
Featured Publications
All Publications
Mobile telepresence robots can help reduce loneliness by facilitating people to visit each other and have more social presence than visiting via video or audio calls. However, using new technology can be challenging for many older adults. In this paper, we examine how older adults use and want to use mobile telepresence robots, how these robots affect their social connection, and how they can be improved for older adults’ use. We placed a mobile telepresence robot in the home of older adult primary participants (N = 7; age 60+) for 7 months and facilitated monthly activities between them and a secondary participant (N = 8; age 18+) of their choice. Participants used the robots as they liked between monthly activities. We collected diary entries and monthly interviews from primary participants and a final interview from secondary participants. Results indicate that older adults found many creative uses for the robots, including conversations, board games, and hide ‘n’ seek. Several participants felt more socially connected with others and a few had improved their comfort with technology because of their use of the robot. They also suggested design recommendations and updates for the robots related to size, mobility, and more, which can help practitioners improve robots for older adults’ use. READ MORE

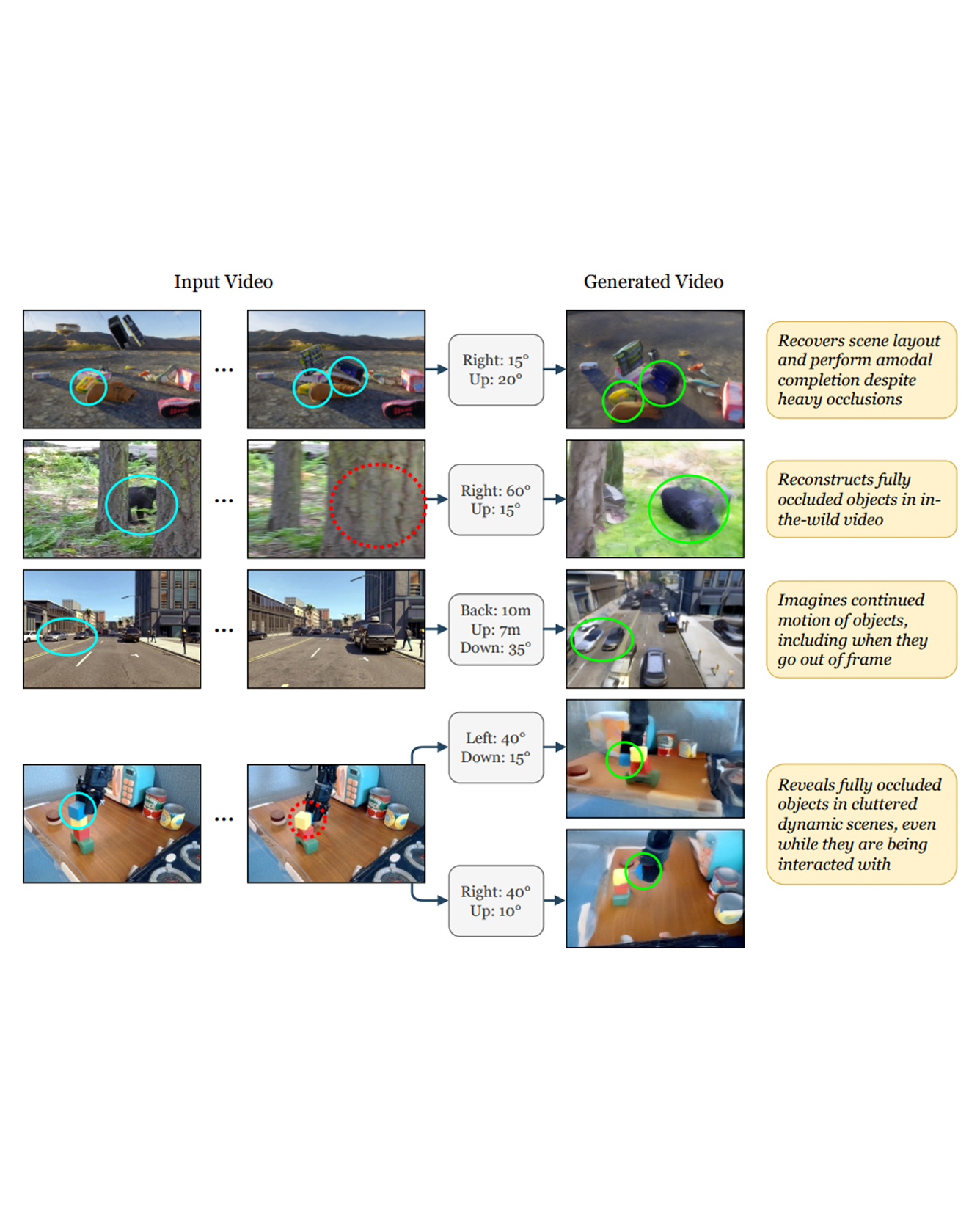
Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose GCD, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality. READ MORE
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models that are pretrained on largescale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate a video showing an execution of the task conditioned on images of a novel scene, and use this synthesized video to directly control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches. READ MORE

Social technology can improve the quality of social lives of older adults (OAs) and mitigate negative mental and physical health outcomes. When people engage with technology, they can do so to stimulate social interaction (stimulation hypothesis) or disengage from their real world (disengagement hypothesis), according to Nowland et al.‘s model of the relationship between social Internet use and loneliness. External events, such as large periods of social isolation like during the COVID-19 pandemic, can also affect whether people use technology in line with the stimulation or disengagement hypothesis. We examined how the COVID-19 pandemic affected the social challenges OAs faced and their expectations for robot technology to solve their challenges. We conducted two participatory design (PD) workshops with OAs during and after the COVID-19 pandemic. During the pandemic, OAs’ primary concern was distanced communication with family members, with a prevalent desire to assist them through technology. They also wanted to share experiences socially, as such OA’s attitude toward technology could be explained mostly by the stimulation hypothesis. However, after COVID-19 the pandemic, their focus shifted towards their own wellbeing. Social isolation and loneliness were already significant issues for OAs, and these were exacerbated by the COVID-19 pandemic. Therefore, such OAs’ attitudes toward technology after the pandemic could be explained mostly by the disengagement hypothesis. This clearly reflect the OA’s current situation that they have been getting further digitally excluded due to rapid technological development during the pandemic. Both during and after the pandemic, OAs found it important to have technologies that were easy to use, which would reduce their digital exclusion. After the pandemic, we found this especially in relation to newly developed technologies meant to help people keep at a distance. To effectively integrate these technologies and avoid excluding large parts of the population, society must address the social challenges faced by OAs. READ MORE

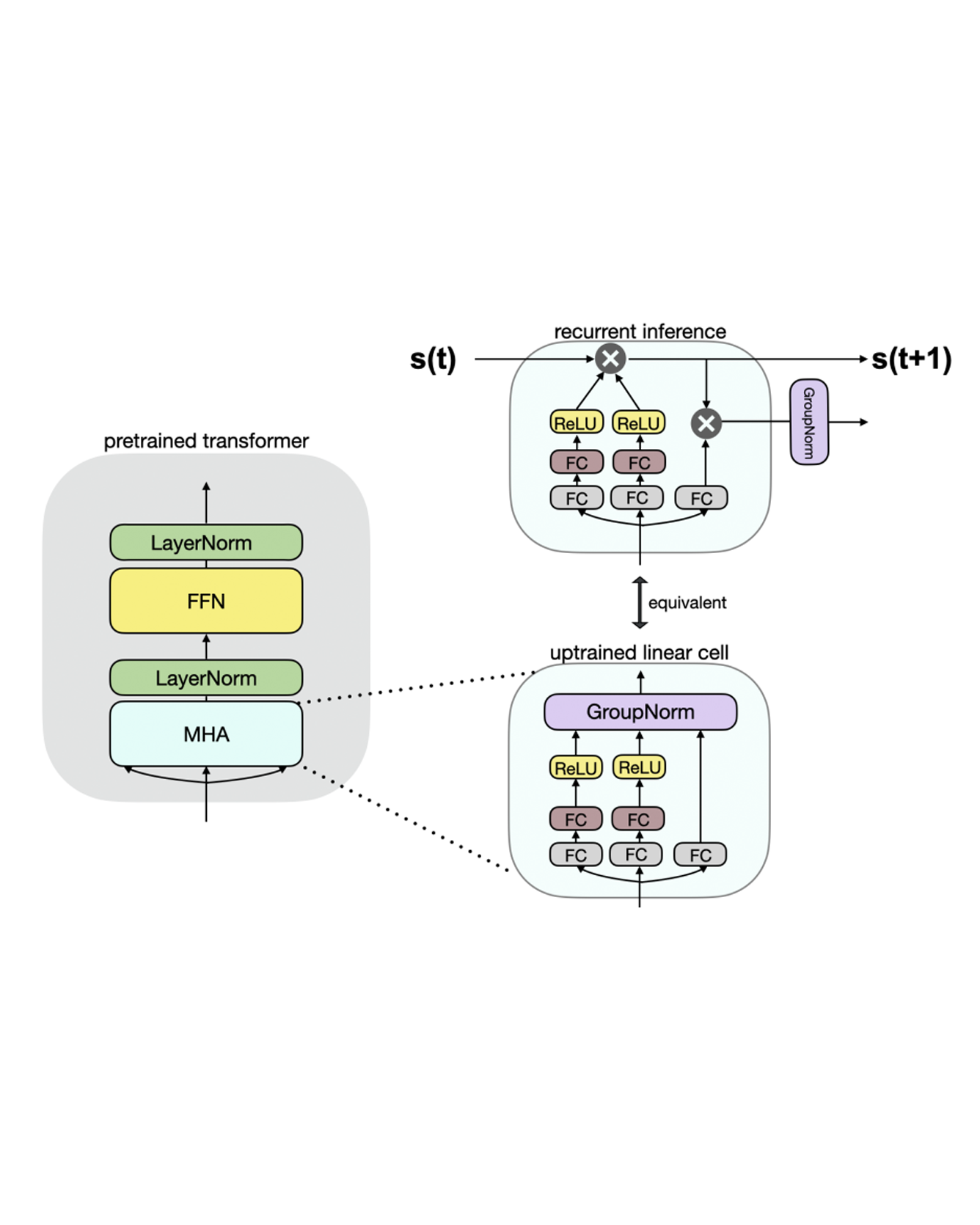
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm. READ MORE
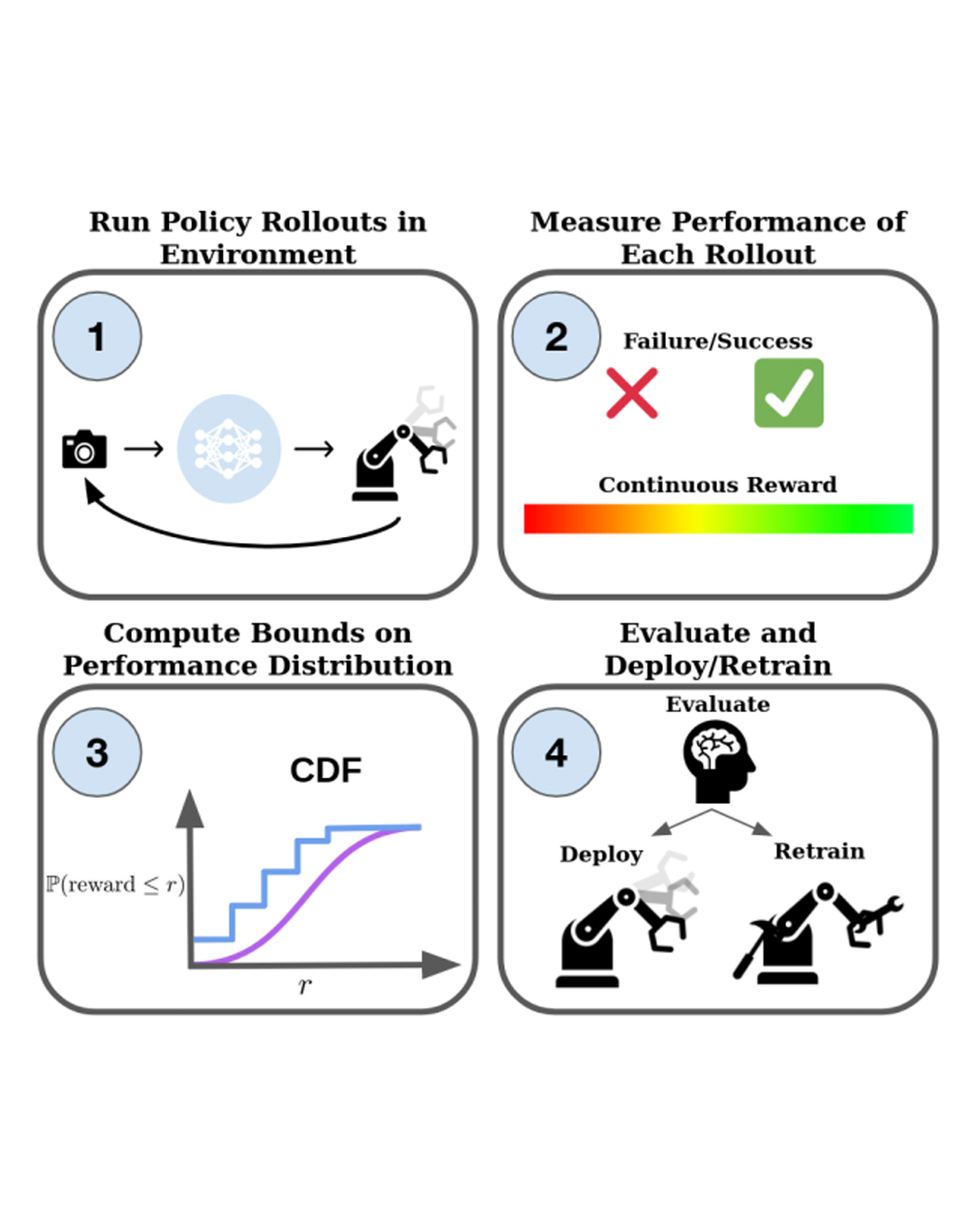
With the rise of stochastic generative models in robot policy learning, end-to-end visuomotor policies are increasingly successful at solving complex tasks by learning from human demonstrations. Nevertheless, since real-world evaluation costs afford users only a small number of policy rollouts, it remains a challenge to accurately gauge the performance of such policies. This is exacerbated by distribution shifts causing unpredictable changes in performance during deployment. To rigorously evaluate behavior cloning policies, we present a framework that provides a tight lower-bound on robot performance in an arbitrary environment, using a minimal number of experimental policy rollouts. Notably, by applying the standard stochastic ordering to robot performance distributions, we provide a worst-case bound on the entire distribution of performance (via bounds on the cumulative distribution function) for a given task. We build upon established statistical results to ensure that the bounds hold with a user-specified confidence level and tightness, and are constructed from as few policy rollouts as possible. In experiments we evaluate policies for visuomotor manipulation in both simulation and hardware. Specifically, we (i) empirically validate the guarantees of the bounds in simulated manipulation settings, (ii) find the degree to which a learned policy deployed on hardware generalizes to new real-world environments, and (iii) rigorously compare two policies tested in out-of-distribution settings. Our experimental data, code, and implementation of confidence bounds are open-source. READ MORE
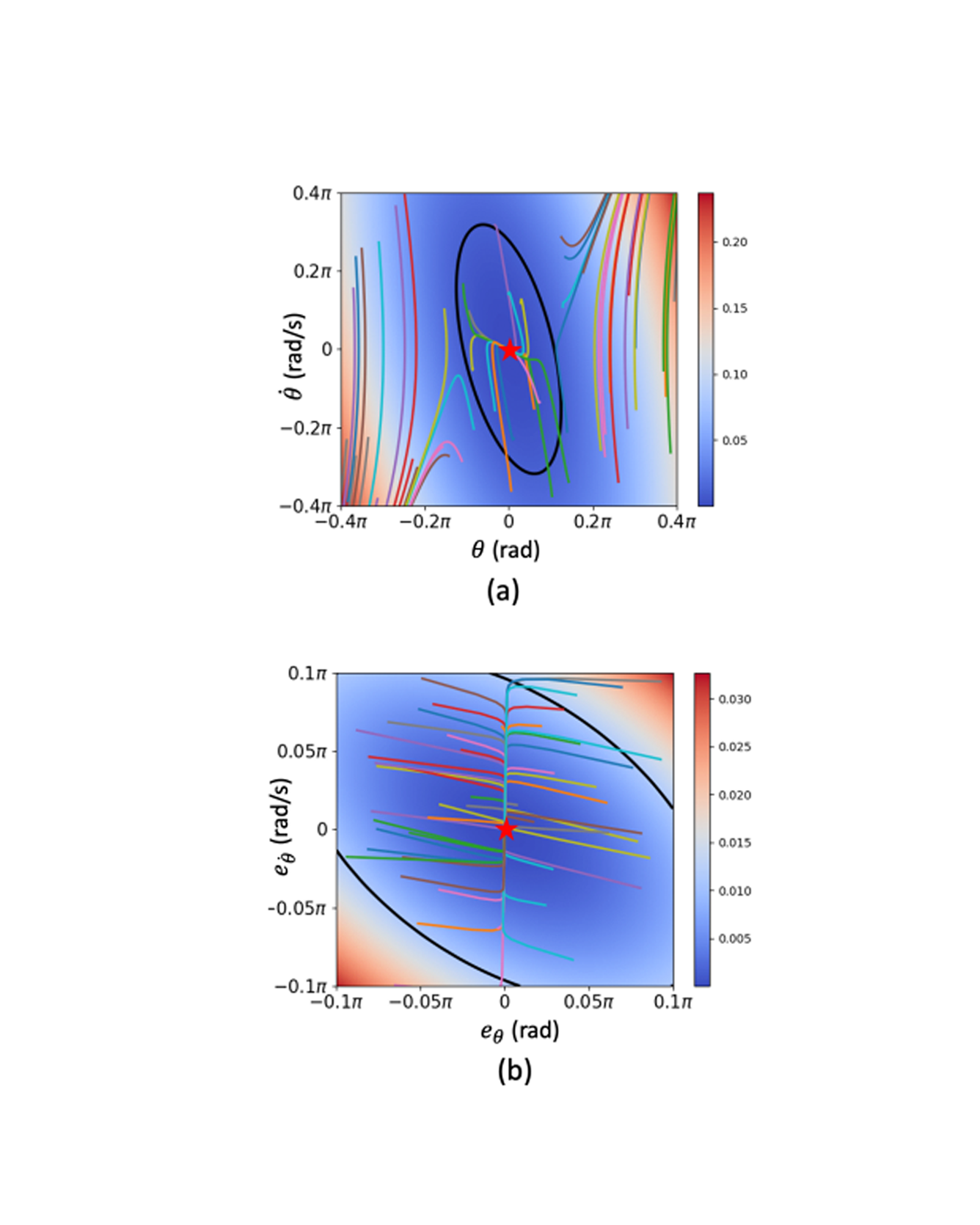
Learning-based neural-network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers for sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. READ MORE
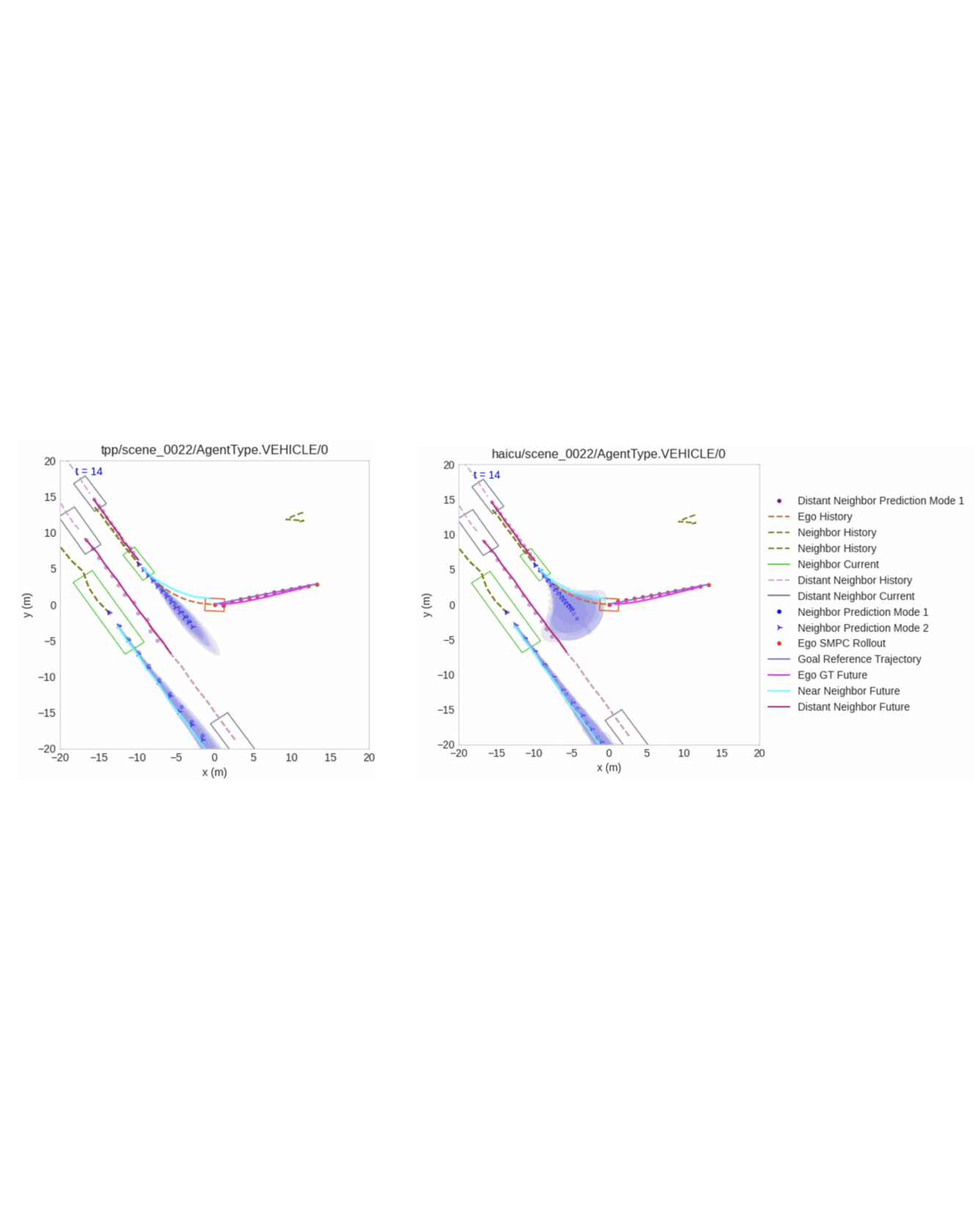
Autonomous vehicles (AVs) are increasingly being deployed in urban environments. However, most AVs operate without accounting for uncertainty inherent to perceiving the world. To remedy this disregard, uncertainty-aware planners have recently been developed that account for upstream perception and prediction uncertainty, generating more efficient motion plans without sacrificing safety. However, such planners may be sensitive to prediction uncertainty miscalibration, the magnitude of which has not yet been characterized. Towards this end, we perform a detailed analysis of the impact that perceptual uncertainty propagation and uncertainty calibration has on perception-based motion planning. We do so with a comparison between two novel prediction-planning architectures with varying levels of uncertainty incorporation on a largescale, real-world autonomous driving dataset. We find that, despite one model producing quantifiably better predictions, both methods produce similar motion plans with only minor differences. READ MORE
If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging—it requires the ability to both parse the 3D structure of the scene and correctly ground freeform language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Code will be available at https://ripl.github.io/Transcrib3D. READ MORE

This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we show that VTCD can be used for fine-grained action recognition and video object segmentation. READ MORE
