited. During the global COVID-19 pandemic, countries mandated various stay-at-home orders; for many people worldwide, this was their first experience of extended periods of social isolation. To better understand the relationship of affinity for technology, group cohesion, and mental health depending on change in social isolation, we surveyed people based on country. We studied Italy because of its relatively large increase in social isolation, and we studied Japan because of its relatively small increase in social isolation. We surveyed participants about existing and new social groups in a country that strongly socially isolated (Study 1: Italy, n = 426) and one with few changes from normal (Study 2: Japan, n = 280). We collected data in June 2020, several months after the onset of the COVID-19 pandemic. Affinity for technology related to increased group cohesion and mental health depending on country and on whether groups were new or existing. Dimensions of group cohesion had varied effects on mental health. We synthesize results from this work and a prior study in the United States (U.S., n = 276), which had a very mixed approach to dealing with COVID-19 that differed from approaches in Italy and Japan. Finally, we discuss overall patterns across all three countries. READ MORE
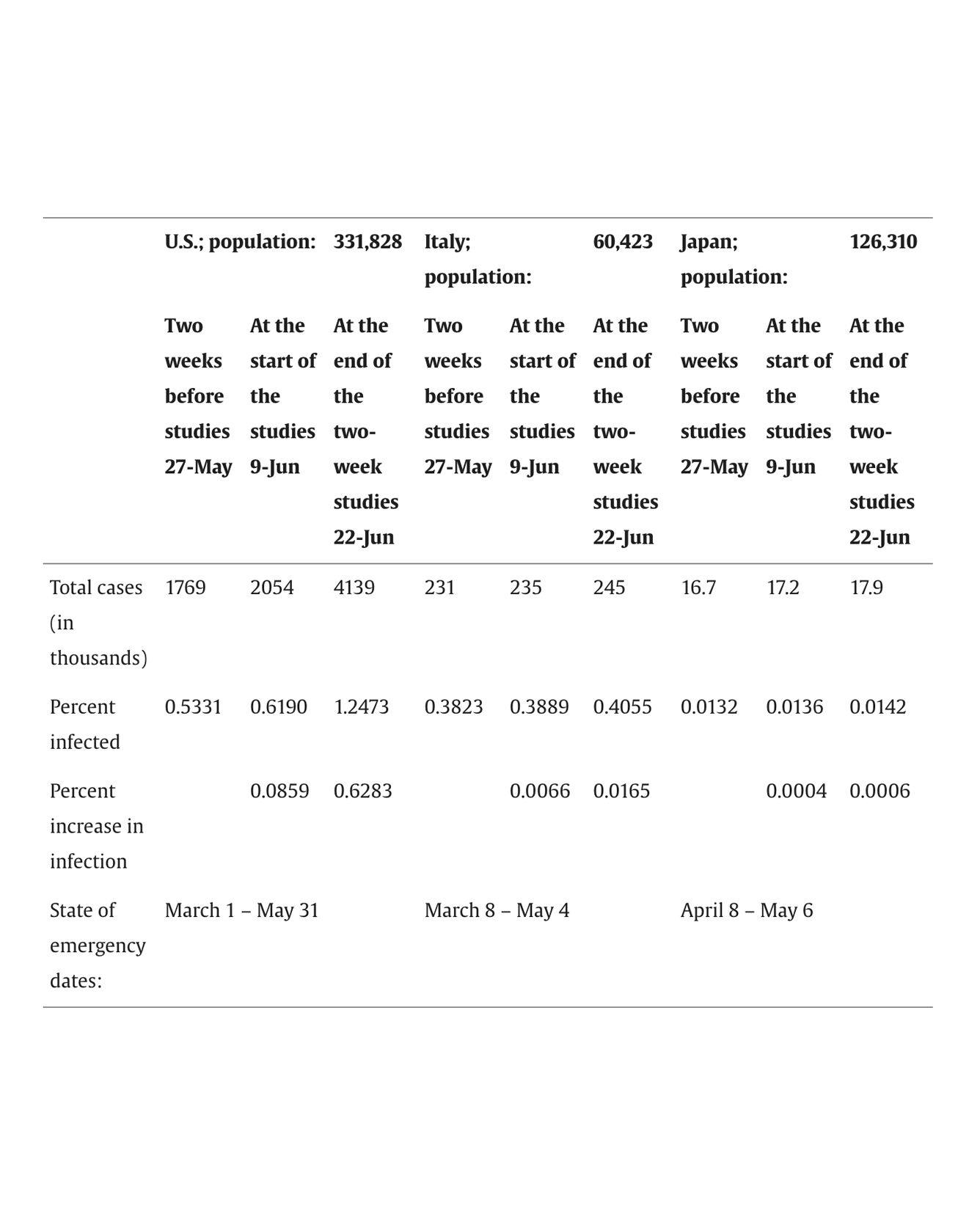
Forming a hetero-interface is a materials-design strategy that can access an astronomically large phase space. However, the immense phase space necessitates a high-throughput approach for an optimal interface design. Here we introduce a high-throughput computational framework, InterMatch, for efficiently predicting charge transfer, strain, and superlattice structure of an interface by leveraging the databases of individual bulk materials. Specifically, the algorithm reads in the lattice vectors, density of states, and the stiffness tensors for each material in their isolated form from the Materials Project. From these bulk properties, InterMatch estimates the interfacial properties. We benchmark InterMatch predictions for the charge transfer against experimental measurements and supercell density-functional theory calculations. We then use InterMatch to predict promising interface candidates for doping transition metal dichalcogenide MoSe2. Finally, we explain experimental observation of factor of 10 variation in the supercell periodicity within a few microns in graphene/α-RuCl3 by exploring low energy superlattice structures as a function of twist angle using InterMatch. We anticipate our open-source InterMatch algorithm accelerating and guiding ever-growing interfacial design efforts. Moreover, the interface database resulting from the InterMatch searches presented in this paper can be readily accessed online. READ MORE
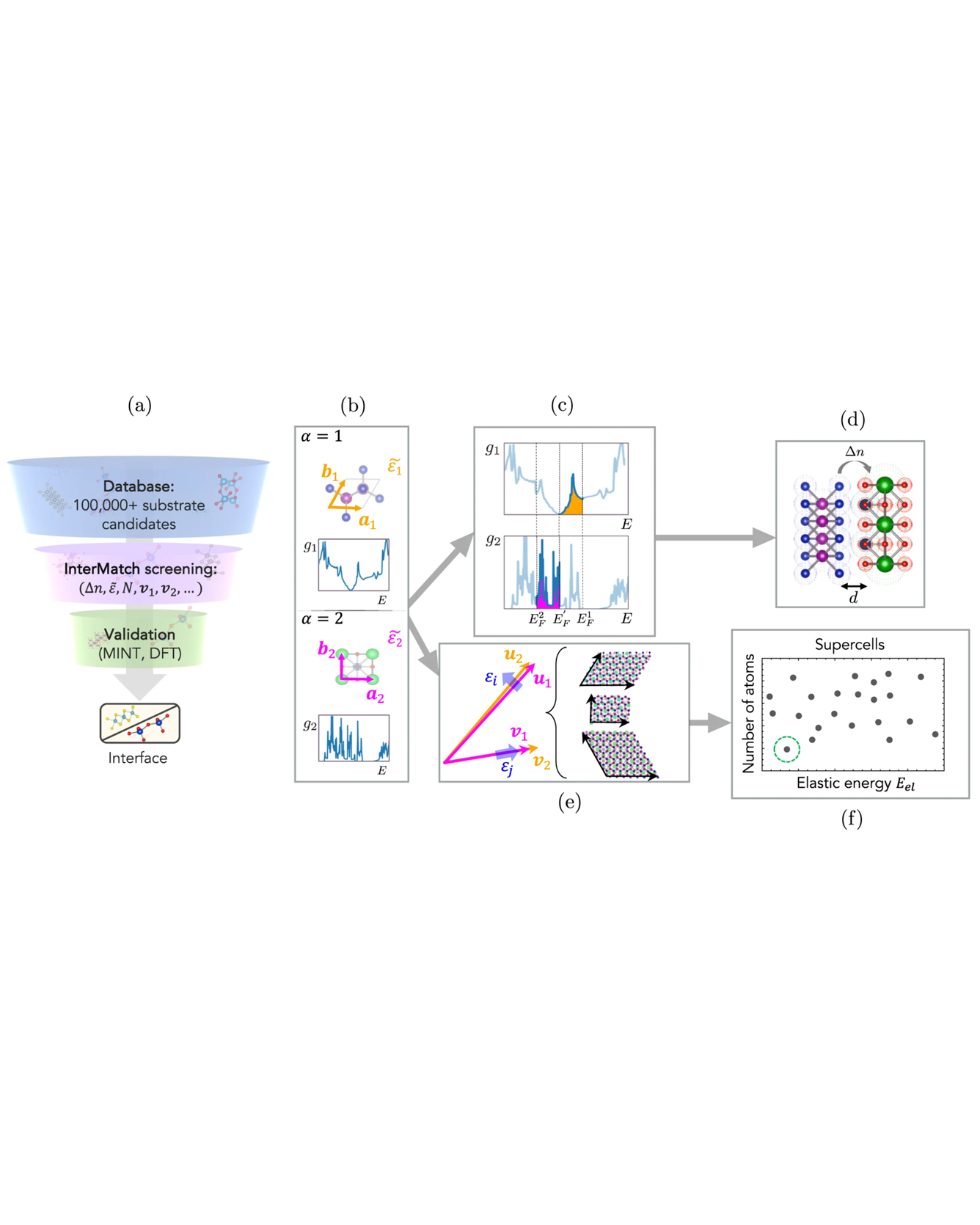
Open material databases storing thousands of material structures and their properties have become the cornerstone of modern computational materials science. Yet, the raw simulation outputs are generally not shared due to their huge size. In this work, we describe a cloud-based platform to enable fast post-processing of the trajectories and to facilitate sharing of the raw data. As an initial demonstration, our database includes 6286 molecular dynamics trajectories for amorphous polymer electrolytes (5.7 terabytes of data). We create a public analysis library at https://github.com/TRI-AMDD/htp_md to extract ion transport properties from the raw data using expert-designed functions and machine learning models. The analysis is run automatically on the cloud, and the results are uploaded onto an open database. Our platform encourages users to contribute both new trajectory data and analysis functions via public interfaces. Finally, we create a front-end user interface at https://www.htpmd.matr.io/ for browsing and visualization of our data. We envision the platform to be a new way of sharing raw data and new insights for the materials science community. READ MORE
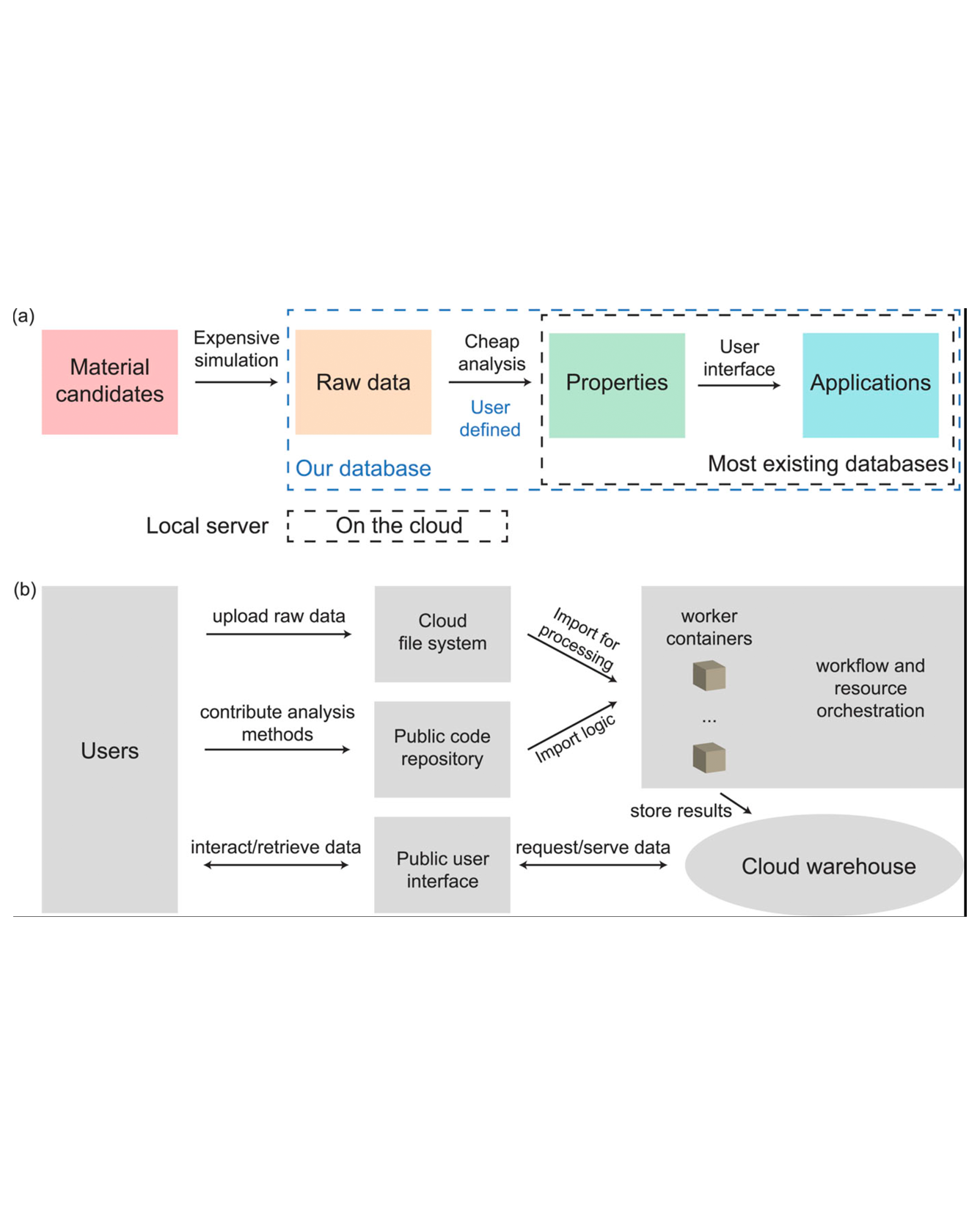
A growing body of research has explored how to support humans in making better use of AI-based decision support, including via training and onboarding. Existing research has focused on decision-making tasks where it is possible to evaluate “appropriate reliance” by comparing each decision against a ground truth label that cleanly maps to both the AI’s predictive target and the human decision-maker’s goals. However, this assumption does not hold in many real-world settings where AI tools are deployed today (e.g., social work, criminal justice, and healthcare). In this paper, we introduce a process-oriented notion of appropriate reliance called critical use that centers the human’s ability to situate AI predictions against knowledge that is uniquely available to them but unavailable to the AI model. To explore how training can support critical use, we conduct a randomized online experiment in a complex social decision-making setting: child maltreatment screening. We find that, by providing participants with accelerated, low-stakes opportunities to practice AI-assisted decision-making in this setting, novices came to exhibit patterns of disagreement with AI that resemble those of experienced workers. A qualitative examination of participants’ explanations for their AI-assisted decisions revealed that they drew upon qualitative case narratives, to which the AI model did not have access, to learn when (not) to rely on AI predictions. Our findings open new questions for the study and design of training for real-world AI-assisted decision-making. READ MORE
Designers often struggle to sufficiently explore large design spaces, which can lead to design fixation and suboptimal outcomes. Here we introduce DesignAID, a generative AI tool that supports broader design space exploration by first using large language models to produce a range of diverse ideas expressed in words, and then using image generation software to create images from these words. This innovative combination of AI-based capabilities allows human-computer pairs to rapidly create a diverse set of visual concepts without time-consuming drawing. In a study with 87 crowd-sourced designers, we found that designers rated the automatic generation of images from words as significantly more inspirational, enjoyable, and useful than a conventional baseline condition of image search using Pinterest. Surprisingly, however, we found that automatically generating highly diverse ideas had less value. For image generation, the high diversity condition was somewhat better in inspiration but no better in the other dimensions, and for image search it was significantly worse in all dimensions. READ MORE

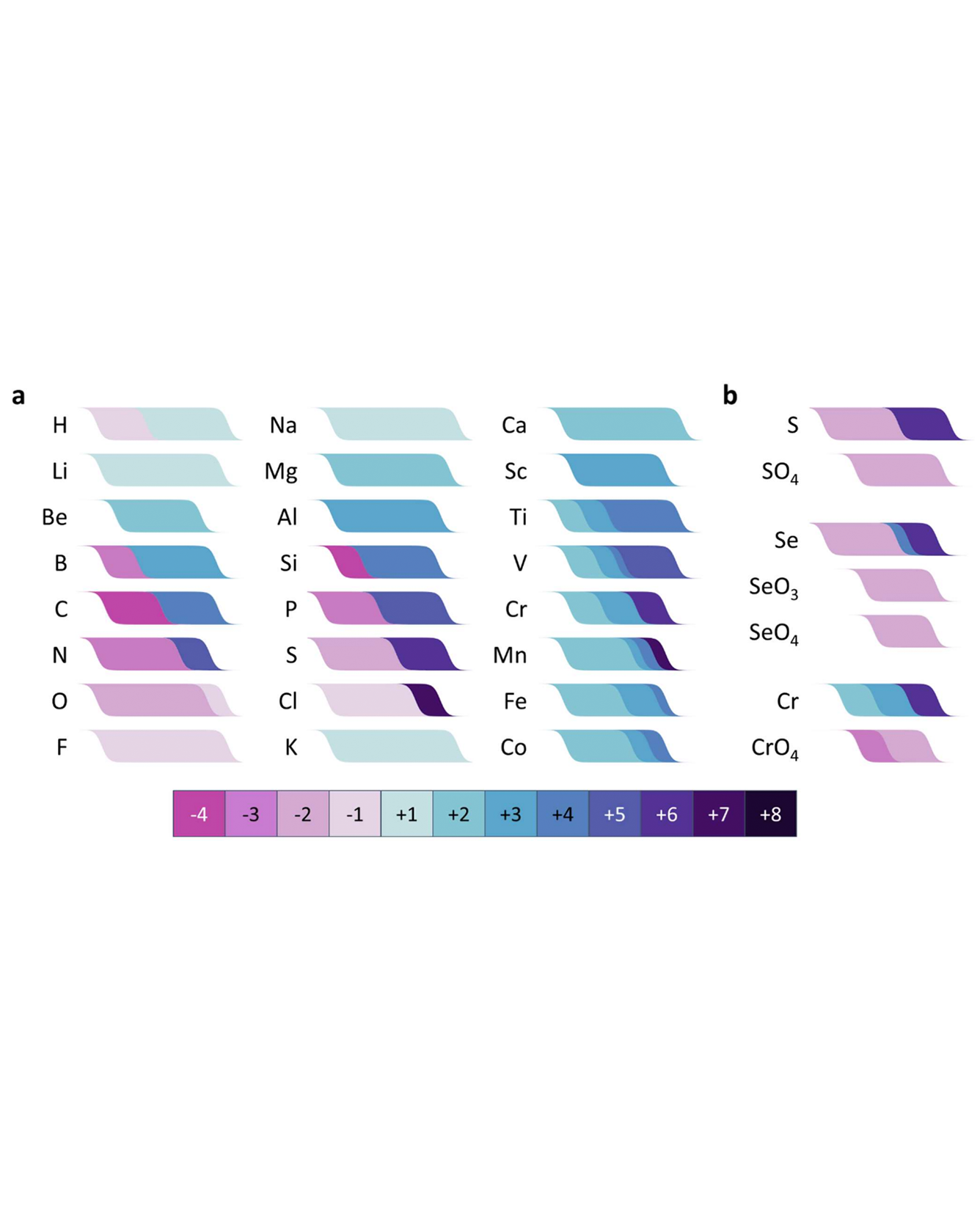
The electrochemical series is a useful tool in electrochemistry, but its effectiveness in materials chemistry is limited by the fact that the standard electrochemical series is based on a relatively small set of reactions, many of which are measured in aqueous solutions. We have used machine learning to create an electrochemical series for inorganic materials from tens of thousands of entries in the Inorganic Crystal Structure Database. We demonstrate that this approach enables the prediction of oxidation states directly from composition in a way that is physically justified, human-interpretable, and more accurate than a state-of-the-art transformer-based neural network model. We present applications of our model to structure prediction, materials discovery, and materials electrochemistry, and we discuss possible additional applications and areas for improvement. To facilitate the use of our approach, we introduce a freely available web site and API. READ MORE
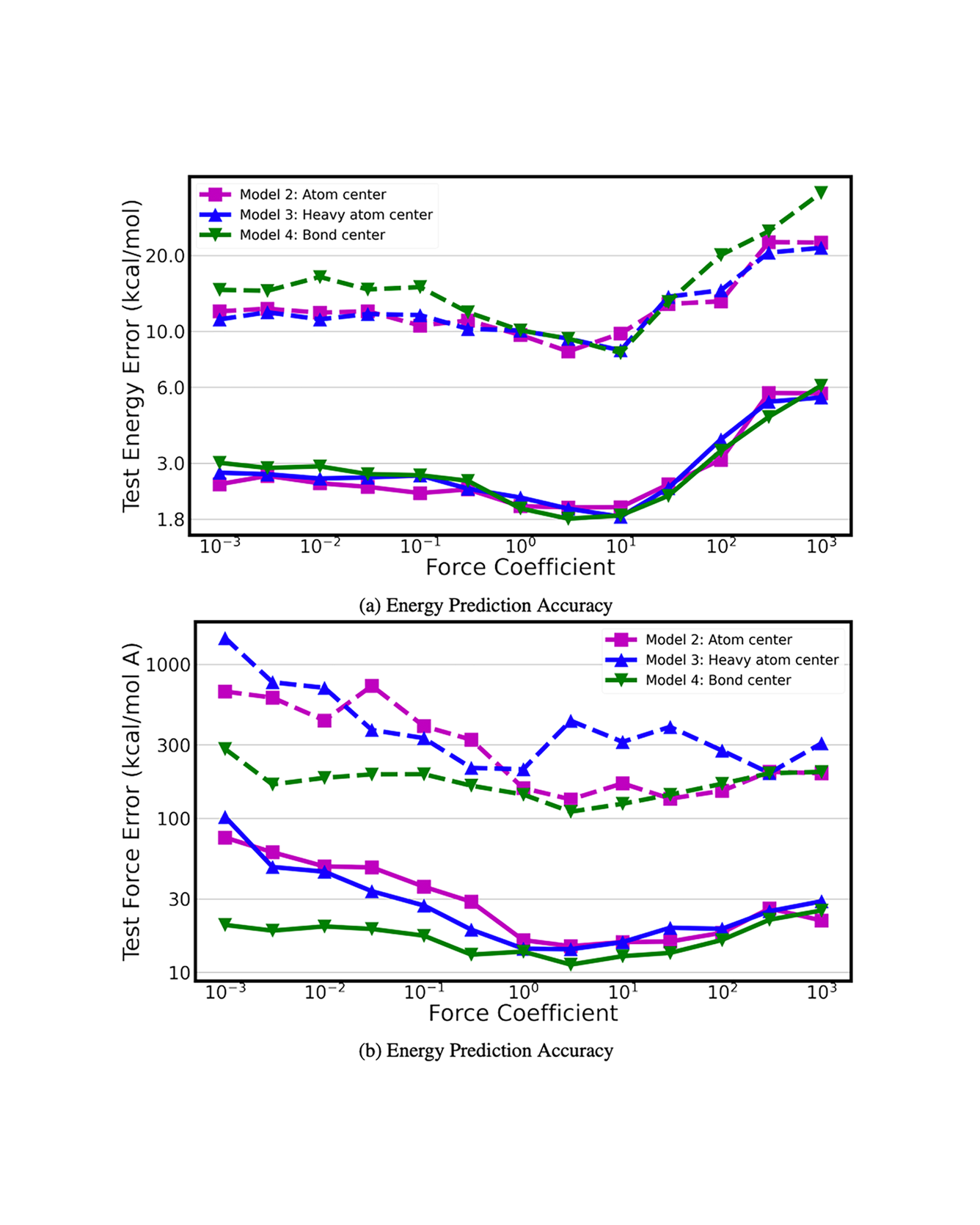
This paper introduces the Chemical Environment Modeling Theory (CEMT), a novel, generalized framework designed to overcome the limitations inherent in traditional atom-centered Machine Learning Force Field (MLFF) models, widely used in atomistic simulations of chemical systems. CEMT demonstrated enhanced flexibility and adaptability by allowing reference points to exist anywhere within the modeled domain and thus, enabling the study of various model architectures. Utilizing Gaussian Multipole (GMP) featurization functions, several models with different reference point sets, including finite difference grid-centered and bond-centered models, were tested to analyze the variance in capabilities intrinsic to models built on distinct reference points. The results underscore the potential of non-atom-centered reference points in force training, revealing variations in prediction accuracy, inference speed and learning efficiency. Finally, a unique connection between CEMT and real-space orbital-free finite element Density Functional Theory (FE-DFT) is established, and the implications include the enhancement of data efficiency and robustness. It allows the leveraging of spatially-resolved energy densities and charge densities from FE-DFT calculations, as well as serving as a pivotal step towards integrating known quantum-mechanical laws into the architecture of ML models. READ MORE
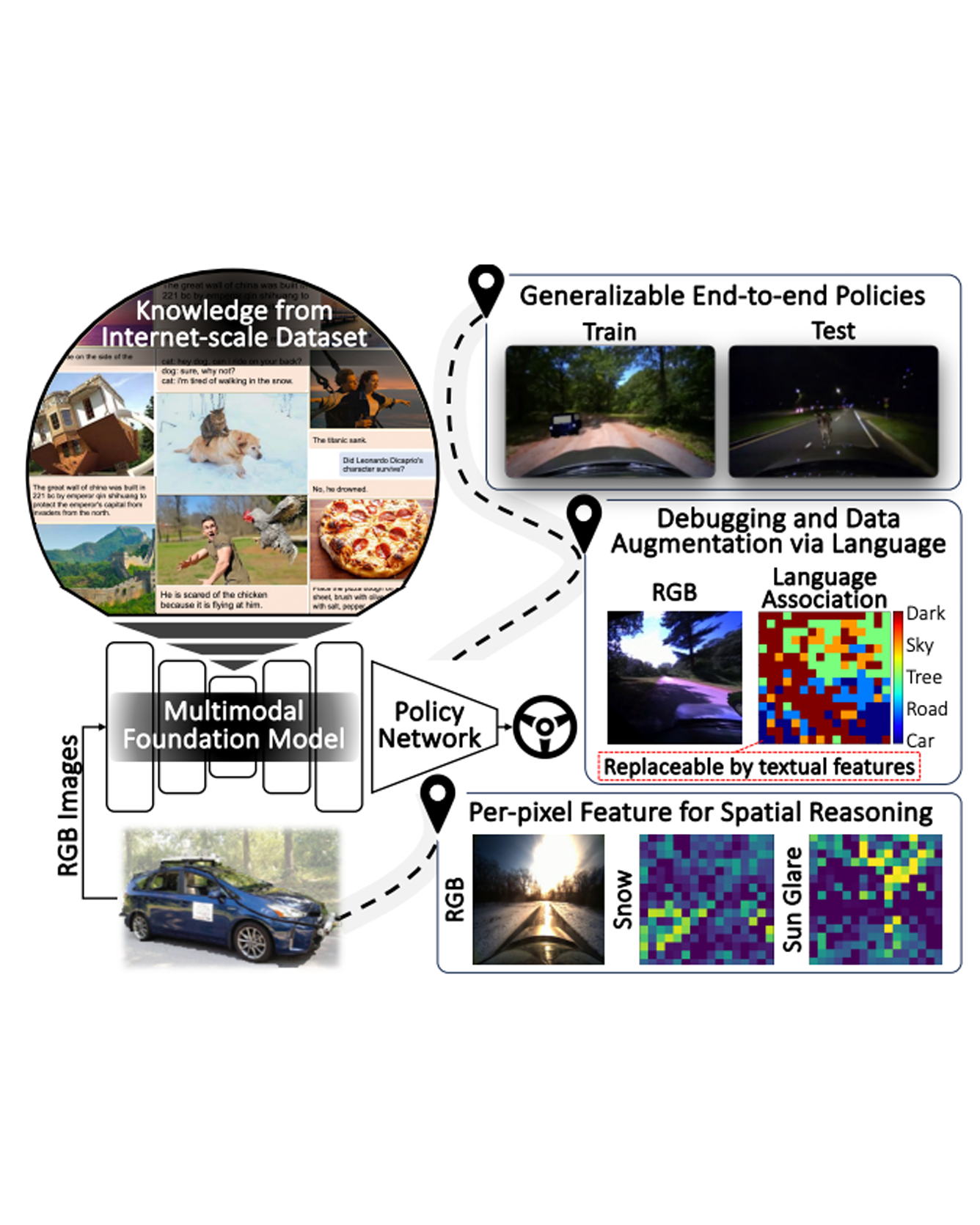
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video and to view the code and demos on our project webpage. READ MORE