Featured Publications

All Publications
Self-supervised monocular depth and ego-motion estimation is a promising approach to replace or supplement expensive depth sensors such as LiDAR for robotics applications like autonomous driving. However, most research in this area focuses on a single monocular camera or stereo pairs that cover only a fraction of the scene around the vehicle. In this work, we extend monocular self-supervised depth and ego-motion estimation to large-baseline multi-camera rigs. Using generalized spatio-temporal contexts, pose consistency constraints, and carefully designed photometric loss masking, we learn a single network generating dense, consistent, and scale-aware point clouds that cover the same full surround 360 degree field of view as a typical LiDAR scanner. We also propose a new scale-consistent evaluation metric more suitable to multi-camera settings. Experiments on two challenging benchmarks illustrate the benefits of our approach over strong baselines. READ MORE

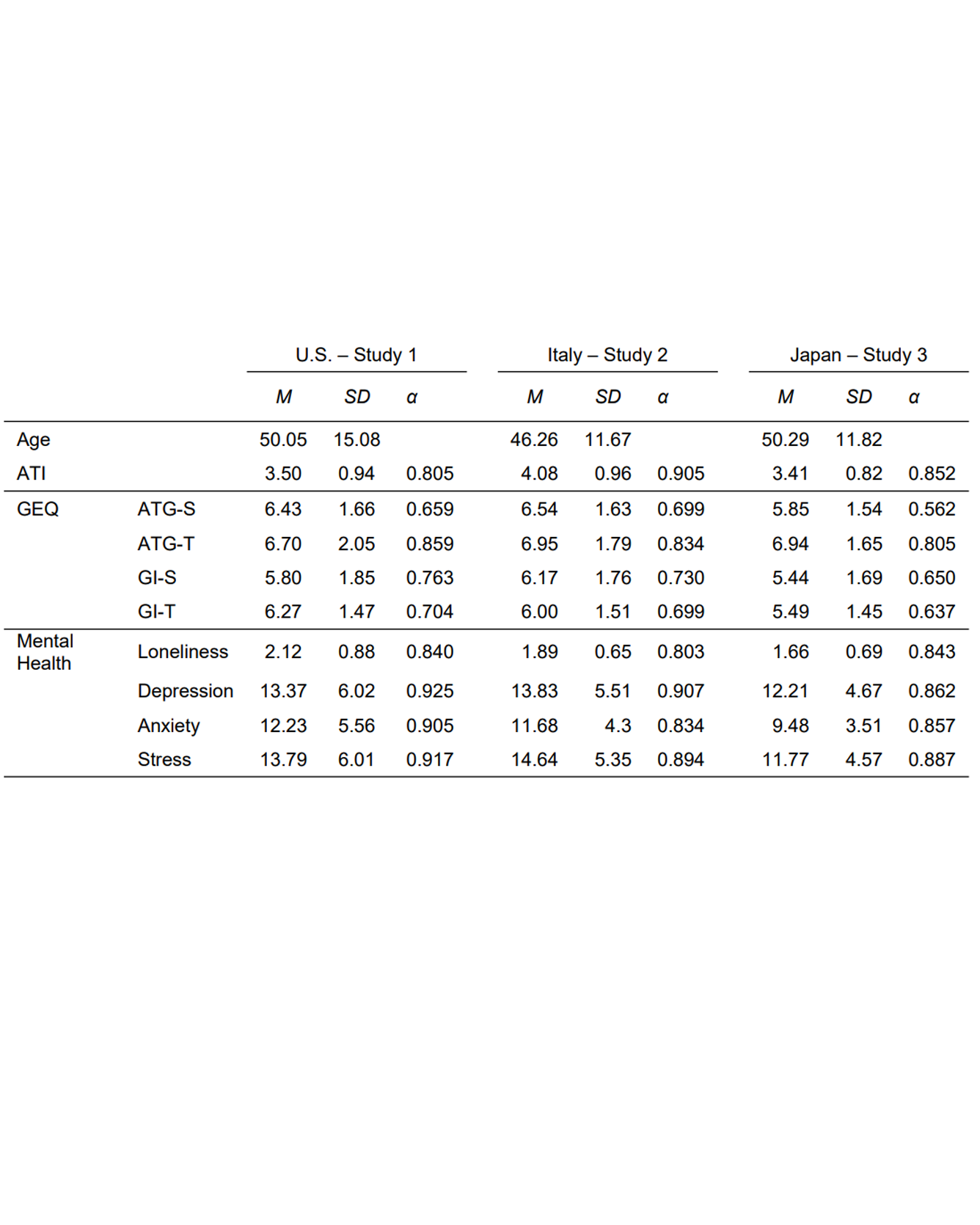
Group cohesion and social contact with other people is critical for supporting mental health (defined here as reduced loneliness, depression, anxiety, stress). Sometimes it is difficult to interact with social groups in person because of distance, poor health, or a global pandemic. In such cases, people can maintain social contact through technology like instant messaging, audio calls, and video calls. Age plays a major role in mental health and technology use: Age typically correlates with worse mental health and poor technology use, which could doubly harm older adults when most of their social connection can only be made through technology. However, some studies have shown that older adults can be quite capable of using technology and use it differently than younger adults. In this study, we sought a deeper understanding of the relationship between participants’ age and their use of and affinity for technology on group cohesion and mental health during social isolation. To do so, we surveyed participants in the United States (U.S.; Study 1, N = 202), Italy (Study 2, N = 325), and Japan (Study 3, N = 261) during a time of increased social isolation due to quarantine restrictions for the COVID-19 pandemic. Results indicated that greater affinity for technology related to worse group cohesion and mental health for younger adults , but better group cohesion and mental health for older adults . Certain subtypes of group cohesion (group integration for social purposes; GI-S) related to better mental health for younger adults and others (group integration for task purposes; GI-T) related to better mental health for older adults. Effects of age in group cohesion replicated across countries, although which specific mental health measures showed effects depended on country. Future studies of technology use and needs should differentiate populations based on age, technology use, and affinity for technology to provide further insights into how technology can best support group cohesion and mental health. Read More
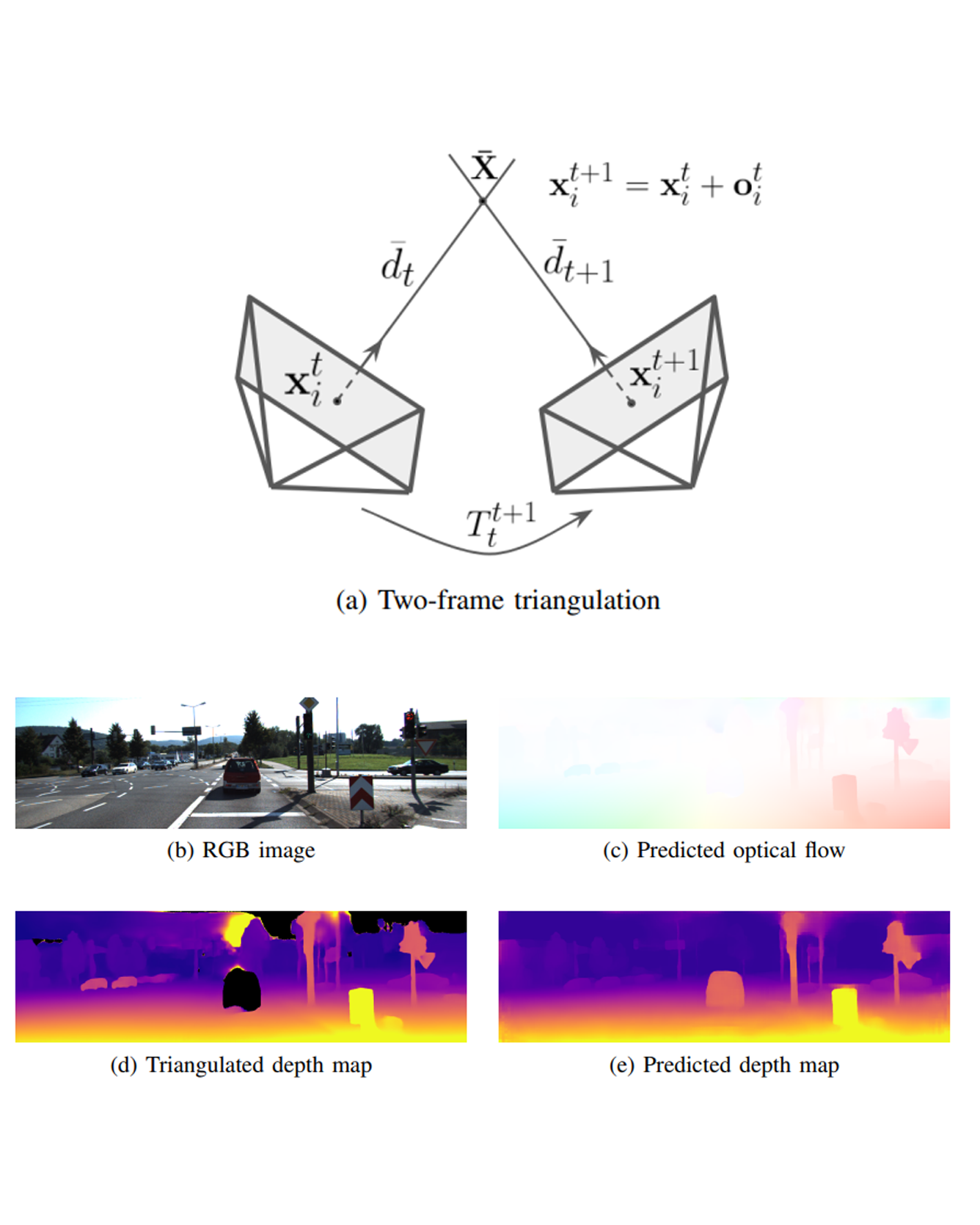
Self-supervised monocular depth estimation enables robots to learn 3D perception from raw video streams. This scalable approach leverages projective geometry and ego-motion to learn via view synthesis, assuming the world is mostly static. Dynamic scenes, which are common in autonomous driving and human-robot interaction, violate this assumption. Therefore, they require modeling dynamic objects explicitly, for instance via estimating pixel-wise 3D motion, i.e. scene flow. However, the simultaneous self-supervised learning of depth and scene flow is ill-posed, as there are infinitely many combinations that result in the same 3D point. In this paper we propose DRAFT, a new method capable of jointly learning depth, optical flow, and scene flow by combining synthetic data with geometric self-supervision. Building upon the RAFT architecture, we learn optical flow as an intermediate task to bootstrap depth and scene flow learning via triangulation. Our algorithm also leverages temporal and geometric consistency losses across tasks to improve multi-task learning. Our DRAFT architecture simultaneously establishes a new state of the art in all three tasks in the self-supervised monocular setting on the standard KITTI benchmark. READ MORE
Adopting electric vehicles (EVs) is an important step towards meeting climate change targets. Despite the increased availability of electric vehicles (EVs), many individuals are unfamiliar with the environmental and cost savings and how their driving behaviors might change (e.g., where and how to charge) when switching from a conventional fuel vehicle. While behavioral science research can identify what factors are barriers to EV adoption, there is a struggle to identify interventions that can help mitigate these barriers. We introduce EV Life, a mobile app for showing a counterfactual view of people’s automotive behaviors which introduces two functions. First, the app monitors a person’s driving trips in their current vehicle and provides a counterfactual dashboard that highlights what their trip would be like with an EV, including information about cost savings, reduction in carbon emissions, and charging locations. Second, the app provides a research platform for testing interventions for belief change using rule based or machine learning notification delivery. READ MORE

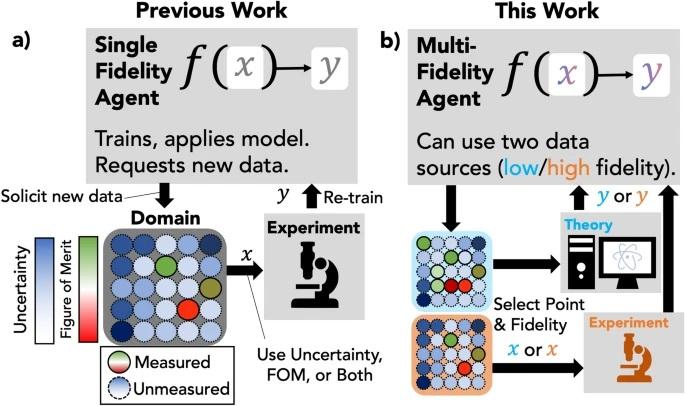
Sequential learning for materials discovery is a paradigm where a computational agent solicits new data to simultaneously update a model in service of exploration (finding the largest number of materials that meet some criteria) or exploitation (finding materials with an ideal figure of merit). In real-world discovery campaigns, new data acquisition may be costly and an optimal strategy may involve using and acquiring data with different levels of fidelity, such as first-principles calculation to supplement an experiment. In this work, we introduce agents which can operate on multiple data fidelities, and benchmark their performance on an emulated discovery campaign to find materials with desired band gap values. The fidelities of data come from the results of DFT calculations as low fidelity and experimental results as high fidelity. We demonstrate performance gains of agents which incorporate multi-fidelity data in two contexts: either using a large body of low fidelity data as a prior knowledge base or acquiring low fidelity data in-tandem with experimental data. This advance provides a tool that enables materials scientists to test various acquisition and model hyperparameters to maximize the discovery rate of their own multi-fidelity sequential learning campaigns for materials discovery. This may also serve as a reference point for those who are interested in practical strategies that can be used when multiple data sources are available for active or sequential learning campaigns. READ MORE
This paper studies the problem of object discovery -- separating objects from the background without manual labels. Existing approaches utilize appearance cues, such as color, texture, and location, to group pixels into object-like regions. However, by relying on appearance alone, these methods fail to separate objects from the background in cluttered scenes. This is a fundamental limitation since the definition of an object is inherently ambiguous and context-dependent. To resolve this ambiguity, we choose to focus on dynamic objects -- entities that can move independently in the world. We then scale the recent auto-encoder based frameworks for unsupervised object discovery from toy synthetic images to complex real-world scenes. To this end, we simplify their architecture, and augment the resulting model with a weak learning signal from general motion segmentation algorithms. Our experiments demonstrate that, despite only capturing a small subset of the objects that move, this signal is enough to generalize to segment both moving and static instances of dynamic objects. We show that our model scales to a newly collected, photo-realistic synthetic dataset with street driving scenarios. Additionally, we leverage ground truth segmentation and flow annotations in this dataset for thorough ablation and evaluation. Finally, our experiments on the real-world KITTI benchmark demonstrate that the proposed approach outperforms both heuristic- and learning-based methods by capitalizing on motion cues. READ MORE

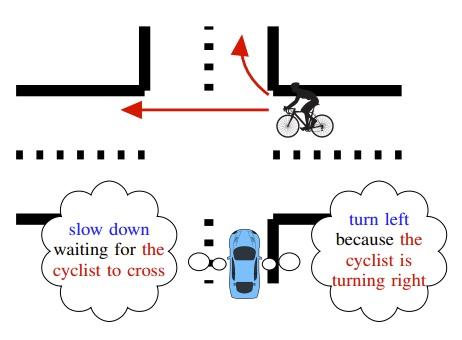
Language allows humans to build mental models that interpret what is happening around them resulting in more accurate long-term predictions. We present a novel trajectory prediction model that uses linguistic intermediate representations to forecast trajectories, and is trained using trajectory samples with partially-annotated captions. The model learns the meaning of each of the words without direct per-word supervision. At inference time, it generates a linguistic description of trajectories which captures maneuvers and interactions over an extended time interval. This generated description is used to refine predictions of the trajectories of multiple agents. We train and validate our model on the Argoverse dataset, and demonstrate improved accuracy results in trajectory prediction. In addition, our model is more interpretable: it presents part of its reasoning in plain language as captions, which can aid model development and can aid in building confidence in the model before deploying it. READ MORE
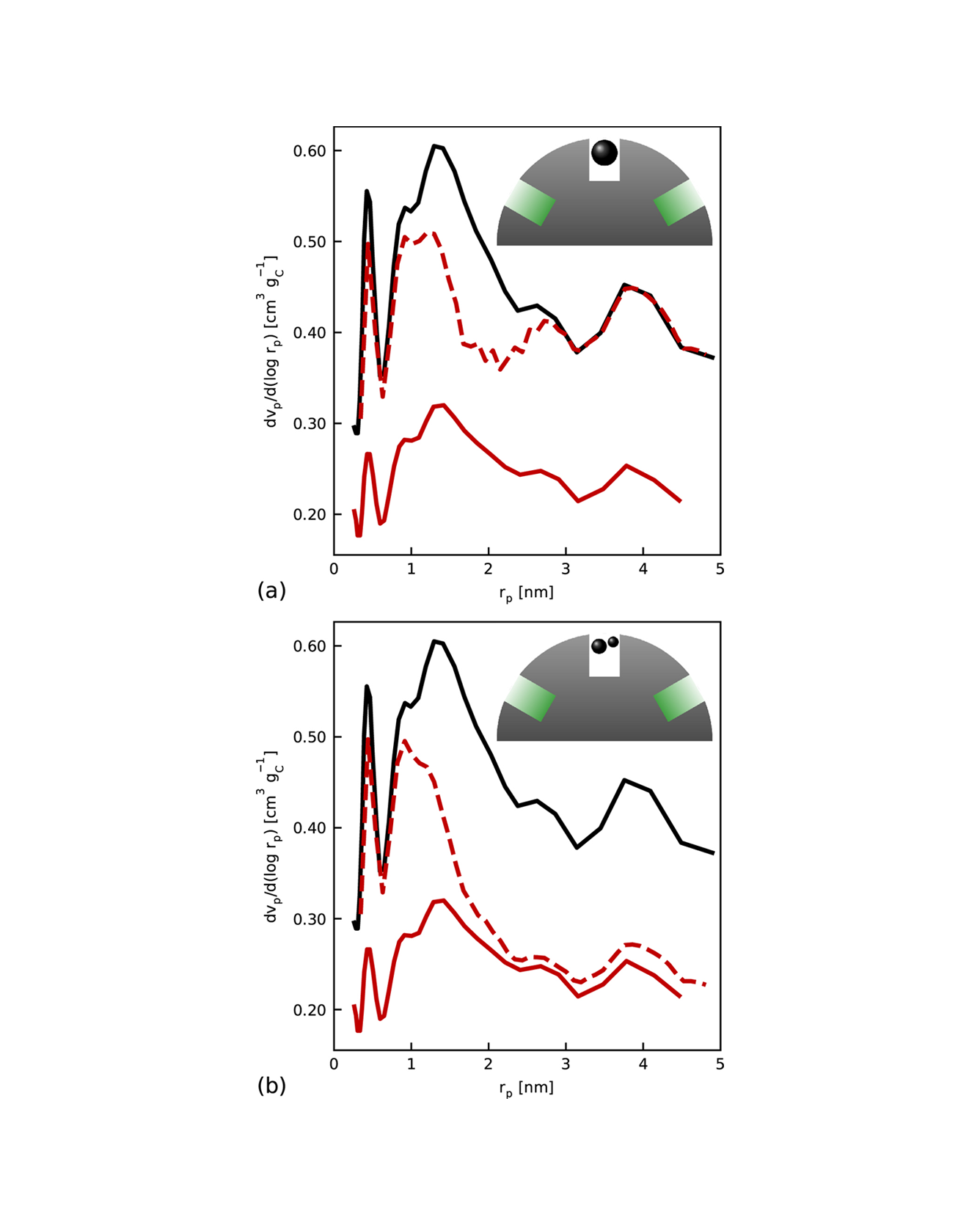
We present a model of the cathode catalyst layer morphology before and after loading a porous catalyst support with Pt and ionomer. Support nanopores and catalyst particles within pores and on the support surface are described by size distributions, allowing for qualitative processes during the addition of a material phase to be dependent on the observed pore and particle size. A particular focus is put on the interplay of pore impregnation and blockage due to ionomer loading and the consequences for the Pt/ionomer interface, ionomer film thickness and protonic binding of particles within pores. We used the model to emulate six catalyst/support combinations from literature with different porosity, surface area and pore size distributions of the support as well as varying particle size distributions and ionomer/carbon ratios. Besides providing qualitatively and quantitatively accurate predictions, the model is able to explain why the protonically active catalyst surface area has been reported to not increase monotonically with ionomer addition for some supports, but rather decrease again when the optimum ionomer content is exceeded. The proposed model constitutes a fast translation from manufacturing parameters to catalyst layer morphology which can be incorporated into existing performance and degradation models in a straightforward way. READ MORE
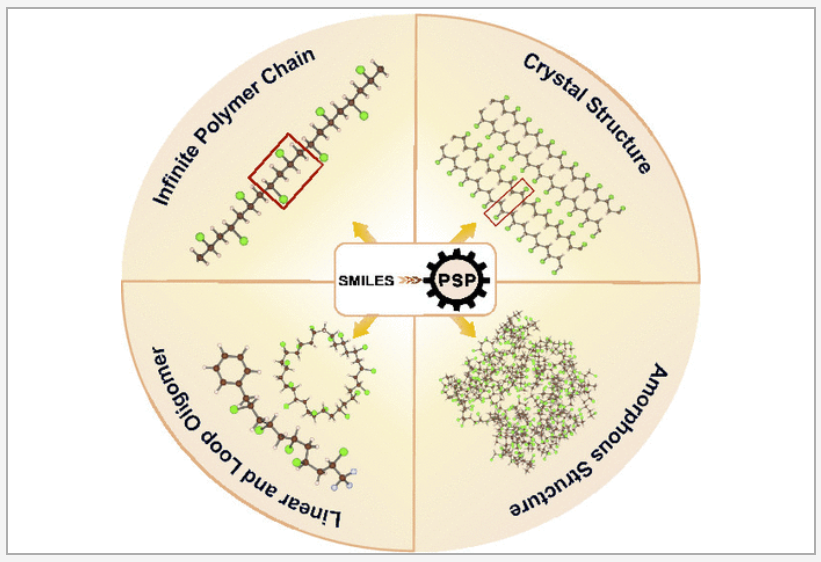
Three-dimensional atomic-level models of polymers are the starting points for physics-based simulation studies. A capability to generate reasonable initial structural models is highly desired for this purpose. We have developed a python toolkit, namely, polymer structure predictor (PSP), to generate a hierarchy of polymer models, ranging from oligomers to infinite chains to crystals to amorphous models, using a simplified molecular-input line-entry system (SMILES) string of the polymer repeat unit as the primary input. This toolkit allows users to tune several parameters to manage the quality and scale of models and computational cost. The output structures and accompanying force field (GAFF2/OPLS-AA) parameter files can be used for downstream ab initio and molecular dynamics simulations. The PSP package includes a Colab notebook where users can go through several examples, building their own models, visualizing them, and downloading them for later use. The PSP toolkit, being a first of its kind, will facilitate automation in polymer property prediction and design. READ MORE
Reasoning about the future behavior of other agents is critical to safe robot navigation. The multiplicity of plausible futures is further amplified by the uncertainty inherent to agent state estimation from data, including positions, velocities, and semantic class. Forecasting methods, however, typically neglect class uncertainty, conditioning instead only on the agent's most likely class, even though perception models often return full class distributions. To exploit this information, we present HAICU, a method for heterogeneous-agent trajectory forecasting that explicitly incorporates agents' class probabilities. We additionally present PUP, a new challenging real-world autonomous driving dataset, to investigate the impact of Perceptual Uncertainty in Prediction. It contains challenging crowded scenes with unfiltered agent class probabilities that reflect the long-tail of current state-of-the-art perception systems. We demonstrate that incorporating class probabilities in trajectory forecasting significantly improves performance in the face of uncertainty, and enables new forecasting capabilities such as counterfactual predictions. READ MORE