Featured Publications
All Publications
TRI Authors: W. Kehl, A. Bhargava, A. Gaidon
All Authors: S. Zakharov, W. Kehl, A. Bhargava, A. Gaidon
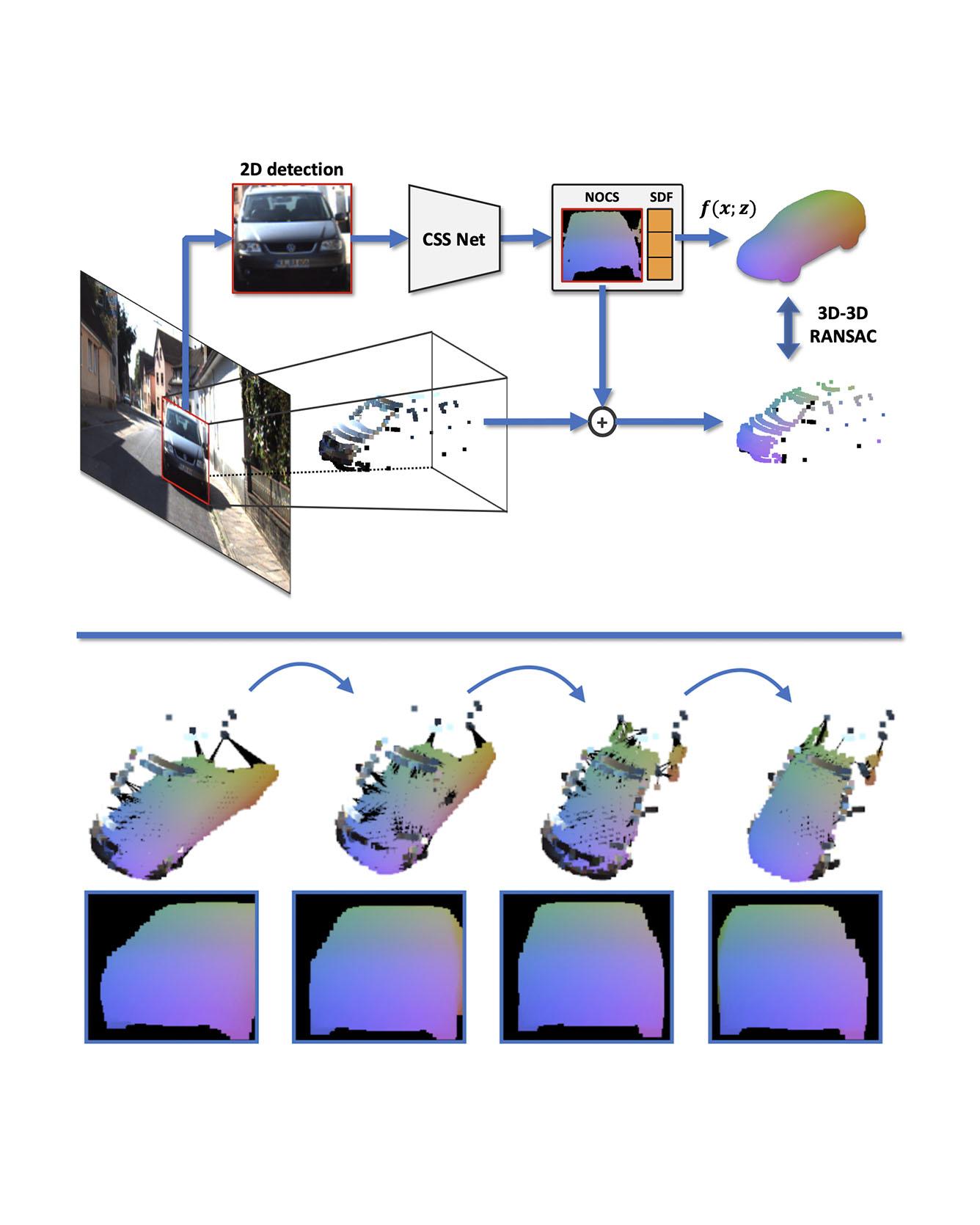
We present an automatic annotation pipeline to recover 9D cuboids and 3D shapes from pre-trained off-the-shelf 2D detectors and sparse LIDAR data. Our autolabeling method solves an ill-posed inverse problem by considering learned shape priors and optimizing geometric and physical parameters. To address this challenging problem, we apply a novel differentiable shape renderer to signed distance fields (SDF), leveraged together with normalized object coordinate spaces (NOCS). Initially trained on synthetic data to predict shape and coordinates, our method uses these predictions for projective and geometric alignment over real samples. Moreover, we also propose a curriculum learning strategy, iteratively retraining on samples of increasing difficulty in subsequent self-improving annotation rounds. Our experiments on the KITTI3D dataset show that we can recover a substantial amount of accurate cuboids, and that these autolabels can be used to train 3D vehicle detectors with state-of-the-art results. Read More
Citation: Zakharov, Sergey, Wadim Kehl, Arjun Bhargava, and Adrien Gaidon. "Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors." CVPR, 2020.
TRI Authors: V. Guizilini, R. Ambrus, S. Pillai, A. Raventos, A. Gaidon
All Authors: V. Guizilini, R. Ambrus, S. Pillai, A. Raventos, A. Gaidon
Although cameras are ubiquitous, robotic platforms typically rely on active sensors like LiDAR for direct 3D perception. In this work, we propose a novel self-supervised monocular depth estimation method combining geometry with a new deep network, PackNet, learned only from unlabeled monocular videos. Our architecture leverages novel symmetrical packing and unpacking blocks to jointly learn to compress and decompress detail-preserving representations using 3D convolutions. Although self-supervised, our method outperforms other self, semi, and fully supervised methods on the KITTI benchmark. The 3D inductive bias in PackNet enables it to scale with input resolution and number of parameters without overfitting, generalizing better on out-of-domain data such as the NuScenes dataset. Furthermore, it does not require large-scale supervised pretraining on ImageNet and can run in real-time. Finally, we release DDAD (Dense Depth for Automated Driving), a new urban driving dataset with more challenging and accurate depth evaluation, thanks to longer-range and denser ground-truth depth generated from high-density LiDARs mounted on a fleet of self-driving cars operating world-wide. Read More
Citation: Guizilini, Vitor, Rares Ambrus, Sudeep Pillai, and Adrien Gaidon. "Packnet-sfm: 3d packing for self-supervised monocular depth estimation." CVPR, 2020,

TRI Authors: KH Lee,A. Gaidon
All Authors: B. Liu, E. Adeli, Z. Cao, KH Lee, A. Shenoi, A. Gaidon, JC Niebles
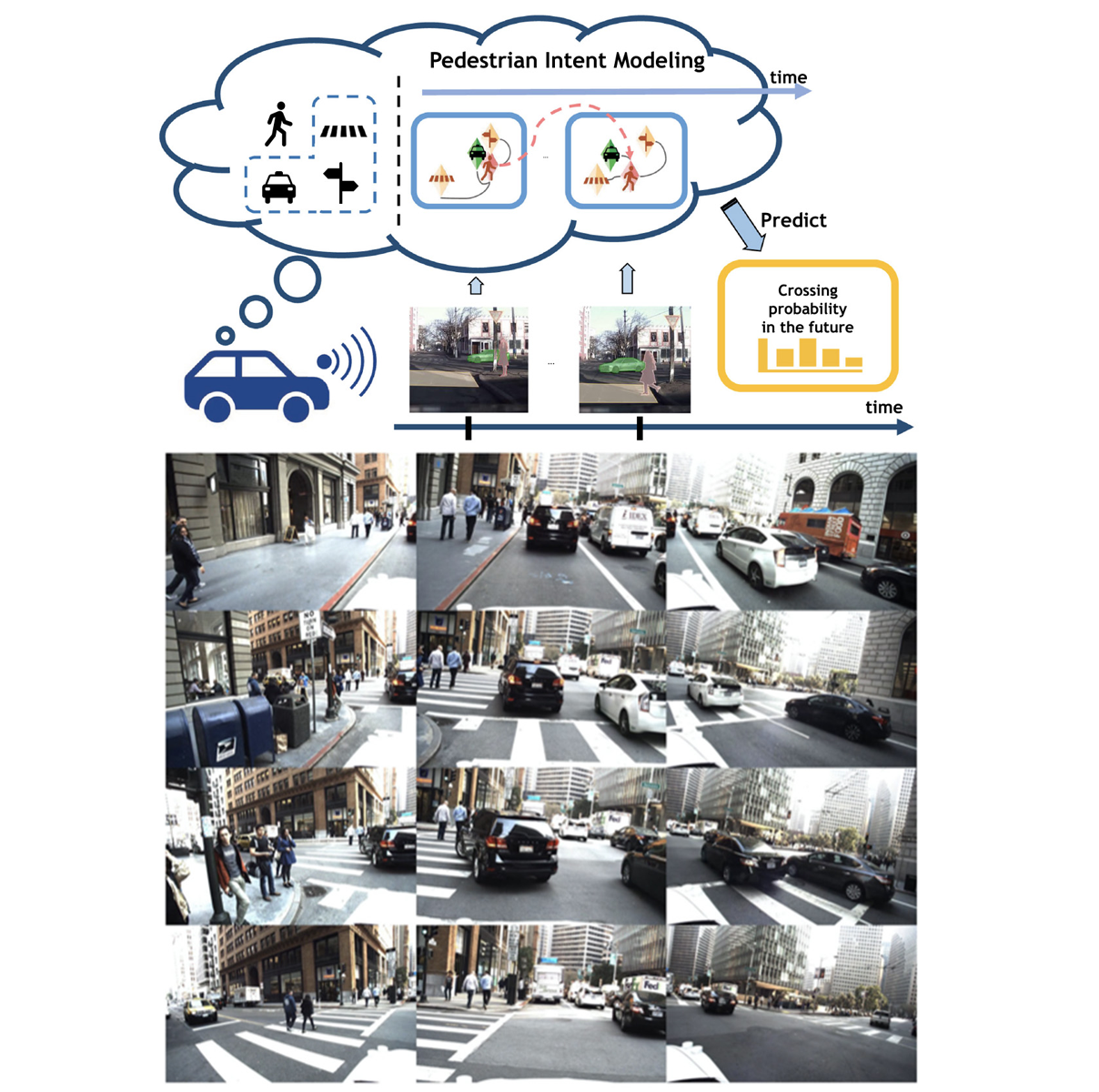
Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this letter, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomous-driving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform baseline and previous work. Read More
Citation: Liu, Bingbin, Ehsan Adeli, Zhangjie Cao, Kuan-Hui Lee, Abhijeet Shenoi, Adrien Gaidon, and Juan Carlos Niebles. "Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction." IEEE Robotics and Automation Letters 5, no. 2 (2020): 3485-3492.
TRI Authors: Vitor Guizilini, Jie Li, Rares Ambrus, Adrien Gaidon
All Authors: Vitor Guizilini, Rui Hou, Jie Li, Rares Ambrus, Adrien Gaidon Self-supervised learning is showing great promise for monocular depth estimation, using geometry as the only source of supervision. Depth networks are indeed capable of learning representations that relate visual appearance to 3D properties by implicitly leveraging category-level patterns. In this work we investigate how to leverage more directly this semantic structure to guide geometric representation learning, while remaining in the self-supervised regime. Instead of using semantic labels and proxy losses in a multi-task approach, we propose a new architecture leveraging fixed pretrained semantic segmentation networks to guide self-supervised representation learning via pixel-adaptive convolutions. Furthermore, we propose a two-stage training process to overcome a common semantic bias on dynamic objects via resampling. Our method improves upon the state of the art for self-supervised monocular depth prediction over all pixels, fine-grained details, and per semantic categories. Read more
Citation: Guizilini, Vitor, Rui Hou, Jie Li, Rares Ambrus, and Adrien Gaidon. "Semantically-Guided Representation Learning for Self-Supervised Monocular Depth." ICLR 2020

TRI Authors: Kuppuswamy, Naveen*, Alex Alspach, Avinash Uttamchandani, Sam Creasey, Takuya Ikeda, Russ Tedrake.
All Authors: Kuppuswamy, Naveen*, Alex Alspach, Avinash Uttamchandani, Sam Creasey, Takuya Ikeda, Russ Tedrake.
Citation: Kuppuswamy, Naveen*, Alex Alspach, Avinash Uttamchandani, Sam Creasey, Takuya Ikeda, Russ Tedrake. "Soft-bubbles grippers for robust and perceptive manipulation." 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems.

TRI Authors: Naveen Kuppuswamy, Alejandro Castro, Calder Phillips-Grafflin, Alex Alspach, Russ Tedrake
All Authors: Naveen Kuppuswamy, Alejandro Castro, Calder Phillips-Grafflin, Alex Alspach, Russ Tedrake
Modeling deformable contact is a well-known problem in soft robotics and is particularly challenging for compliant interfaces that permit large deformations. We present a model for the behavior of a highly deformable dense geometry sensor in its interaction with objects; the forward model predicts the elastic deformation of a mesh given the pose and geometry of a contacting rigid object. We use this model to develop a fast approximation to solve the inverse problem: estimating the contact patch when the sensor is deformed by arbitrary objects. This inverse model can be easily identified through experiments and is formulated as a sparse Quadratic Program (QP) that can be solved efficiently online. The proposed model serves as the first stage of a pose estimation pipeline for robot manipulation. We demonstrate the proposed inverse model through real-time estimation of contact patches on a contact-rich manipulation problem in which oversized fingers screw a nut onto a bolt, and as part of a complete pipeline for pose-estimation and tracking based on the Iterative Closest Point (ICP) algorithm. Our results demonstrate a path towards realizing soft robots with highly compliant surfaces that perform complex real-world manipulation tasks. Read More
Citation: Kuppuswamy, Naveen, Alejandro Castro, Calder Phillips-Grafflin, Alex Alspach, and Russ Tedrake. "Fast model-based contact patch and pose estimation for highly deformable dense-geometry tactile sensors." IEEE Robotics and Automation Letters (2019).

TRI Authors: Alejandro Castro, Ante Qu (intern), Naveen Kuppuswamy, Alex Alspach, Michael Sherman
All Authors: Alejandro Castro, Ante Qu, Naveen Kuppuswamy, Alex Alspach, Michael Sherman
Multibody simulation with frictional contact has been a challenging subject of research for the past thirty years. Rigidbody assumptions are commonly used to approximate the physics of contact, and together with Coulomb friction, lead to challengingto-solve nonlinear complementarity problems (NCP). On the other hand, robot grippers often introduce significant compliance. Compliant contact, combined with regularized friction, can be modeled entirely with ODEs, avoiding NCP solves. Unfortunately, regularized friction introduces high-frequency stiff dynamics and even implicit methods struggle with these systems, especially during slip-stick transitions. To improve the performance of implicit integration for these systems we introduce a Transition-Aware Line Search (TALS), which greatly improves the convergence of the Newton-Raphson iterations performed by implicit integrators. We find that TALS works best with semi-implicit integration, but that the explicit treatment of normal compliance can be problematic. To address this, we develop a Transition-Aware Modified SemiImplicit (TAMSI) integrator that has similar computational cost to semi-implicit methods but implicitly couples compliant contact forces, leading to a more robust method. We evaluate the robustness, accuracy and performance of TAMSI and demonstrate our approach alongside relevant sim-to-real manipulation tasks. Read More
Citation: Castro, Alejandro M., Ante Qu, Naveen Kuppuswamy, Alex Alspach, and Michael Sherman. "A Transition-Aware Method for the Simulation of Compliant Contact with Regularized Friction." IEEE Robotics and Automation Letters 5, no. 2 (2020): 1859-1866.

TRI Authors: Adrien Gaidon, Nikos Arechiga
All Authors: Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, Tengyu Ma
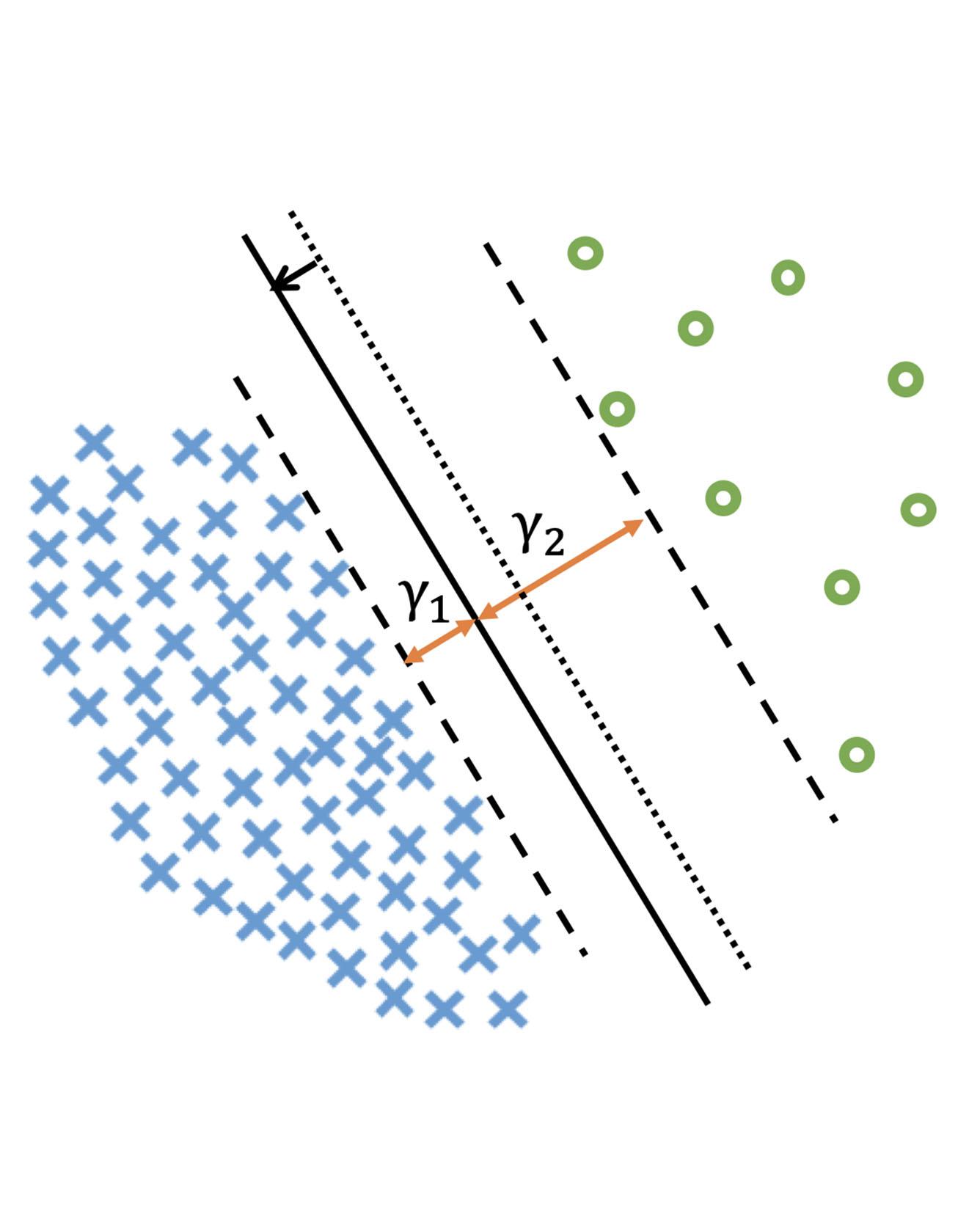
Deep learning algorithms can fare poorly when the training dataset suffers from heavy class-imbalance but the testing criterion requires good generalization on less frequent classes. We design two novel methods to improve performance in such scenarios. First, we propose a theoretically-principled label-distribution-aware margin (LDAM) loss motivated by minimizing a margin-based generalization bound. This loss replaces the standard cross-entropy objective during training and can be applied with prior strategies for training with class-imbalance such as re-weighting or re-sampling. Second, we propose a simple, yet effective, training schedule that defers re-weighting until after the initial stage, allowing the model to learn an initial representation while avoiding some of the complications associated with re-weighting or re-sampling. We test our methods on several benchmark vision tasks including the real-world imbalanced dataset iNaturalist 2018. Our experiments show that either of these methods alone can already improve over existing techniques and their combination achieves even better performance gains. Read More
Citation: Cao, Kaidi, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. "Learning imbalanced datasets with label-distribution-aware margin loss." In Advances in Neural Information Processing Systems, pp. 1565-1576. 2019.
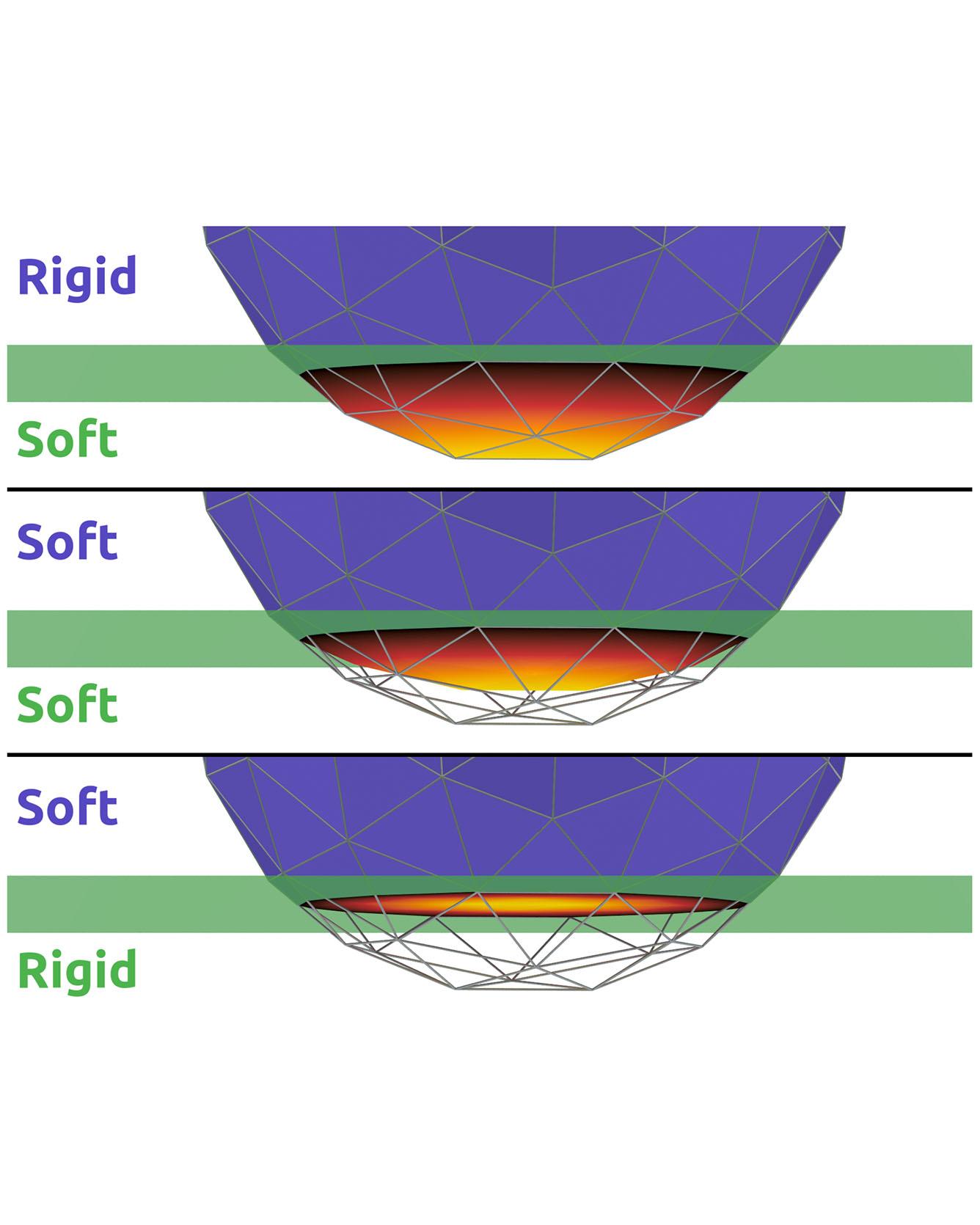
TRI Authors: Evan Drumwright, Michael Sherman All Authors: Elandt, Ryan, Evan Drumwright, Michael Sherman, and Andy Ruina We introduce an approximate model for predicting the net contact wrench between nominally rigid objects for use in simulation, control, and state estimation. The model combines and generalizes two ideas: a bed of springs (an "elastic foundation") and hydrostatic pressure. In this model, continuous pressure fields are computed offline for the interior of each nominally rigid object. Unlike hydrostatics or elastic foundations, the pressure fields need not satisfy mechanical equilibrium conditions. When two objects nominally overlap, a contact surface is defined where the two pressure fields are equal. This static pressure is supplemented with a dissipative rate-dependent pressure and friction to determine tractions on the contact surface. The contact wrench between pairs of objects is an integral of traction contributions over this surface. The model evaluates much faster than elasticity-theory models, while showing the essential trends of force, moment, and stiffness increase with contact load. It yields continuous wrenches even for non-convex objects and coarse meshes. The method shows promise as sufficiently fast, accurate, and robust for design-in-simulation of robot controllers. Read moreCitation: Elandt, Ryan, Evan Drumwright, Michael Sherman, and Andy Ruina. "A pressure field model for fast, robust approximation of net contact force and moment between nominally rigid objects." IROS 2019 arXiv preprint arXiv:1904.11433 (2019).
TRI Author: Hongkai Dai
All Authors: Bernardo Aceituno-Cabezas, Hongkai Dai, Alberto Rodriguez
Caging is a promising tool which allows a robot to manipulate an object without directly reasoning about the contact dynamics involved. Furthermore, caging also provides useful guarantees in terms of robustness to uncertainty, and often serves as a way-point to a grasp. Unfortunately, previous work on caging is often based on computational geometry or discrete topology tools, causing restriction on gripper geometry, and difficulty on integration into larger manipulation frameworks. In this paper, we develop a convex-combinatorial model to characterize caging from an optimization perspective. More specifically, we study the configuration space of the object, where the fingers act as obstacles that enclose the configuration of the object. The convex-combinatorial nature of this approach provides guarantees on optimality, convergence and scalability, and its optimization nature makes it adaptable for further applications on robot manipulation tasks. Read More
Citation: Aceituno-Cabezas, Bernardo, Hongkai Dai, and Alberto Rodriguez. "A Convex-Combinatorial Model for Planar Caging." arXiv preprint arXiv:1809.06427 (2018).