Featured Publications

All Publications
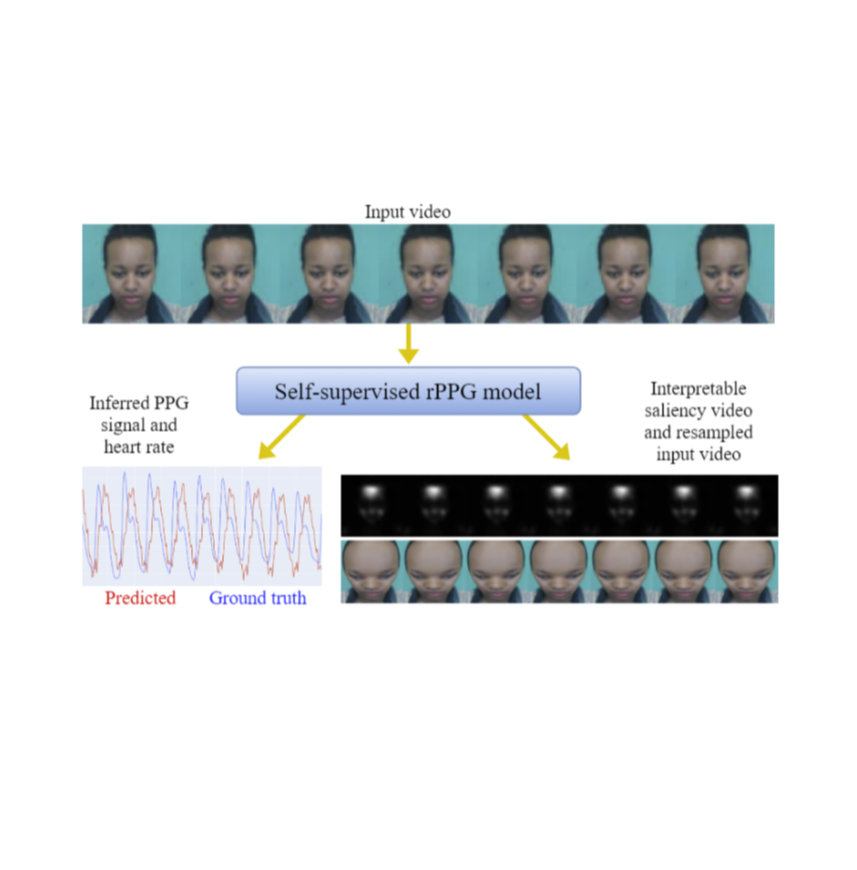
The ability to reliably estimate physiological signals from video is a powerful tool in low-cost, pre-clinical health monitoring. In this work we propose a new approach to remote photoplethysmography (rPPG) – the measurement of blood volume changes from observations of a person's face or skin. Similar to current state-of-the-art methods for rPPG, we apply neural networks to learn deep representations with invariance to nuisance image variation. In contrast to such methods, we employ a fully self-supervised training approach, which has no reliance on expensive ground truth physiological training data. Our proposed method uses contrastive learning with a weak prior over the frequency and temporal smoothness of the target signal of interest. We evaluate our approach on four rPPG datasets, showing that comparable or better results can be achieved compared to recent supervised deep learning methods but without using any annotation. In addition, we incorporate a learned saliency resampling module into both our unsupervised approach and supervised baseline. We show that by allowing the model to learn where to sample the input image, we can reduce the need for hand-engineered features while providing some interpretability into the model's behavior and possible failure modes. We release code for our complete training and evaluation pipeline to encourage reproducible progress in this exciting new direction. In addition, we used our proposed approach as the basis of our winning entry to the ICCV 2021 Vision 4 Vitals Workshop Challenge. READ MORE
Modeling multi-modal high-level intent is important for ensuring diversity in trajectory prediction. Existing approaches explore the discrete nature of human intent before predicting continuous trajectories, to improve accuracy and support explainability. However, these approaches often assume the intent to remain fixed over the prediction horizon, which is problematic in practice, especially over longer horizons. To overcome this limitation, we introduce HYPER, a general and expressive hybrid prediction framework that models evolving human intent. By modeling traffic agents as a hybrid discrete-continuous system, our approach is capable of predicting discrete intent changes over time. We learn the probabilistic hybrid model via a maximum likelihood estimation problem and leverage neural proposal distributions to sample adaptively from the exponentially growing discrete space. The overall approach affords a better trade-off between accuracy and coverage. We train and validate our model on the Argoverse dataset, and demonstrate its effectiveness through comprehensive ablation studies and comparisons with state-of-the-art models. READ MORE
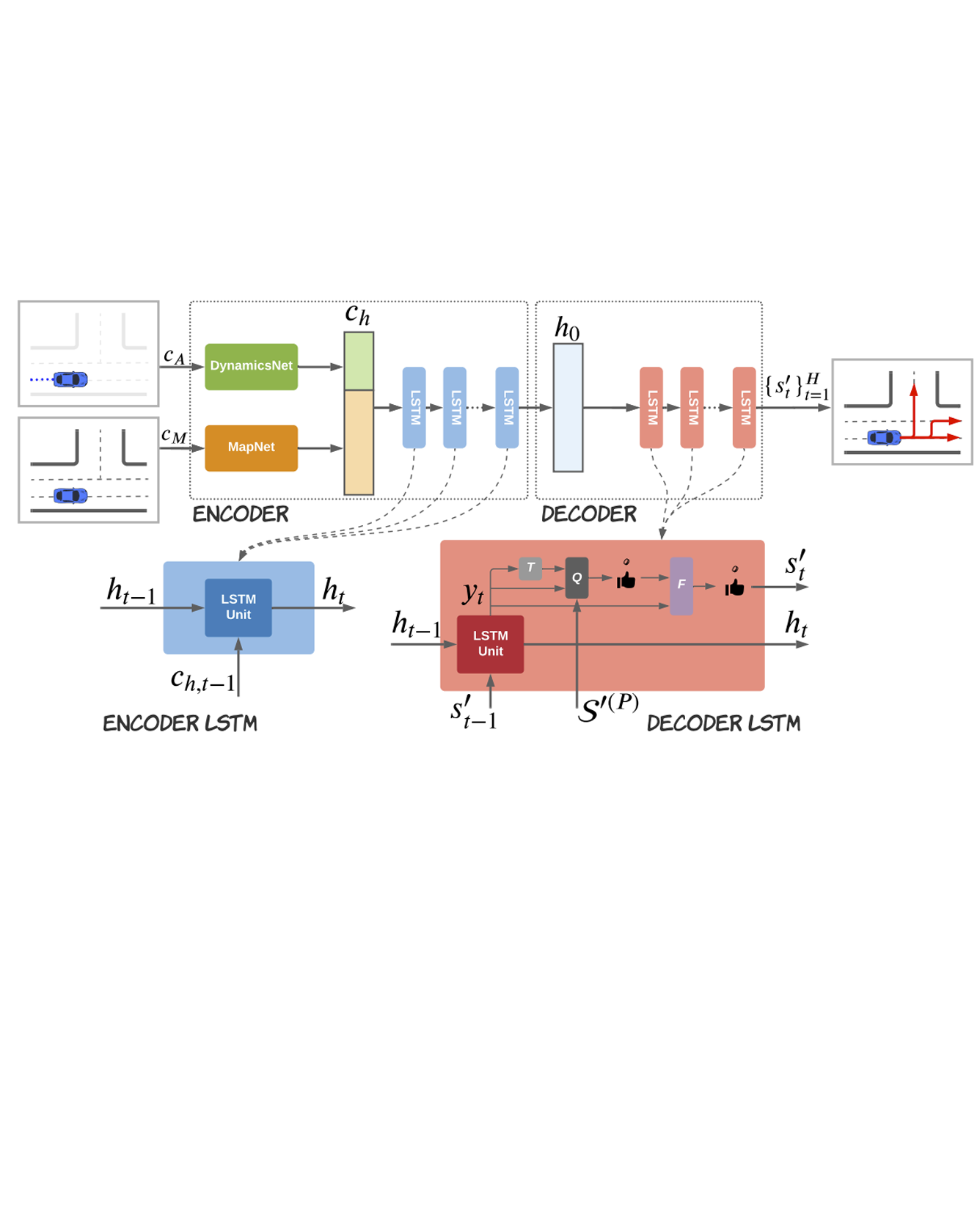
Lithium iron phosphate (LixFePO4), a cathode material used in rechargeable Li-ion batteries, phase separates upon de/lithiation under equilibrium. The interfacial structure and chemistry within these cathode materials affects Li-ion transport, and therefore battery performance. Correlative imaging of LixFePO4 was performed using four-dimensional scanning transmission electron microscopy (4D-STEM), scanning transmission X-ray microscopy (STXM), and X-ray ptychography in order to analyze the local structure and chemistry of the same particle set. Over 50,000 diffraction patterns from 10 particles provided measurements of both structure and chemistry at a nanoscale spatial resolution (16.6–49.5 nm) over wide (several micron) fields-of-view with statistical robustness. LixFePO4 particles at varying stages of delithiation were measured to examine the evolution of structure and chemistry as a function of delithiation. In lithiated and delithiated particles, local variations were observed in the degree of lithiation even while local lattice structures remained comparatively constant, and calculation of linear coefficients of chemical expansion suggest pinning of the lattice structures in these populations. Partially delithiated particles displayed broadly core–shell-like structures, however, with highly variable behavior both locally and per individual particle that exhibited distinctive intermediate regions at the interface between phases, and pockets within the lithiated core that correspond to FePO4 in structure and chemistry. The results provide insight into the LixFePO4 system, subtleties in the scope and applicability of Vegard’s law (linear lattice parameter-composition behavior) under local versus global measurements, and demonstrate a powerful new combination of experimental and analytical modalities for bridging the crucial gap between local and statistical characterization. READ MORE
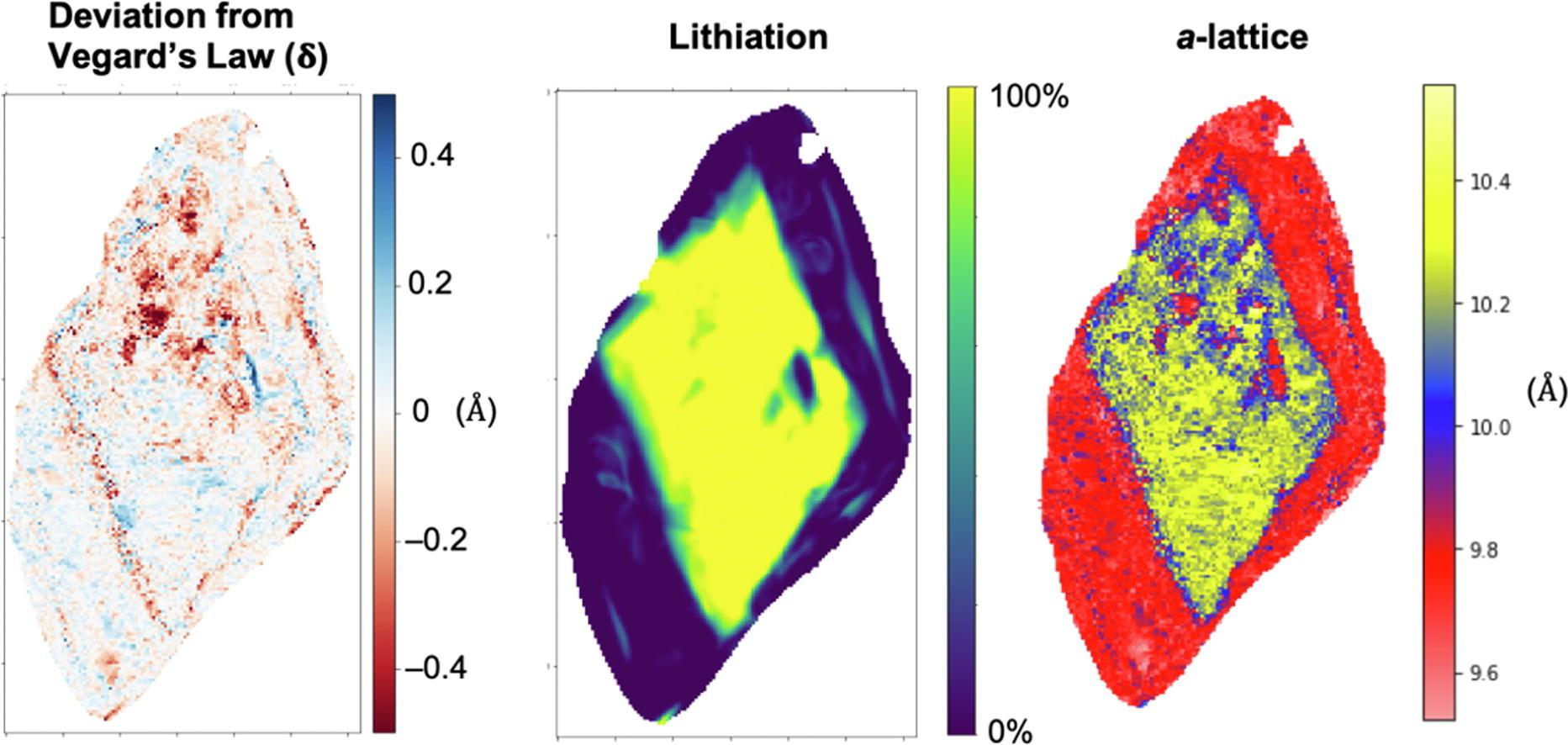
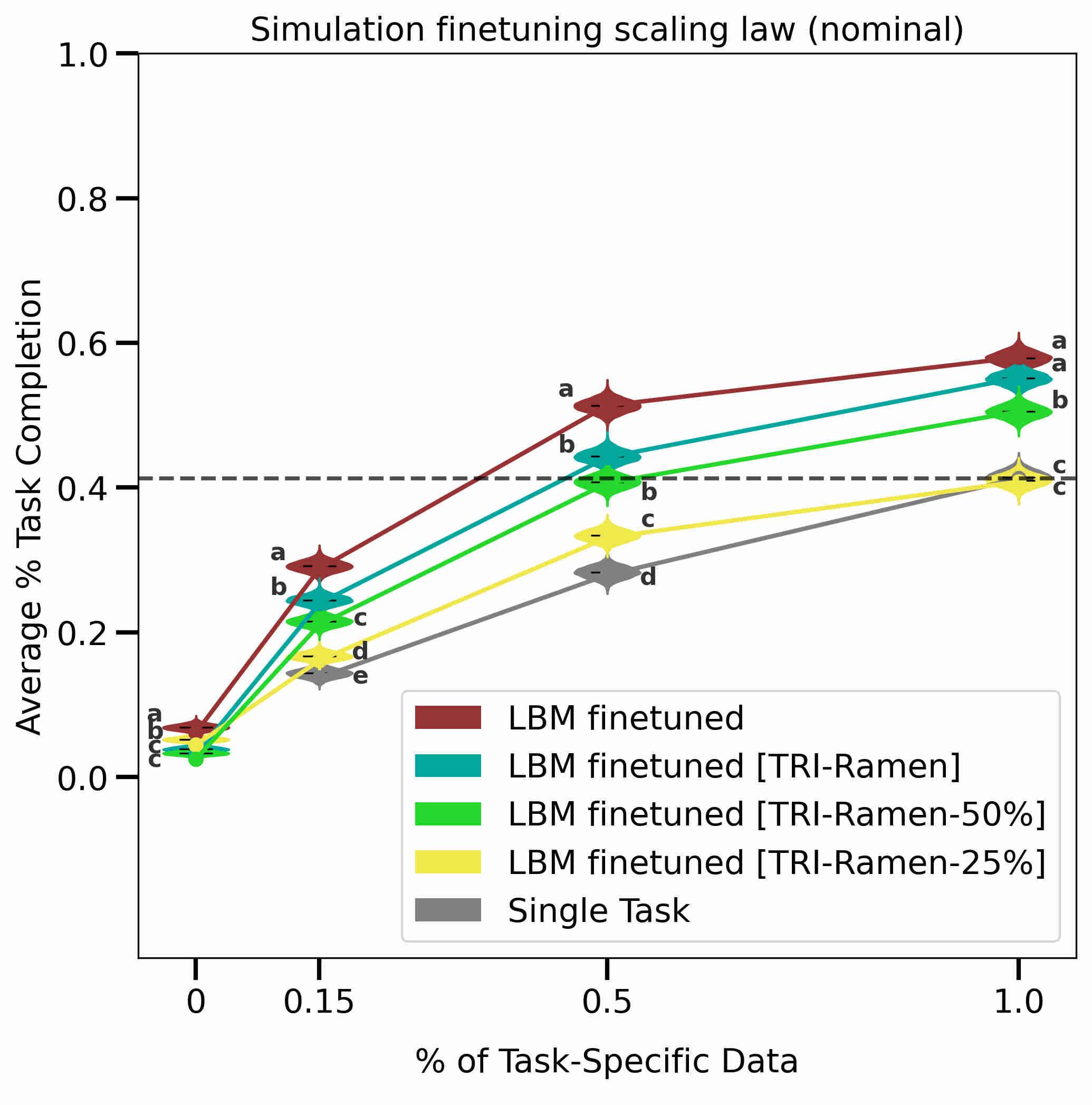
Solutions to many of the world's problems depend upon materials research and development. However, advanced materials can take decades to discover and decades more to fully deploy. Humans and robots have begun to partner to advance science and technology orders of magnitude faster than humans do today through the development and exploitation of closed-loop, autonomous experimentation systems. This review discusses the specific challenges and opportunities related to materials discovery and development that will emerge from this new paradigm. Our perspective incorporates input from stakeholders in academia, industry, government laboratories, and funding agencies. We outline the current status, barriers, and needed investments, culminating with a vision for the path forward. We intend the article to spark interest in this emerging research area and to motivate potential practitioners by illustrating early successes. We also aspire to encourage a creative reimagining of the next generation of materials science infrastructure. To this end, we frame future investments in materials science and technology, hardware and software infrastructure, artificial intelligence and autonomy methods, and critical workforce development for autonomous research. READ MORE
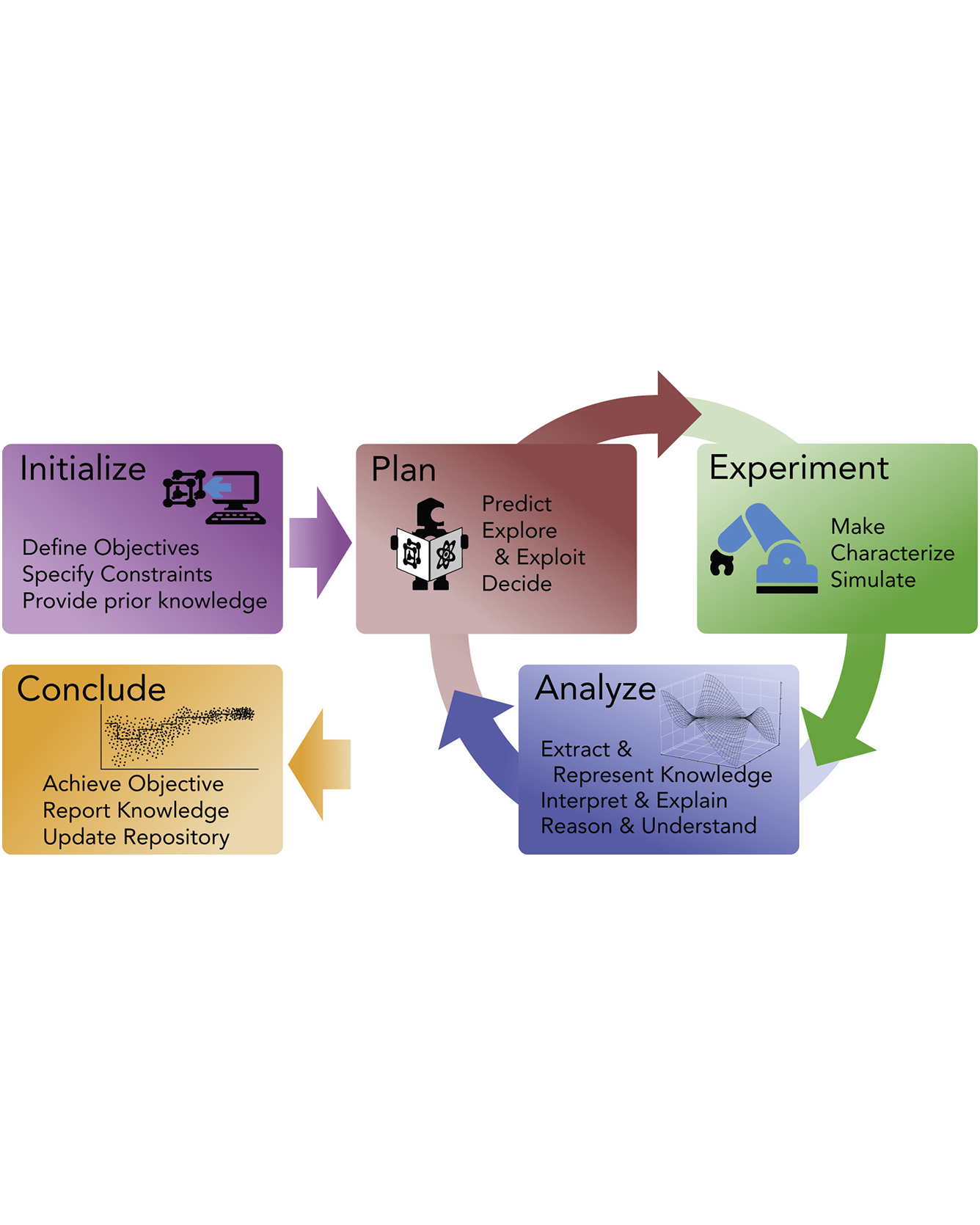
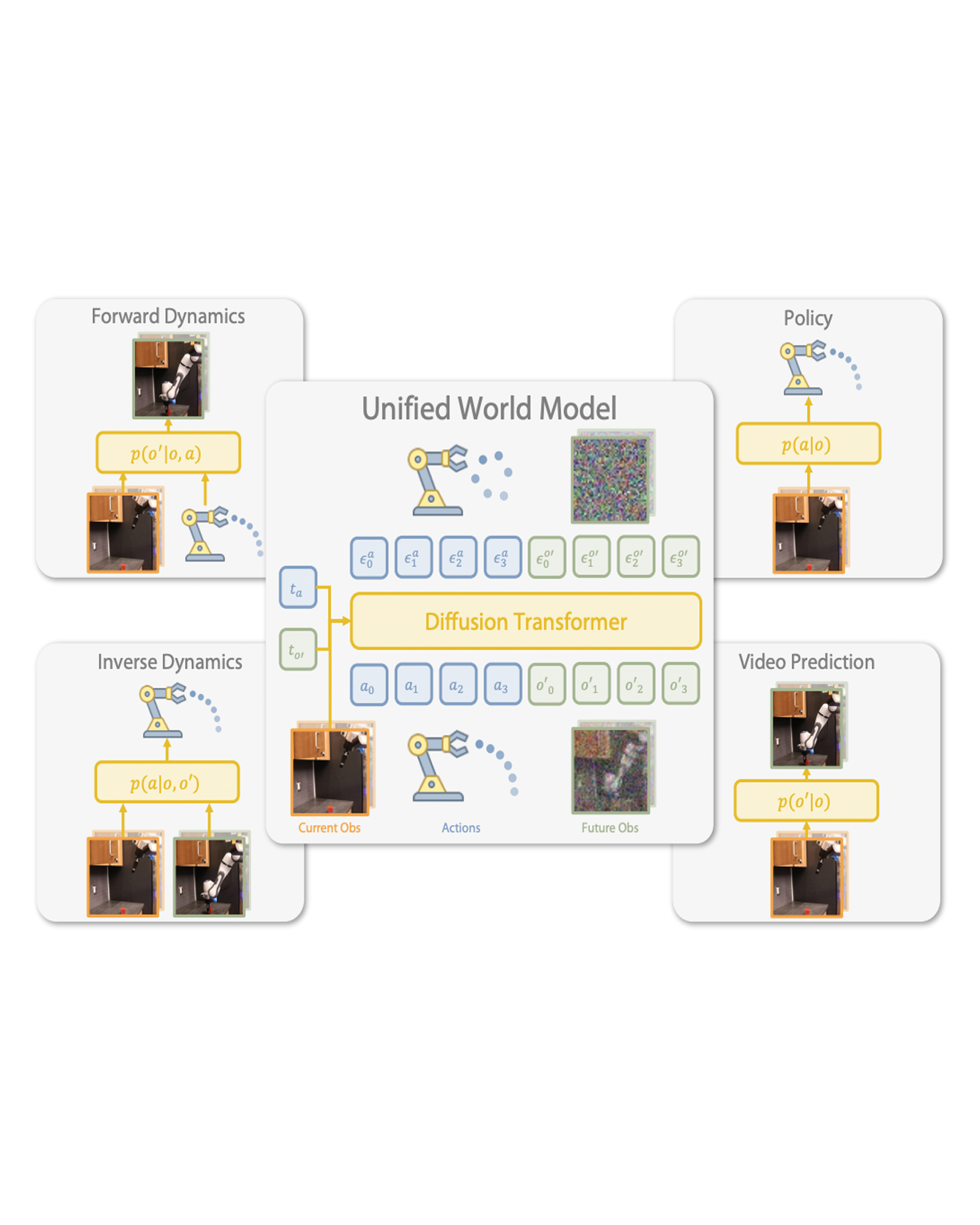
Risk-bounded motion planning is an important yet difficult problem for safety-critical tasks. While existing mathematical programming methods offer theoretical guarantees in the context of constrained Markov decision processes, they either lack scalability in solving larger problems or produce conservative plans. Recent advances in deep reinforcement learning improve scalability by learning policy networks as function approximators. In this paper, we propose an extension of soft actor critic model to estimate the execution risk of a plan through a risk critic and produce risk-bounded policies efficiently by adding an extra risk term in the loss function of the policy network. We define the execution risk in an accurate form, as opposed to approximating it through a summation of immediate risks at each time step that leads to conservative plans. Our proposed model is conditioned on a continuous spectrum of risk bounds, allowing the user to adjust the risk-averse level of the agent on the fly. Through a set of experiments, we show the advantage of our model in terms of both computational time and plan quality, compared to a state-of-the-art mathematical programming baseline, and validate its performance in more complicated scenarios, including nonlinear dynamics and larger state space. READ MORE
The Open Databases Integration for Materials Design (OPTIMADE) consortium has designed a universal application programming interface (API) to make materials databases accessible and interoperable. We outline the first stable release of the specification, v1.0, which is already supported by many leading databases and several software packages. We illustrate the advantages of the OPTIMADE API through worked examples on each of the public materials databases that support the full API specification. READ MORE
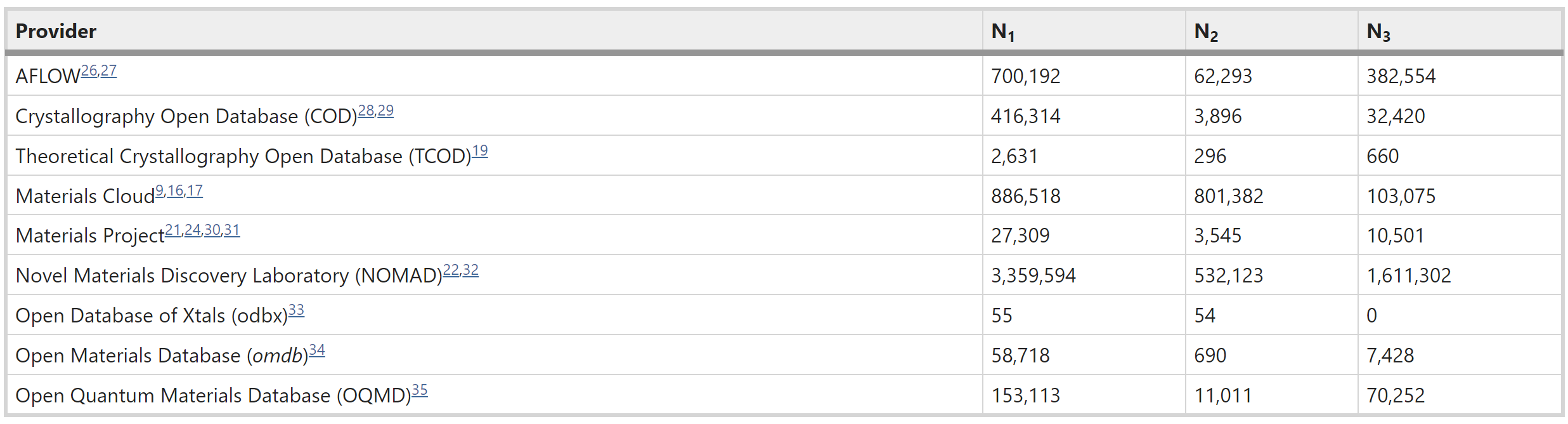
Tracking by detection, the dominant approach for online multi-object tracking, alternates between localization and re-identification steps. As a result, it strongly depends on the quality of instantaneous observations, often failing when objects are not fully visible. In contrast, tracking in humans is underlined by the notion of object permanence: once an object is recognized, we are aware of its physical existence and can approximately localize it even under full occlusions. In this work, we introduce an end-to-end trainable approach for joint object detection and tracking that is capable of such reasoning. We build on top of the recent CenterTrack architecture, which takes pairs of frames as input, and extend it to videos of arbitrary length. To this end, we augment the model with a spatio-temporal, recurrent memory module, allowing it to reason about object locations and identities in the current frame using all the previous history. It is, however, not obvious how to train such an approach. We study this question on a new, large-scale, synthetic dataset for multi-object tracking, which provides ground truth annotations for invisible objects, and propose several approaches for supervising tracking behind occlusions. Our model, trained jointly on synthetic and real data, outperforms the state of the art on KITTI, and MOT17 datasets thanks to its robustness to occlusions. READ MORE

Recent progress in 3D object detection from single images leverages monocular depth estimation as a way to produce 3D pointclouds, turning cameras into pseudo-lidar sensors. These two-stage detectors improve with the accuracy of the intermediate depth estimation network, which can itself be improved without manual labels via large-scale self-supervised learning. However, they tend to suffer from overfitting more than end-to-end methods, are more complex, and the gap with similar lidar-based detectors remains significant. In this work, we propose an end-to-end, single stage, monocular 3D object detector, DD3D, that can benefit from depth pre-training like pseudo-lidar methods, but without their limitations. Our architecture is designed for effective information transfer between depth estimation and 3D detection, allowing us to scale with the amount of unlabeled pre-training data. Our method achieves state-of-the-art results on two challenging benchmarks, with 16.34% and 9.28% AP for Cars and Pedestrians (respectively) on the KITTI-3D benchmark, and 41.5% mAP on NuScenes. READ MORE


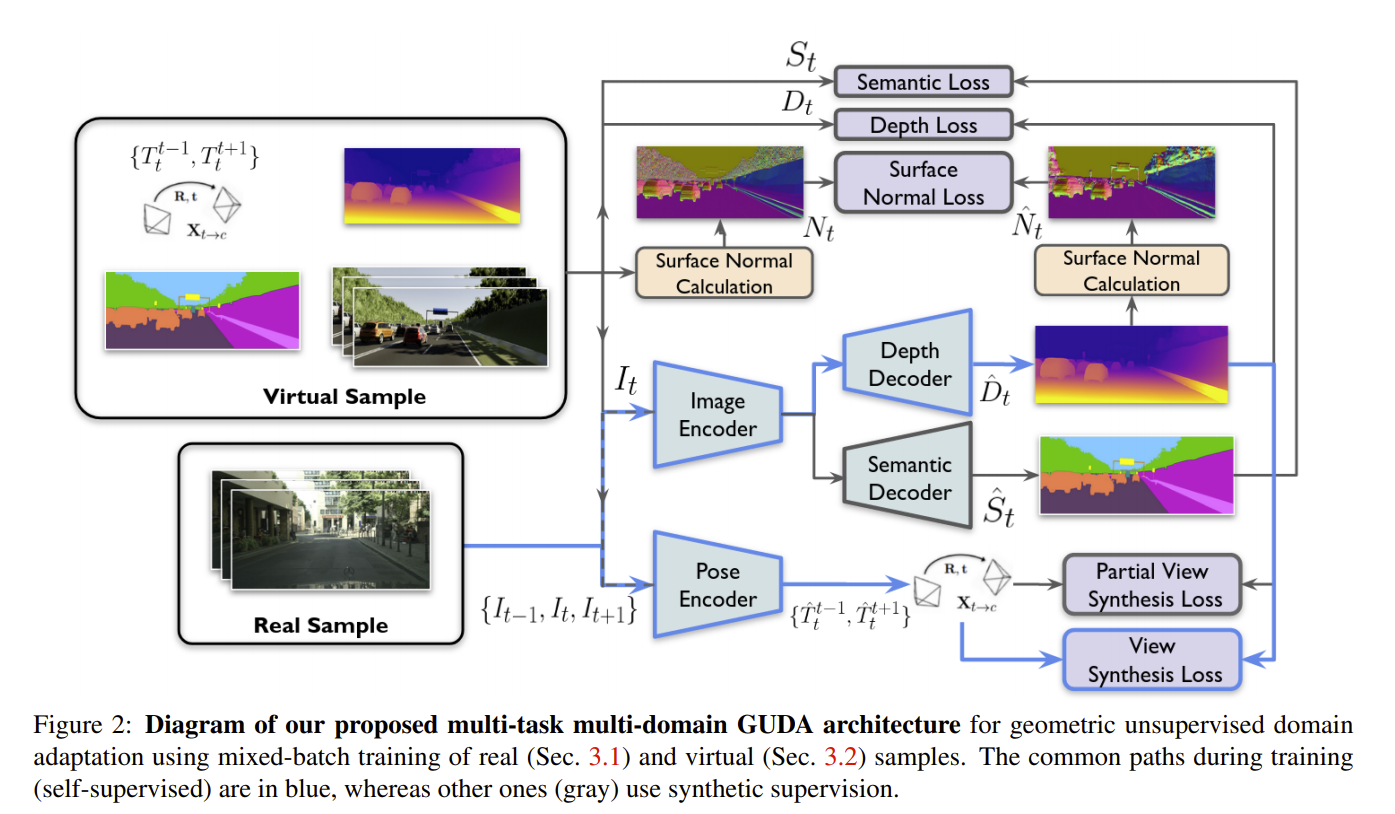
Simulators can efficiently generate large amounts of labeled synthetic data with perfect supervision for hard-to-label tasks like semantic segmentation. However, they introduce a domain gap that severely hurts real-world performance. We propose to use self-supervised monocular depth estimation as a proxy task to bridge this gap and improve sim-to-real unsupervised domain adaptation (UDA). Our Geometric Unsupervised Domain Adaptation method (GUDA) learns a domain-invariant representation via a multi-task objective combining synthetic semantic supervision with real-world geometric constraints on videos. GUDA establishes a new state of the art in UDA for semantic segmentation on three benchmarks, outperforming methods that use domain adversarial learning, self-training, or other self-supervised proxy tasks. Furthermore, we show that our method scales well with the quality and quantity of synthetic data while also improving depth prediction. READ MORE

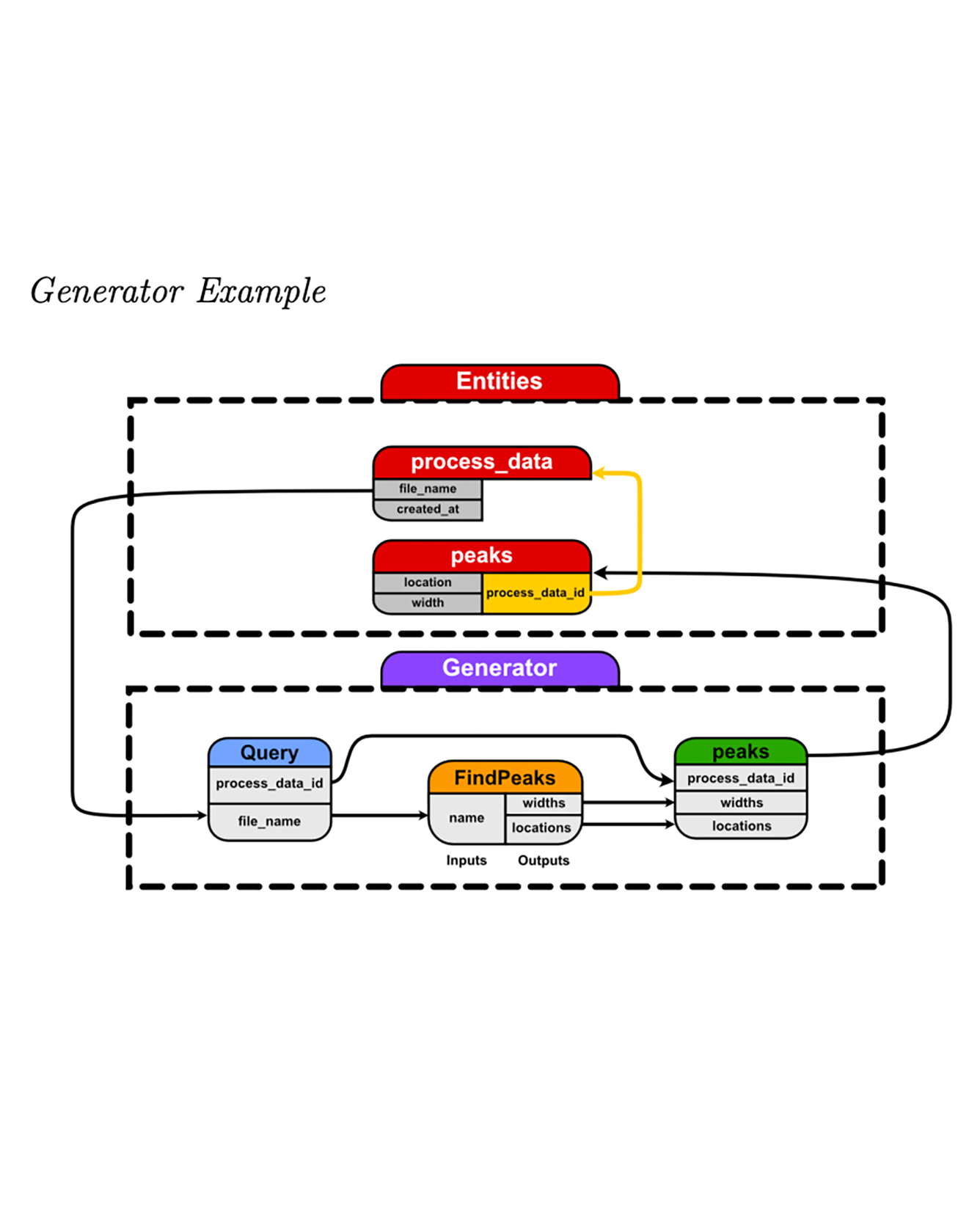
In this work, we present DBgen, a Python library that provides a framework for defining extract-transform-load (ETL) pipelines to create and populate SQL databases. DBgen is most useful when the underlying data has complex relationships, requires multi-step analysis, is large-scale, and the type of data being collected changes frequently. Scientific data often fits this description. With current tooling, defining ETL pipelines for this particularly difficult- to-manage data is so onerous that a great deal of it does not end up being stored in a database and is opaque. DBgen is designed to fill the gap in the current tooling and reduce the barrier to defining ETL pipelines such data. READ MORE