Featured Publications
All Publications
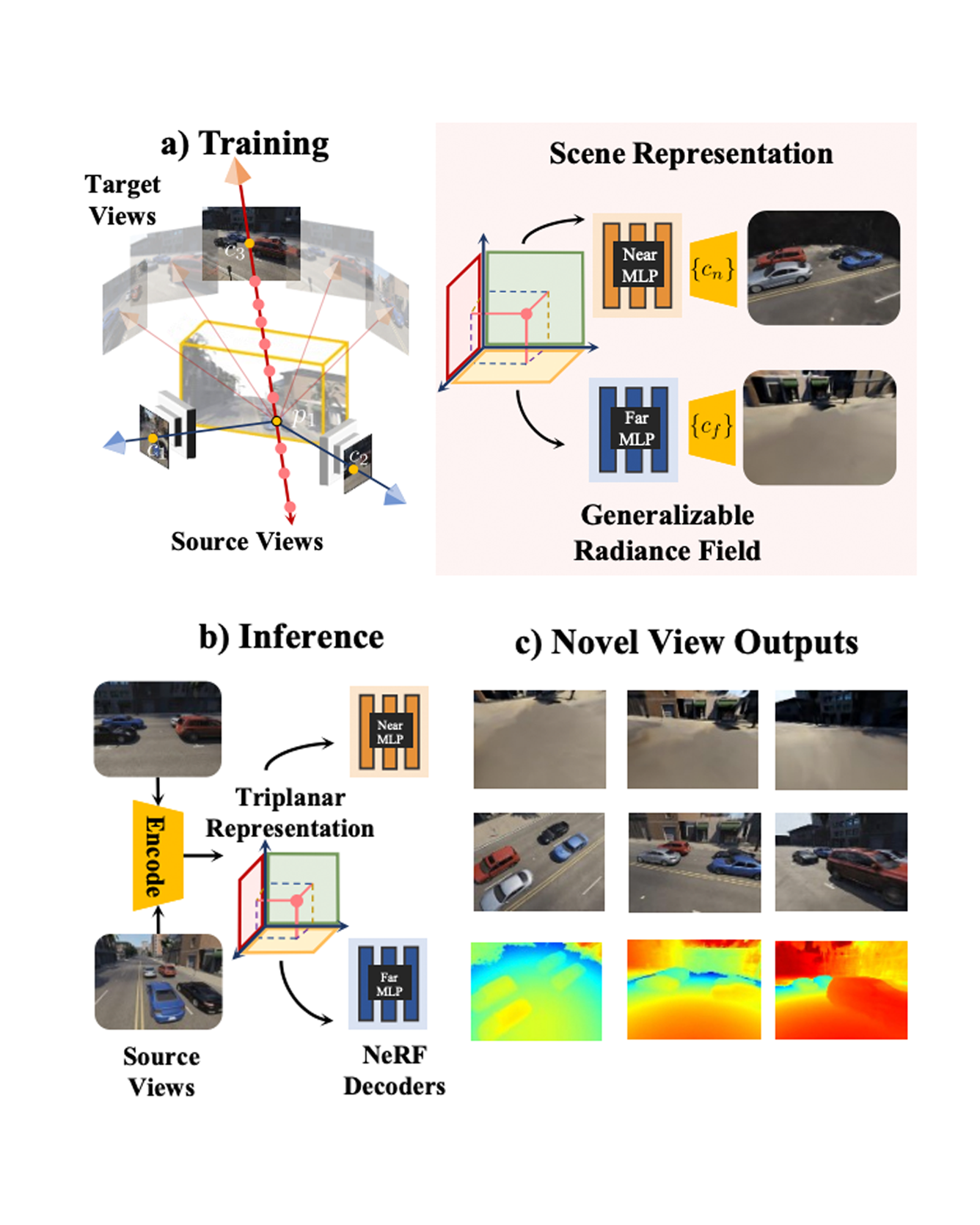
Recent implicit neural representations have shown great results for novel view synthesis. However, existing methods require expensive per-scene optimization from many views hence limiting their application to real-world unbounded urban settings where the objects of interest or backgrounds are observed from very few views. To mitigate this challenge, we introduce a new approach called NeO 360, Neural fields for sparse view synthesis of outdoor scenes. NeO 360 is a generalizable method that reconstructs 360° scenes from a single or a few posed RGB images. The essence of our approach is in capturing the distribution of complex real-world outdoor 3D scenes and using a hybrid image-conditional triplanar representation that can be queried from any world point. Our representation combines the best of both voxel-based and bird's-eye-view (BEV) representations and is more effective and expressive than each. NeO 360's representation allows us to learn from a large collection of unbounded 3D scenes while offering generalizability to new views and novel scenes from as few as a single image during inference. We demonstrate our approach on the proposed challenging 360° unbounded dataset, called NeRDS 360, and show that NeO 360 outperforms state-of-the-art generalizable methods for novel view synthesis while also offering editing and composition capabilities. Project page. READ MORE
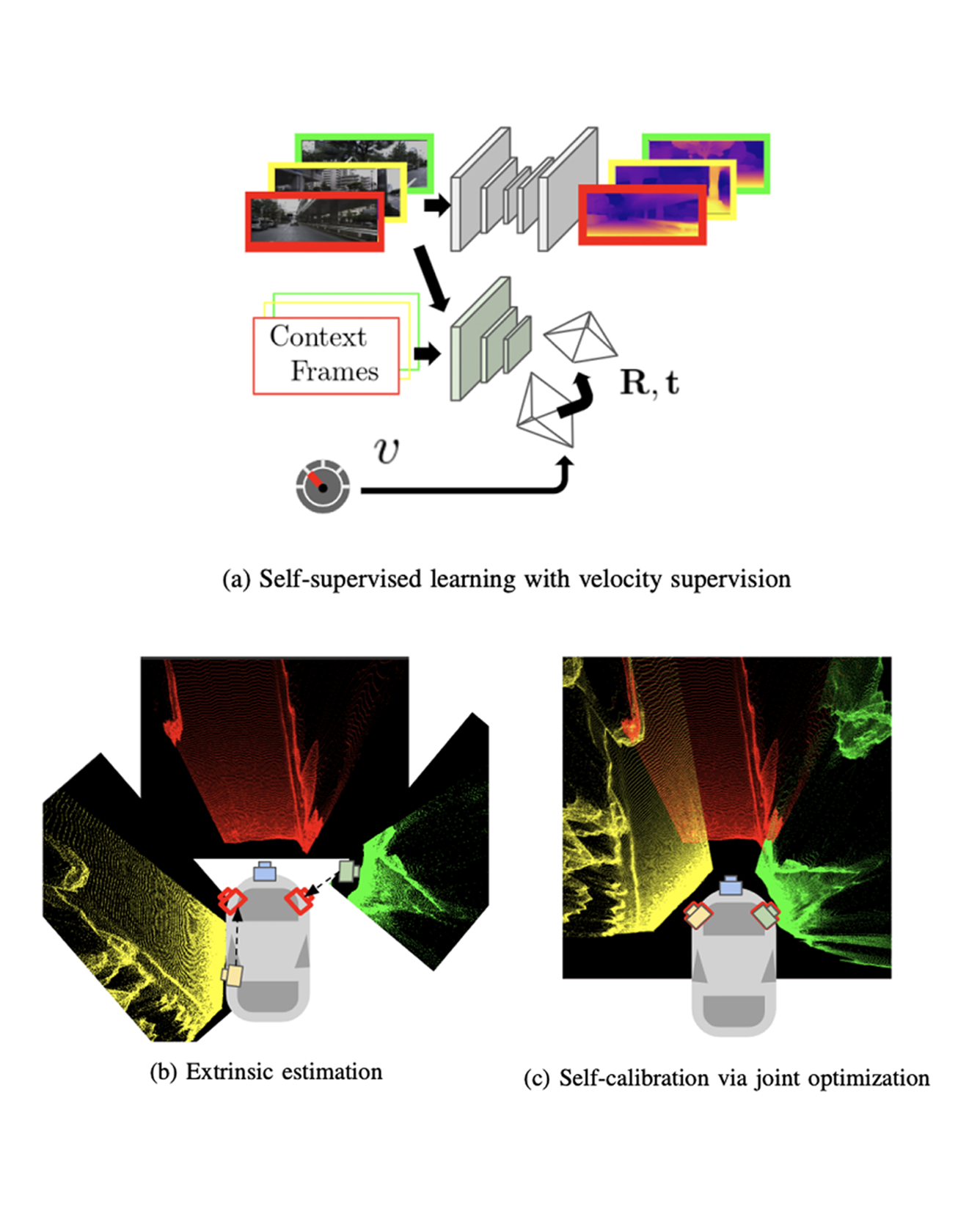
Autonomous vehicles and robots need to operate over a wide variety of scenarios in order to complete tasks efficiently and safely. Multi-camera self-supervised monocular depth estimation from videos is a promising way to reason about the environment, as it generates metrically scaled geometric predictions from visual data without requiring additional sensors. However, most works assume well-calibrated extrinsics to fully leverage this multi-camera setup, even though accurate and efficient calibration is still a challenging problem. In this work, we introduce a novel method for extrinsic calibration that builds upon the principles of self-supervised monocular depth and ego-motion learning. Our proposed curriculum learning strategy uses monocular depth and pose estimators with velocity supervision to estimate extrinsics, and then jointly learns extrinsic calibration along with depth and pose for a set of overlapping cameras rigidly attached to a moving vehicle. Experiments on a benchmark multi-camera dataset (DDAD) demonstrate that our method enables self-calibration in various scenes robustly and efficiently compared to a traditional vision-based pose estimation pipeline. Furthermore, we demonstrate the benefits of extrinsics self-calibration as a way to improve depth prediction via joint optimization. READ MORE
Monocular depth estimation is scale-ambiguous, and thus requires scale supervision to produce metric predictions. Even so, the resulting models will be geometry-specific, with learned scales that cannot be directly transferred across domains. Because of that, recent works focus instead on relative depth, eschewing scale in favor of improved up-to-scale zero-shot transfer. In this work we introduce ZeroDepth, a novel monocular depth estimation framework capable of predicting metric scale for arbitrary test images from different domains and camera parameters. This is achieved by (i) the use of input-level geometric embeddings that enable the network to learn a scale prior over objects; and (ii) decoupling the encoder and decoder stages, via a variational latent representation that is conditioned on single frame information. We evaluated ZeroDepth targeting both outdoor (KITTI, DDAD, nuScenes) and indoor (NYUv2) benchmarks, and achieved a new state-of-the-art in both settings using the same pre-trained model, outperforming methods that train on in-domain data and require test-time scaling to produce metric estimates. READ MORE

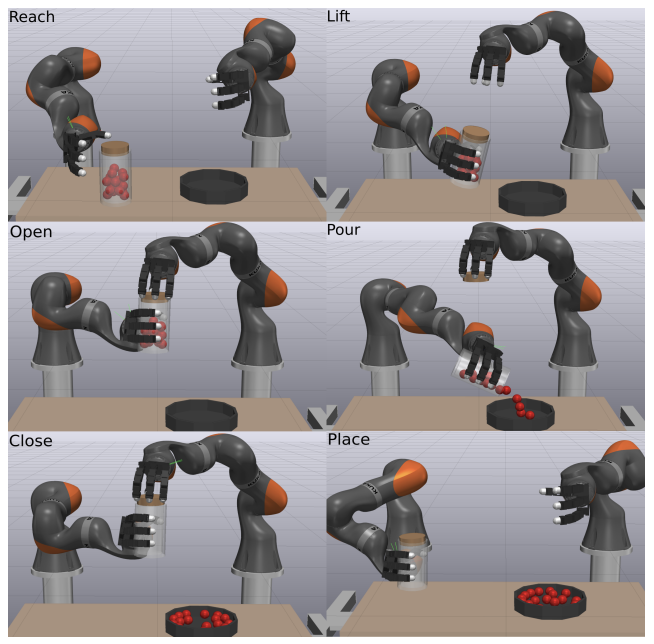
This paper introduces Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process. We benchmark Diffusion Policy across 12 different tasks from 4 different robot manipulation benchmarks and find that it consistently outperforms existing state-of-the-art robot learning methods with an average improvement of 46.9%. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respect to this gradient field during inference via a series of stochastic Langevin dynamics steps. We find that the diffusion formulation yields powerful advantages when used for robot policies, including gracefully handling multimodal action distributions, being suitable for high-dimensional action spaces, and exhibiting impressive training stability. To fully unlock the potential of diffusion models for visuomotor policy learning on physical robots, this paper presents a set of key technical contributions including the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer. We hope this work will help motivate a new generation of policy learning techniques that are able to leverage the powerful generative modeling capabilities of diffusion models. Code, data, and training details will be publicly available. READ MORE

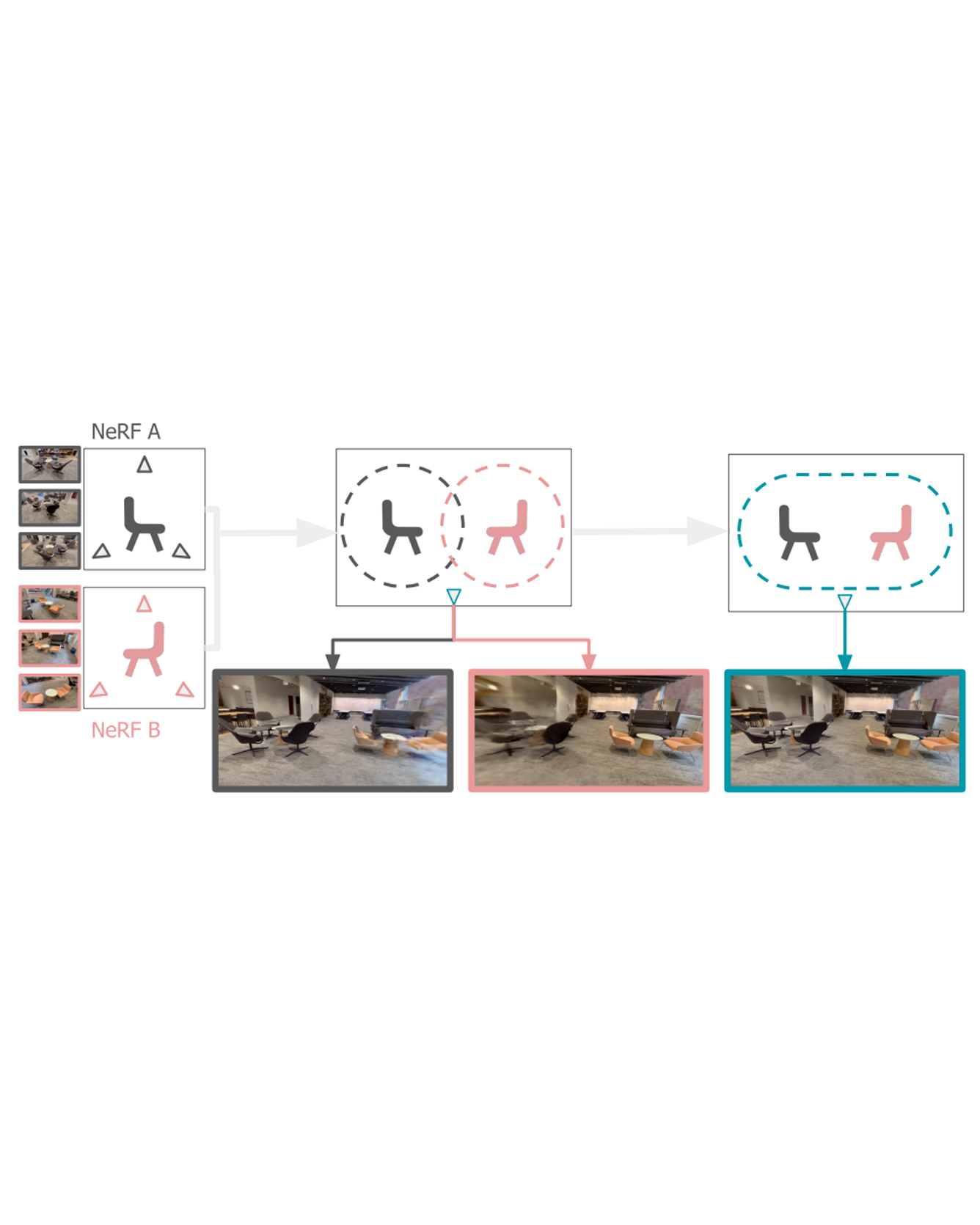
A practical benefit of implicit visual representations like Neural Radiance Fields (NeRFs) is their memory efficiency: large scenes can be efficiently stored and shared as small neural nets instead of collections of images. However, operating on these implicit visual data structures requires extending classical image-based vision techniques (e.g., registration, blending) from image sets to neural fields. Towards this goal, we propose NeRFuser, a novel architecture for NeRF registration and blending that assumes only access to pre-generated NeRFs, and not the potentially large sets of images used to generate them. We propose registration from re-rendering, a technique to infer the transformation between NeRFs based on images synthesized from individual NeRFs. For blending, we propose sample-based inverse distance weighting to blend visual information at the ray-sample level. We evaluate NeRFuser on public benchmarks and a self-collected object-centric indoor dataset, showing the robustness of our method, including to views that are challenging to render from the individual source NeRFs. READ MORE
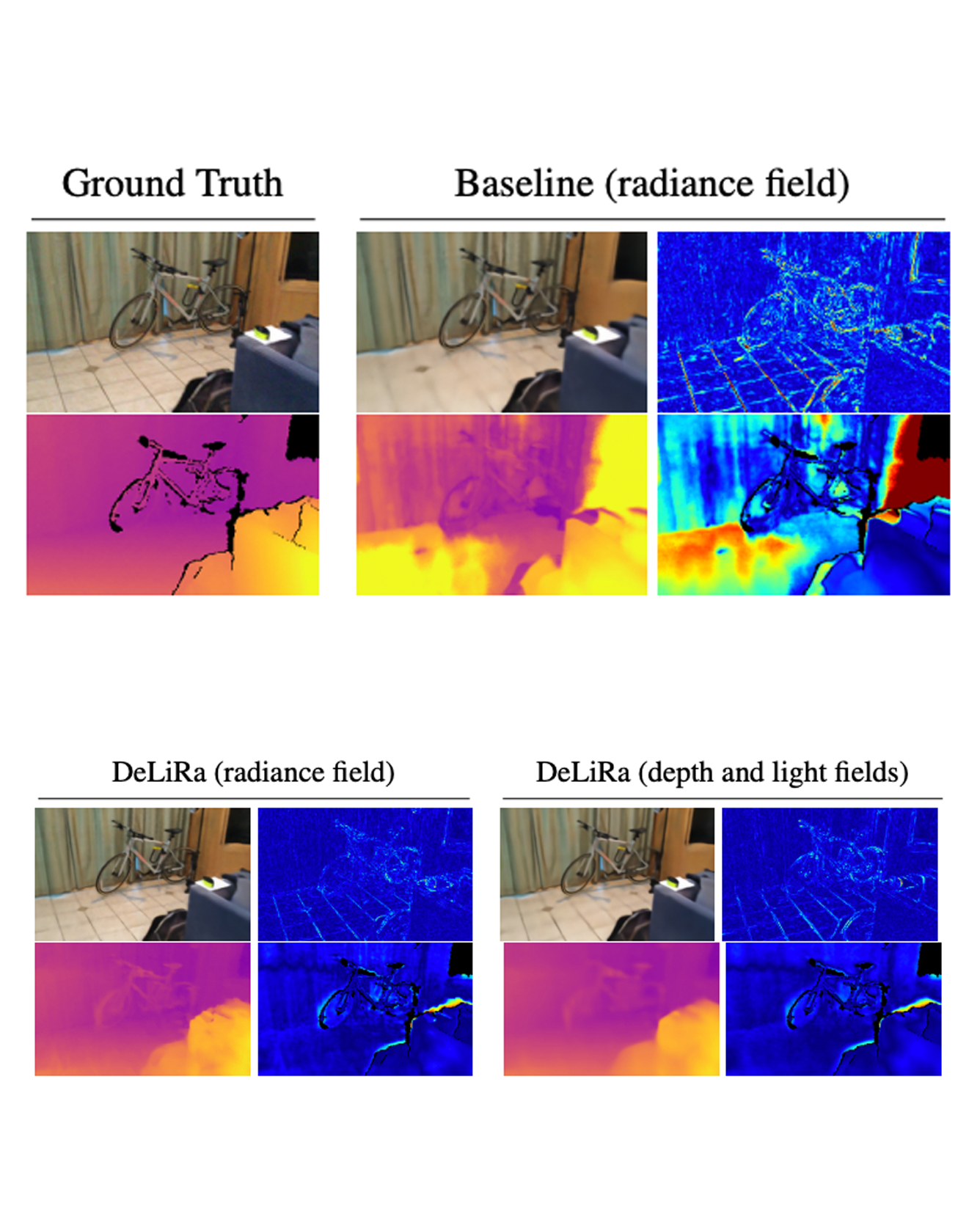
Differentiable volumetric rendering is a powerful paradigm for 3D reconstruction and novel view synthesis. However, standard volume rendering approaches struggle with degenerate geometries in the case of limited viewpoint diversity, a common scenario in robotics applications. In this work, we propose to use the multi-view photometric objective from the self-supervised depth estimation literature as a geometric regularizer for volumetric rendering, significantly improving novel view synthesis without requiring additional information. Building upon this insight, we explore the explicit modeling of scene geometry using a generalist Transformer, jointly learning a radiance field as well as depth and light fields with a set of shared latent codes. We demonstrate that sharing geometric information across tasks is mutually beneficial, leading to improvements over single-task learning without an increase in network complexity. Our DeLiRa architecture achieves state-of-the-art results on the ScanNet benchmark, enabling high quality volumetric rendering as well as real-time novel view and depth synthesis in the limited viewpoint diversity setting. READ MORE
We present a novel convex formulation that models rigid and deformable bodies coupled through frictional contact. The formulation incorporates a new corotational material model with positive semi-definite Hessian, which allows us to extend our previous work on the convex formulation of compliant contact to model large body deformations. We rigorously characterize our approximations and present implementation details. With proven global convergence, effective warm-start, the ability to take large time steps, and specialized sparse algebra, our method runs robustly at interactive rates. We provide validation results and performance metrics on challenging simulations relevant to robotics applications. Our method is made available in the opensource robotics toolkit Drake. READ MORE
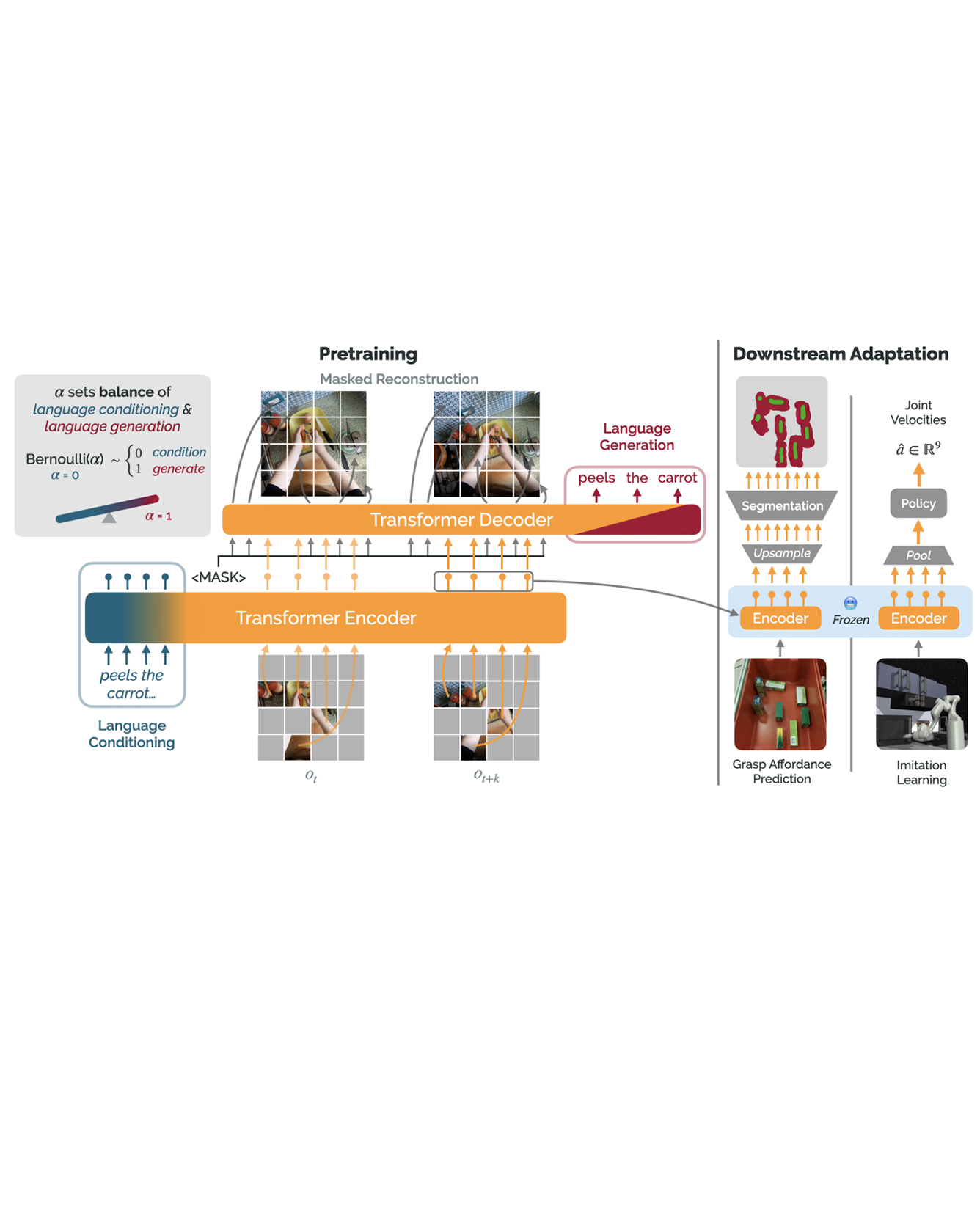
Recent work in visual representation learning for robotics demonstrates the viability of learning from large video datasets of humans performing everyday tasks. Leveraging methods such as masked autoencoding and contrastive learning, these representations exhibit strong transfer to policy learning for visuomotor control. But, robot learning encompasses a diverse set of problems beyond control including grasp affordance prediction, language-conditioned imitation learning, and intent scoring for human-robot collaboration, amongst others. First, we demonstrate that existing representations yield inconsistent results across these tasks: masked autoencoding approaches pick up on low-level spatial features at the cost of high-level semantics, while contrastive learning approaches capture the opposite. We then introduce Voltron, a framework for language-driven representation learning from human videos and associated captions. Voltron trades off language-conditioned visual reconstruction to learn low-level visual patterns, and visually-grounded language generation to encode high-level semantics. We also construct a new evaluation suite spanning five distinct robot learning problems – a unified platform for holistically evaluating visual representations for robotics. Through comprehensive, controlled experiments across all five problems, we find that Voltron’s language-driven representations outperform the prior state-of-the-art, especially on targeted problems requiring higher-level features. READ MORE
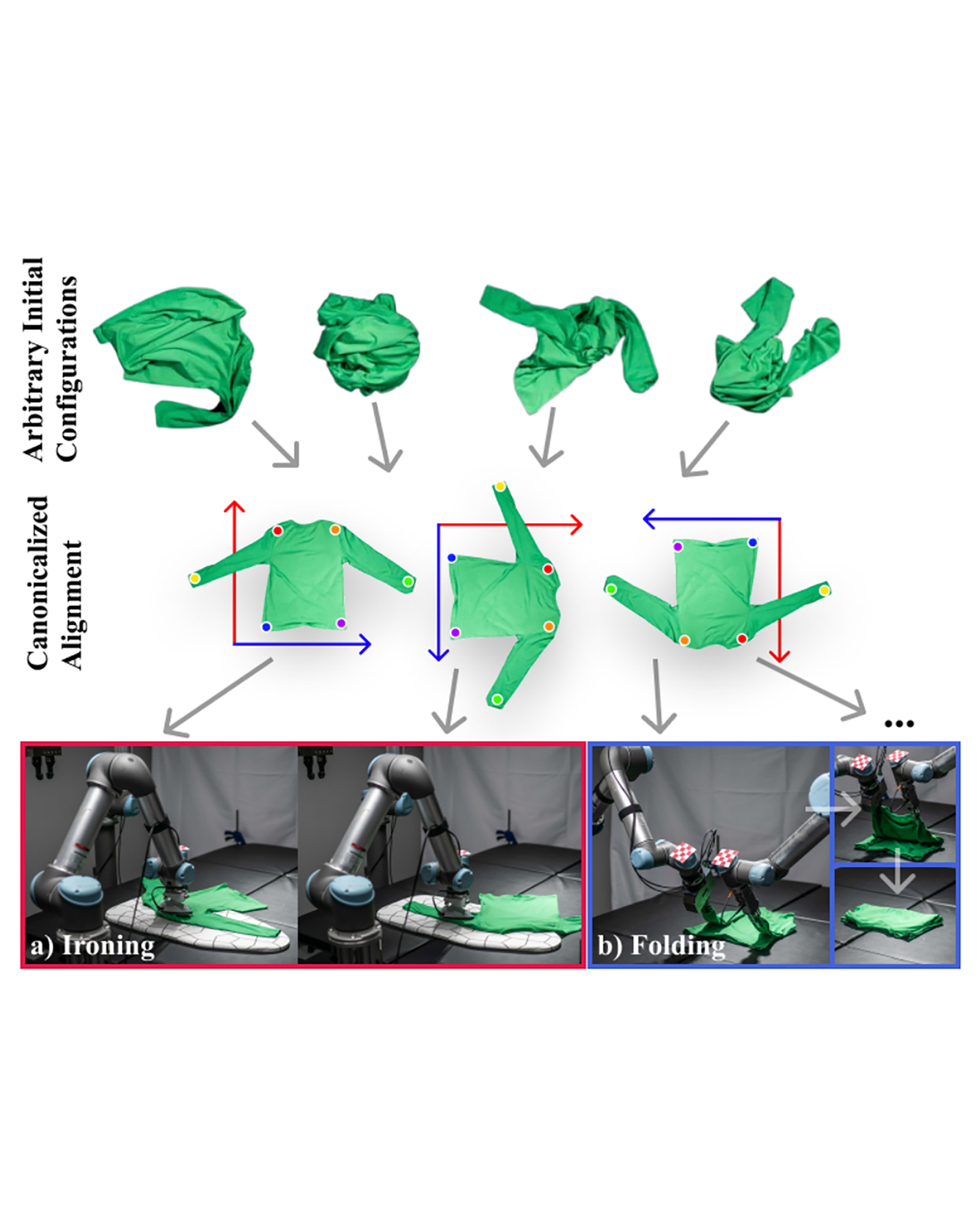
Automating garment manipulation is challenging due to extremely high variability in object configurations. To reduce this intrinsic variation, we introduce the task of “canonicalized-alignment” that simplifies downstream applications by reducing the possible garment configurations. This task can be considered as “cloth state funnel” that manipulates arbitrarily configured clothing items into a predefined deformable configuration (i.e. canonicalization) at an appropriate rigid pose (i.e. alignment). In the end, the cloth items will result in a compact set of structured and highly visible configurations – which are desirable for downstream manipulation skills. To enable this task, we propose a novel canonicalized-alignment objective that effectively guides learning to avoid adverse local minima during learning. Using this objective, we learn a multi-arm, multi-primitive policy that strategically chooses between dynamic flings and quasi-static pick and place actions to achieve efficient canonicalized alignment. We evaluate this approach on a real-world ironing and folding system that relies on this learned policy as the common first step. Empirically, we demonstrate that our task-agnostic canonicalized-alignment can enable even simple manually-designed policies to work well where they were previously inadequate, thus bridging the gap between automated non-deformable manufacturing and deformable manipulation. READ MORE
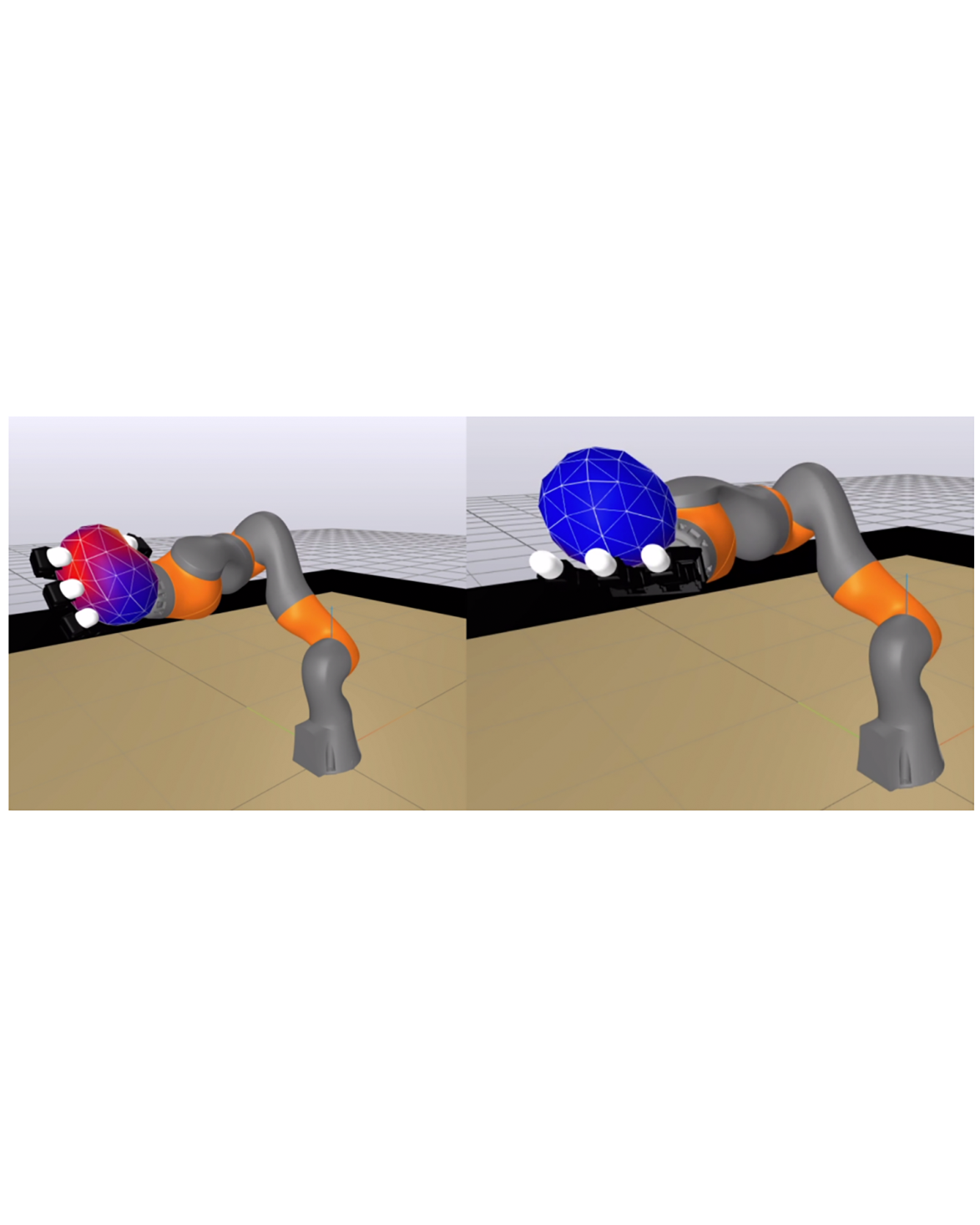
We present a convex formulation of compliant frictional contact and a robust, performant method to solve it in practice. By analytically eliminating contact constraints, we obtain an unconstrained convex problem. Our solver has proven global convergence and warm-starts effectively, enabling simulation at interactive rates. We develop compact analytical expressions of contact forces allowing us to describe our model in clear physical terms and to rigorously characterize our approximations. Moreover, this enables us not only to model point contact, but also to incorporate sophisticated models of compliant contact patches. Our time stepping scheme includes the midpoint rule, which we demonstrate achieves second order accuracy even with frictional contact. We introduce a number of accuracy metrics and show our method outperforms existing commercial and open source alternatives without sacrificing accuracy. Finally, we demonstrate robust simulation of robotic manipulation tasks at interactive rates, with accurately resolved stiction and contact transitions, as required for meaningful sim-to-real transfer. Our method is implemented in the open source robotics toolkit Drake. READ MORE