Featured Publications
All Publications
Neural fields excel in computer vision and robotics due to their ability to understand the 3D visual world such as inferring semantics, geometry, and dynamics. Given the capabilities of neural fields in densely representing a 3D scene from 2D images, we ask the question: Can we scale their self-supervised pretraining, specifically using masked autoencoders, to generate effective 3D representations from posed RGB images. Owing to the astounding success of extending transformers to novel data modalities, we employ standard 3D Vision Transformers to suit the unique formulation of NeRFs. We leverage NeRF's volumetric grid as a dense input to the transformer, contrasting it with other 3D representations such as pointclouds where the information density can be uneven, and the representation is irregular. Due to the difficulty of applying masked autoencoders to an implicit representation, such as NeRF, we opt for extracting an explicit representation that canonicalizes scenes across domains by employing the camera trajectory for sampling. Our goal is made possible by masking random patches from NeRF's radiance and density grid and employing a standard 3D Swin Transformer to reconstruct the masked patches. In doing so, the model can learn the semantic and spatial structure of complete scenes. We pretrain this representation at scale on our proposed curated posed-RGB data, totaling over 1.8 million images. Once pretrained, the encoder is used for effective 3D transfer learning. Our novel self-supervised pretraining for NeRFs, NeRF-MAE, scales remarkably well and improves performance on various challenging 3D tasks. Utilizing unlabeled posed 2D data for pretraining, NeRF-MAE significantly outperforms self-supervised 3D pretraining and NeRF scene understanding baselines on Front3D and ScanNet datasets with an absolute performance improvement of over 20% AP50 and 8% AP25 for 3D object detection. READ MORE

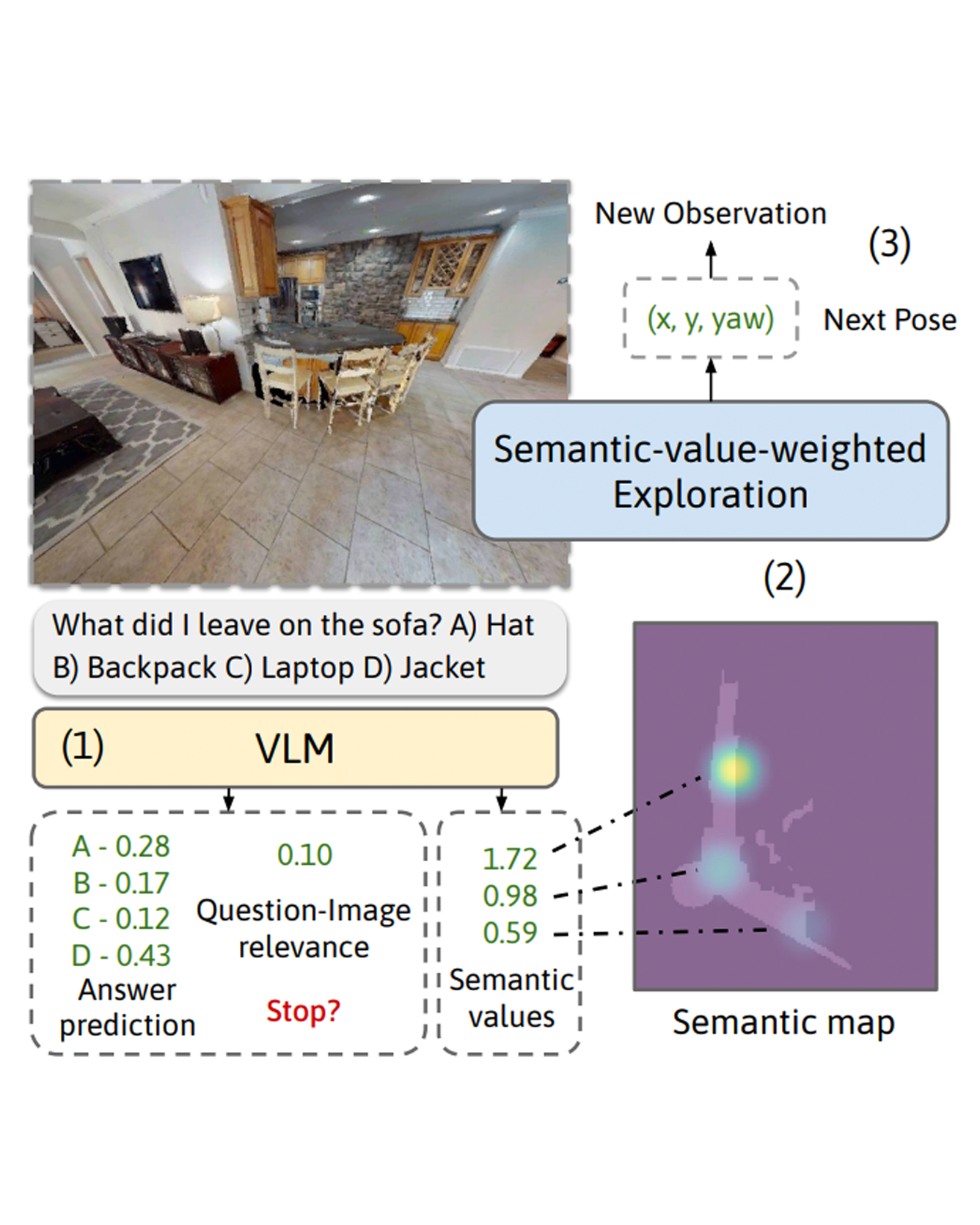
We consider the problem of Embodied Question Answering (EQA), which refers to settings where an embodied agent such as a robot needs to actively explore an environment to gather information until it is confident about the answer to a question. In this work, we leverage the strong semantic reasoning capabilities of large vision-language models (VLMs) to efficiently explore and answer such questions. However, there are two main challenges when using VLMs in EQA: they do not have an internal memory for mapping the scene to be able to plan how to explore over time, and their confidence can be miscalibrated and can cause the robot to prematurely stop exploration or over-explore. We propose a method that first builds a semantic map of the scene based on depth information and via visual prompting of a VLM - leveraging its vast knowledge of relevant regions of the scene for exploration. Next, we use conformal prediction to calibrate the VLM's question answering confidence, allowing the robot to know when to stop exploration - leading to a more calibrated and efficient exploration strategy. To test our framework in simulation, we also contribute a new EQA dataset with diverse, realistic human-robot scenarios and scenes built upon the Habitat-Matterport 3D Research Dataset (HM3D). Both simulated and real robot experiments show our proposed approach improves the performance and efficiency over baselines that do no leverage VLM for exploration or do not calibrate its confidence. READ MORE
We present a 3D shape completion method that recovers the complete geometry of multiple objects in complex scenes from a single RGB-D image. Despite notable advancements in single object 3D shape completion, high-quality reconstructions in highly cluttered real-world multi-object scenes remains a challenge. To address this issue, we propose OctMAE, an architecture that leverages an Octree U-Net and a latent 3D MAE to achieve high-quality and near real-time multi-object shape completion through both local and global geometric reasoning. Because a naïve 3D MAE can be computationally intractable and memory intensive even in the latent space, we introduce a novel occlusion masking strategy and adopt 3D rotary embeddings, which significantly improves the runtime and shape completion quality. To generalize to a wide range of objects in diverse scenes, we create a large-scale photorealistic dataset, featuring a diverse set of 12K 3D object models from the Objaverse dataset which are rendered in multi-object scenes with physics-based positioning. Our method outperforms the current state-of-the-art on both synthetic and real-world datasets and demonstrates a strong zero-shot capability. READ MORE

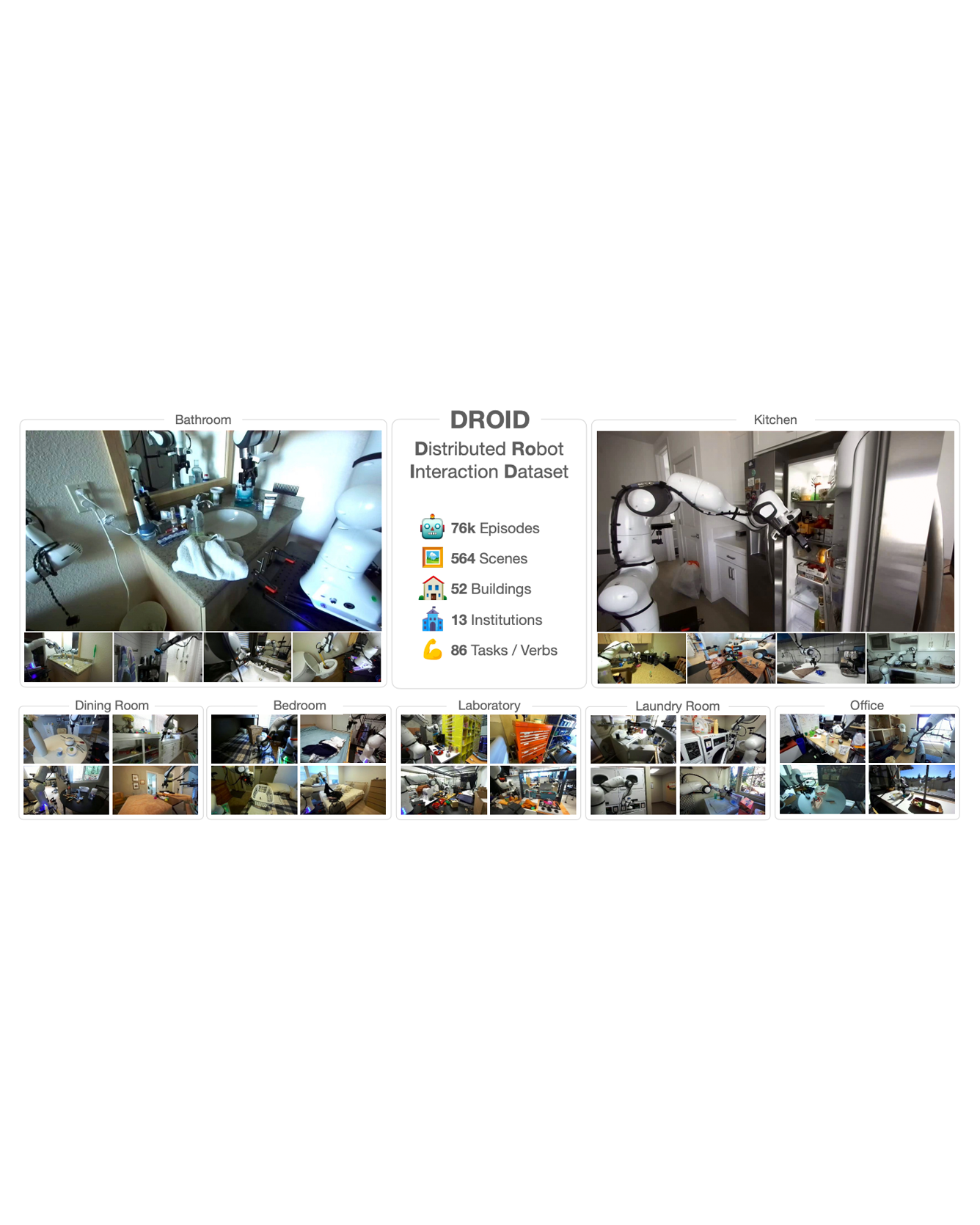
The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup. READ MORE
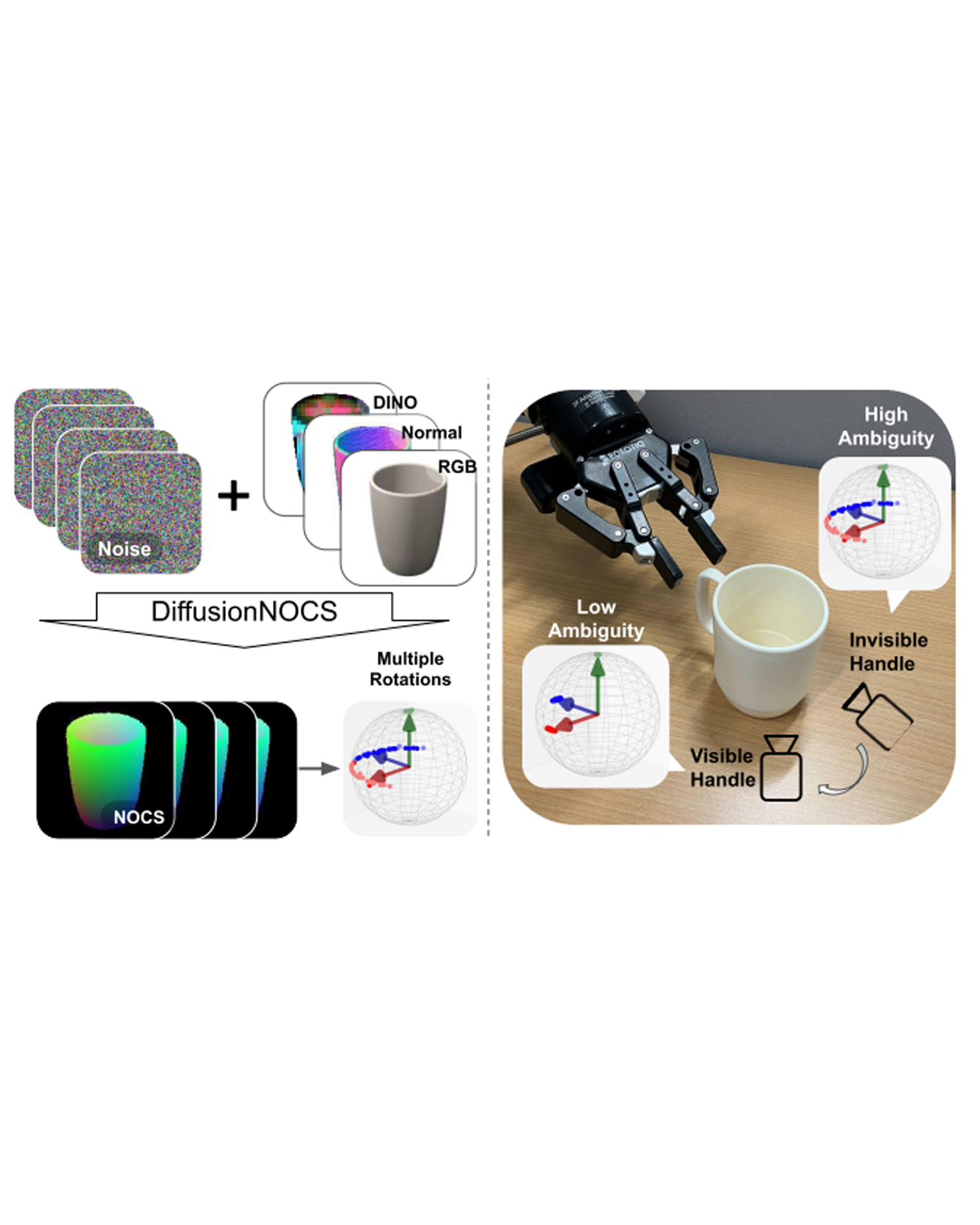
This paper addresses the challenging problem of category-level pose estimation. Current state-of-the-art methods for this task face challenges when dealing with symmetric objects and when attempting to generalize to new environments solely through synthetic data training. In this work, we address these challenges by proposing a probabilistic model that relies on diffusion to estimate dense canonical maps crucial for recovering partial object shapes as well as establishing correspondences essential for pose estimation. Furthermore, we introduce critical components to enhance performance by leveraging the strength of the diffusion models with multi-modal input representations. We demonstrate the effectiveness of our method by testing it on a range of real datasets. Despite being trained solely on our generated synthetic data, our approach achieves state-of-the-art performance and unprecedented generalization qualities, outperforming baselines, even those specifically trained on the target domain. READ MORE
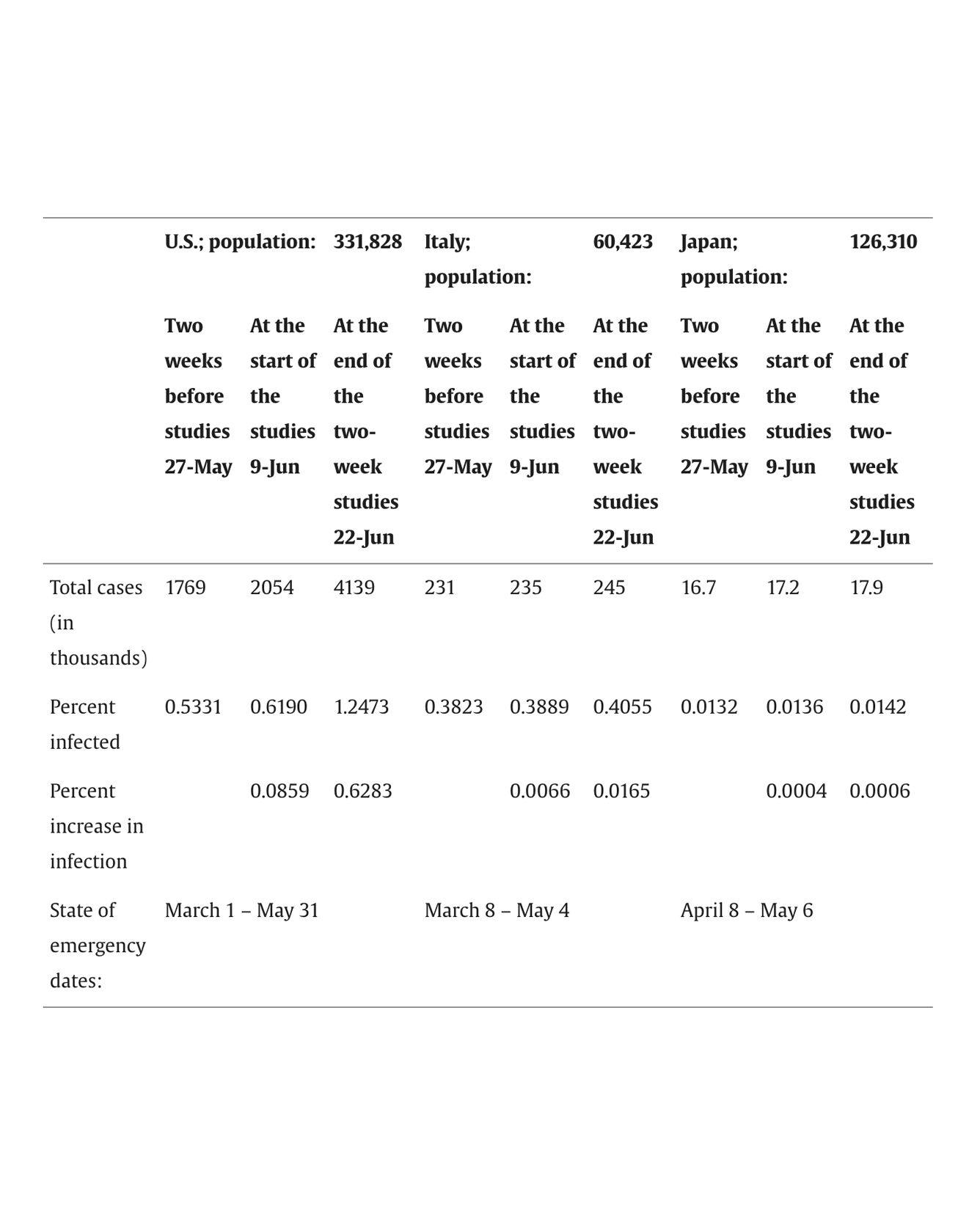
Social group cohesion and social support are critical for positive mental health. People may use technology to maintain existing, or even create new, social groups – particularly when in-person contact is limited. During the global COVID-19 pandemic, countries mandated various stay-at-home orders; for many people worldwide, this was their first experience of extended periods of social isolation. To better understand the relationship of affinity for technology, group cohesion, and mental health depending on change in social isolation, we surveyed people based on country. We studied Italy because of its relatively large increase in social isolation, and we studied Japan because of its relatively small increase in social isolation. We surveyed participants about existing and new social groups in a country that strongly socially isolated (Study 1: Italy, n = 426) and one with few changes from normal (Study 2: Japan, n = 280). We collected data in June 2020, several months after the onset of the COVID-19 pandemic. Affinity for technology related to increased group cohesion and mental health depending on country and on whether groups were new or existing. Dimensions of group cohesion had varied effects on mental health. We synthesize results from this work and a prior study in the United States (U.S., n = 276), which had a very mixed approach to dealing with COVID-19 that differed from approaches in Italy and Japan. Finally, we discuss overall patterns across all three countries. READ MORE
Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website. READ MORE

Object tracking is central to robot perception and scene understanding. Tracking-by-detection has long been a dominant paradigm for object tracking of specific object categories. Recently, large-scale pre-trained models have shown promising advances in detecting and segmenting objects and parts in 2D static images in the wild. This begs the question: can we re-purpose these large-scale pre-trained static image models for open-vocabulary video tracking? In this paper, we re-purpose an open-vocabulary detector, segmenter, and dense optical flow estimator, into a model that tracks and segments objects of any category in 2D videos. Our method predicts object and part tracks with associated language descriptions in monocular videos, rebuilding the pipeline of Tractor with modern large pre-trained models for static image detection and segmentation: we detect open-vocabulary object instances and propagate their boxes from frame to frame using a flow-based motion model, refine the propagated boxes with the box regression module of the visual detector, and prompt an open-world segmenter with the refined box to segment the objects. We decide the termination of an object track based on the objectness score of the propagated boxes, as well as forward-backward optical flow consistency. We re-identify objects across occlusions using deep feature matching. We show that our model achieves strong performance on multiple established video object segmentation and tracking benchmarks, and can produce reasonable tracks in manipulation data. In particular, our model outperforms previous state-of-the-art in UVO and BURST, benchmarks for open-world object tracking and segmentation, despite never being explicitly trained for tracking. We hope that our approach can serve as a simple and extensible framework for future research. READ MORE
Loneliness and social isolation reduce physical and mental wellbeing. Older adults are particularly prone to social isolation due to decreased connection with previous social networks such as at workplaces. Social technology can decrease loneliness and improve wellbeing. The COVID-19 pandemic prompted quarantine and social distancing for many people, creating a context of widespread social isolation. READ MORE
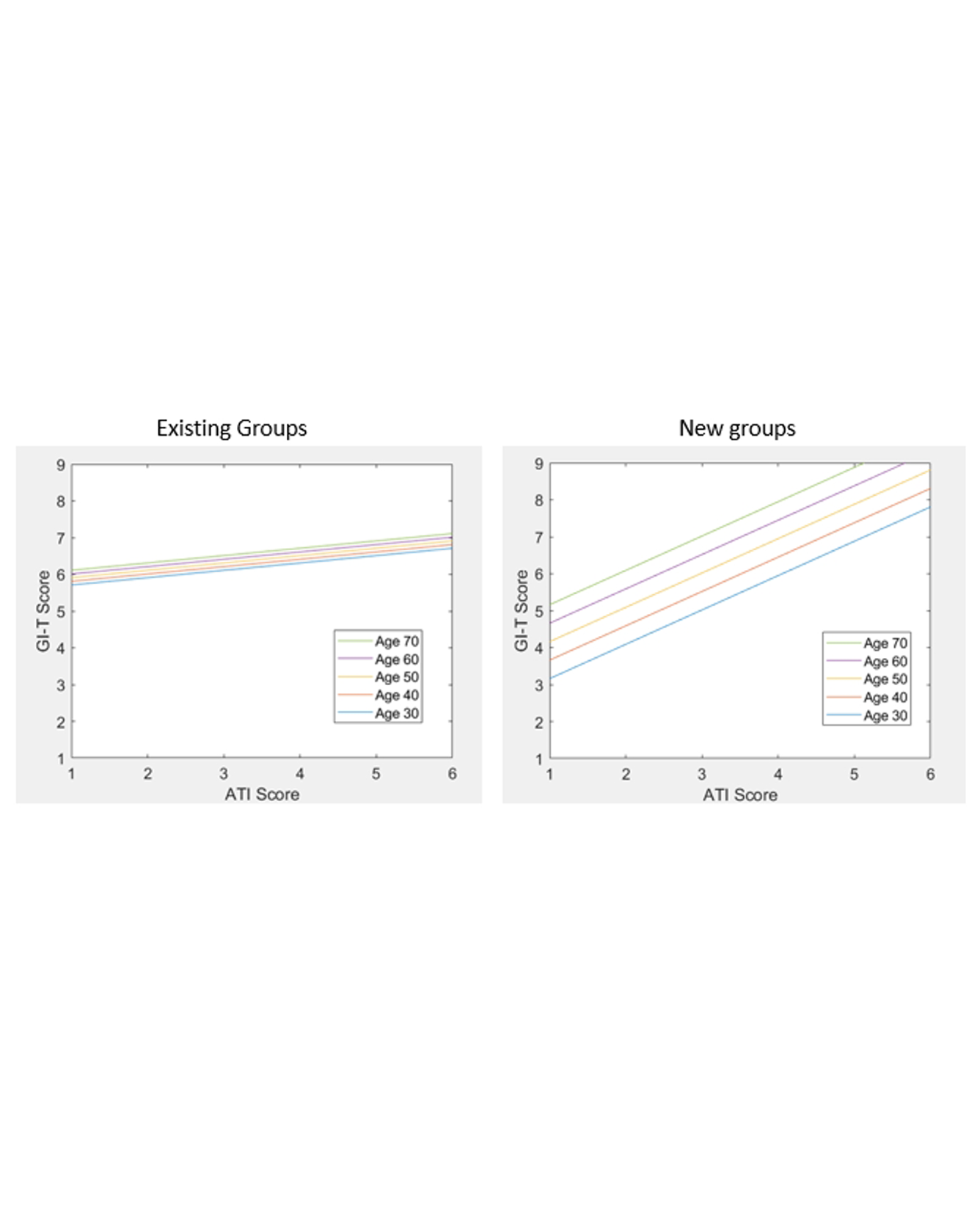
During the 2020 COVID-19 pandemic, governments around the world mandated shutdowns and social distancing, limiting how much people could see other people outside of their household. Because of this, people had negative mental health outcomes, and many people turned to technology to maintain connections and create new ones. In this paper, we examine the relationship between technology, mental health, and group cohesion with existing groups (N = 202) and new groups (N = 74). We surveyed U.S. participants in June 2020, two to three months after the start of mandated social distancing. Results indicated that, as predicted, higher levels of reported group cohesion typically related to better reported mental health; however, the relationship occurred differently for existing groups compared to new groups. Further, higher levels of affinity for technology did not relate to group cohesion for existing groups, but did relate to more perceived cohesion for new groups. Researchers and mental health practitioners can use these results to help people develop a sense of group cohesion with new and existing groups and improve mental health during relative social isolation; technology may be especially beneficial for people to connect with new groups compared to existing groups. READ MORE