Featured Publications
All Publications
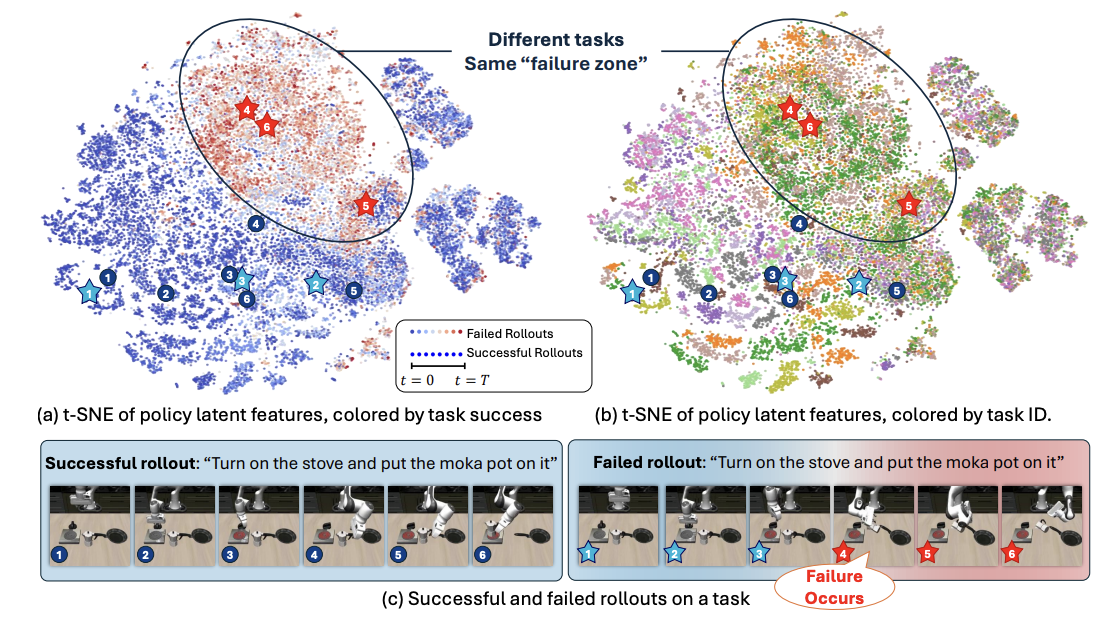
While vision-language-action models (VLAs) have shown promising robotic behaviors across a diverse set of manipulation tasks, they achieve limited success rates when deployed on novel tasks out of the box. To allow these policies to safely interact with their environments, we need a failure detector that gives a timely alert such that the robot can stop, backtrack, or ask for help. However, existing failure detectors are trained and tested only on one or a few specific tasks, while generalist VLAs require the detector to generalize and detect failures also in unseen tasks and novel environments. In this paper, we introduce the multitask failure detection problem and propose SAFE, a failure detector for generalist robot policies such as VLAs. We analyze the VLA feature space and find that VLAs have sufficient highlevel knowledge about task success and failure, which is generic across different tasks. Based on this insight, we design SAFE to learn from VLA internal features and predict a single scalar indicating the likelihood of task failure. SAFE is trained on both successful and failed rollouts, and is evaluated on unseen tasks. SAFE is compatible with different policy architectures. We test it on OpenVLA, π0, and π0-FAST in both simulated and real-world environments extensively. We compare SAFE with diverse baselines and show that SAFE achieves state-of-the-art failure detection performance and a favorable trade-off between accuracy and detection time using conformal prediction. More qualitative results and code can be found at the project webpage: https://vla-safe.github.io/.
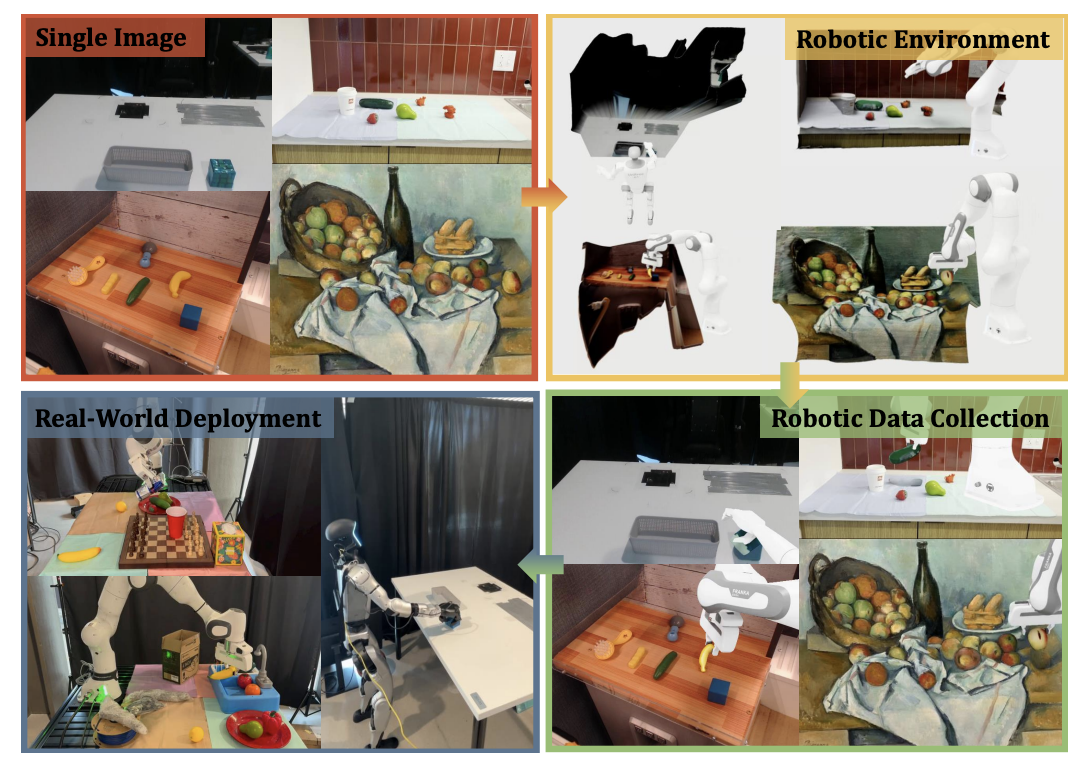
We introduce RoLA, a framework that transforms any in-the-wild image into an interactive, physics-enabled robotic environment. Unlike previous methods, RoLA operates directly on a single image without requiring additional hardware or digital assets. Our framework democratizes robotic data generation by producing massive visuomotor robotic demonstrations within minutes from a wide range of image sources, including camera captures, robotic datasets, and Internet images. At its core, our approach combines a novel method for single-view physical scene recovery with an efficient visual blending strategy for photorealistic data collection. We demonstrate RoLA's versatility across applications like scalable robotic data generation and augmentation, robot learning from Internet images, and single-image real-to-sim-to-real systems for manipulators and humanoids. Video results are available at this https URL.
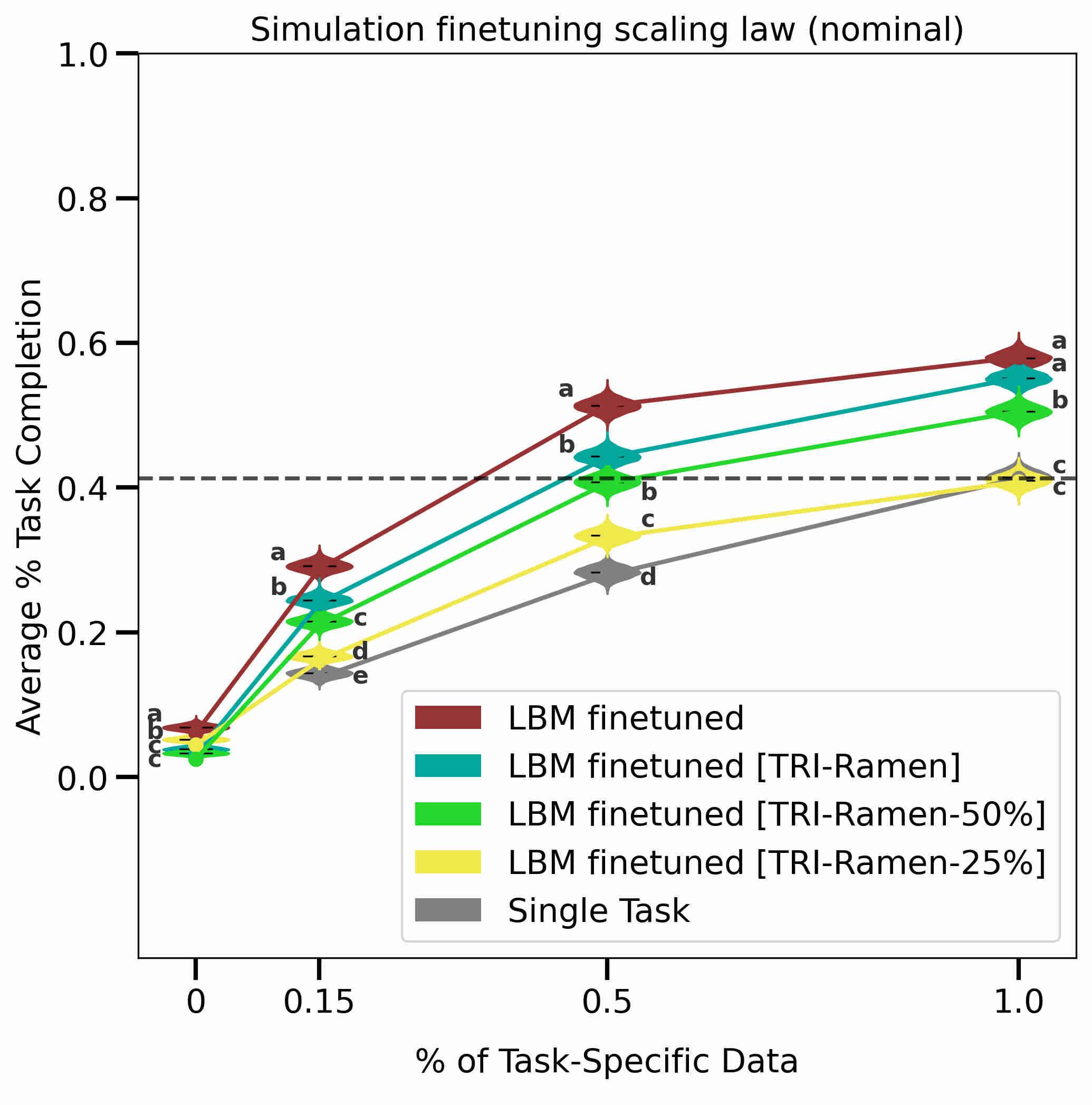
Robot manipulation has seen tremendous progress in recent years, with imitation learning policies enabling successful performance of dexterous and hard-to-model tasks. Concurrently, scaling data and model size has led to the development of capable language and vision foundation models, motivating large-scale efforts to create general-purpose robot foundation models. While these models have garnered significant enthusiasm and investment, meaningful evaluation of real-world performance remains a challenge, limiting both the pace of development and inhibiting a nuanced understanding of current capabilities. In this paper, we rigorously evaluate multitask robot manipulation policies, referred to as Large Behavior Models (LBMs), by extending the Diffusion Policy paradigm across a corpus of simulated and real-world robot data. We propose and validate an evaluation pipeline to rigorously analyze the capabilities of these models with statistical confidence. We compare against single-task baselines through blind, randomized trials in a controlled setting, using both simulation and real-world experiments. We find that multi-task pretraining makes the policies more successful and robust, and enables teaching complex new tasks more quickly, using a fraction of the data when compared to single-task baselines. Moreover, performance predictably increases as pretraining scale and diversity grows.
Abstract: In this work, we leverage GPUs to construct probabilistically collision-free convex sets in robot configuration space on the fly. This extends the use of modern motion planning algorithms that leverage such representations to changing environments. These planners rapidly and reliably optimize high-quality trajectories, without the burden of challenging nonconvex collision-avoidance constraints. We present an algorithm that inflates collision-free piecewise linear paths into sequences of convex sets (SCS) that are probabilistically collision-free using massive parallelism. We then integrate this algorithm into a motion planning pipeline, which leverages dynamic roadmaps to rapidly find one or multiple collision-free paths, and inflates them. We then optimize the trajectory through the probabilistically collision-free sets, simultaneously using the candidate trajectory to detect and remove collisions from the sets. We demonstrate the efficacy of our approach on a simulation benchmark and a KUKA iiwa 7 robot manipulator with perception in the loop. On our benchmark, our approach runs 17.1 times faster and yields a 27.9% increase in reliability over the nonlinear trajectory optimization baseline, while still producing high-quality motion plans. Website: https://sites.google.com/view/GPUPolytopes

Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. We propose a novel approach for policy mobilization that bridges navigation and manipulation by optimizing the robot's base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. To understand policy mobilization in more depth, we also introduce the Mobi-π framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, and (3) visualization tools for analysis. In both our developed simulation task suite and the real world, we show that our approach outperforms baselines, demonstrating its effectiveness for policy mobilization.

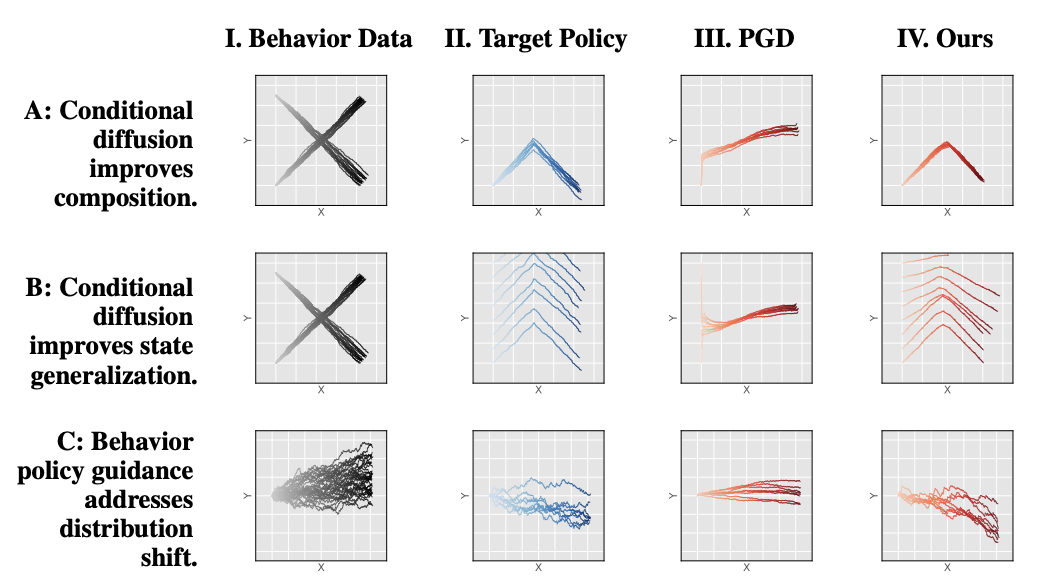
Off-policy evaluation (OPE) estimates the performance of a target policy using offline data collected from a behavior policy, and is crucial in domains such as robotics or healthcare where direct interaction with the environment is costly or unsafe. Existing OPE methods are ineffective for high-dimensional, long-horizon problems, due to exponential blow-ups in variance from importance weighting or compounding errors from learned dynamics models. To address these challenges, we propose STITCH-OPE, a model-based generative framework that leverages denoising diffusion for long-horizon OPE in high-dimensional state and action spaces. Starting with a diffusion model pre-trained on the behavior data, STITCH-OPE generates synthetic trajectories from the target policy by guiding the denoising process using the score function of the target policy. STITCH-OPE proposes two technical innovations that make it advantageous for OPE: (1) prevents over-regularization by subtracting the score of the behavior policy during guidance, and (2) generates long-horizon trajectories by stitching partial trajectories together end-to-end. We provide a theoretical guarantee that under mild assumptions, these modifications result in an exponential reduction in variance versus long-horizon trajectory diffusion. Experiments on the D4RL and OpenAI Gym benchmarks show substantial improvement in mean squared error, correlation, and regret metrics compared to state-of-the-art OPE methods.
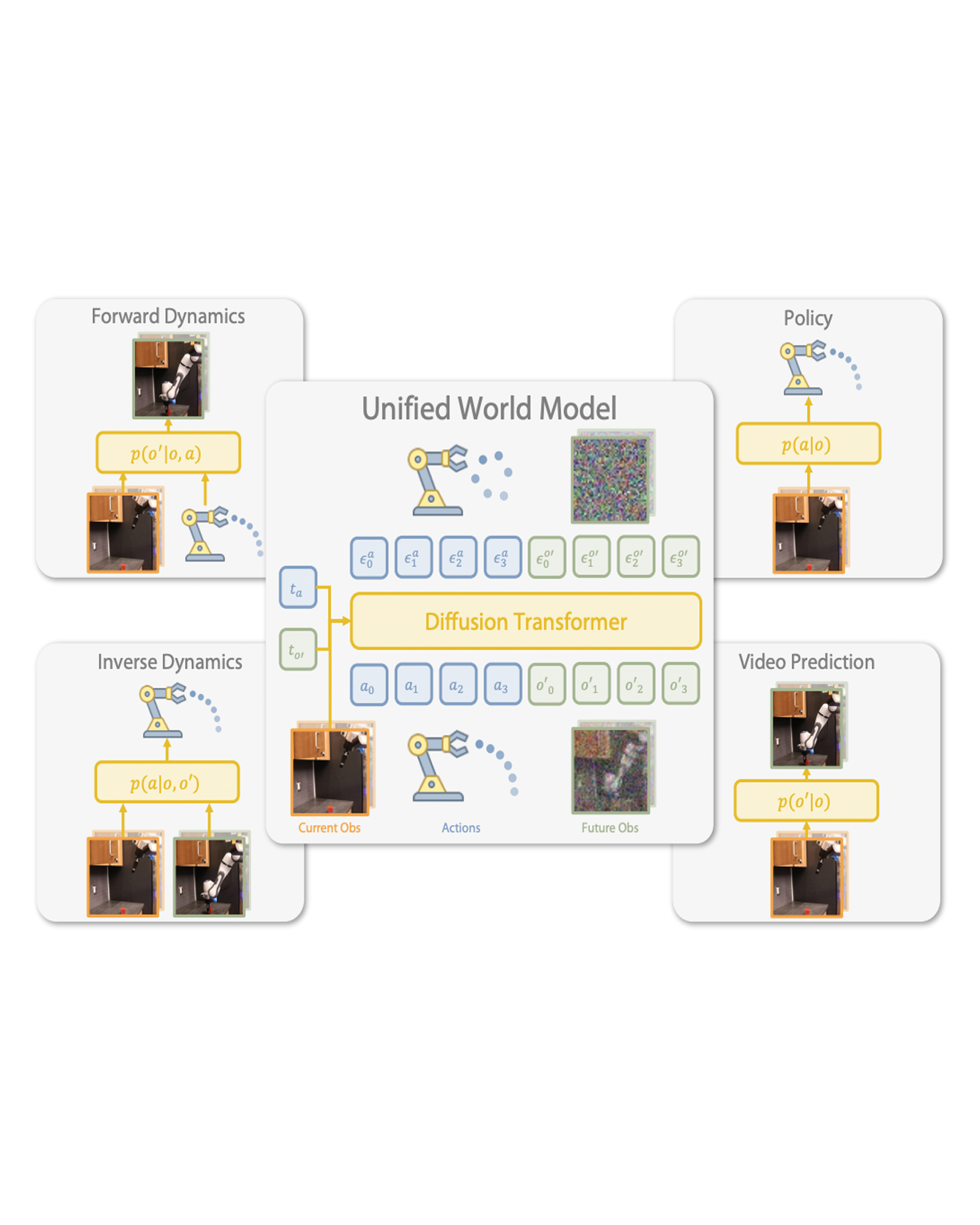
Imitation learning has emerged as a promising approach towards building generalist robots. However, scaling imitation learning for large robot foundation models remains challenging due to its reliance on high-quality expert demonstrations. Meanwhile, large amounts of video data depicting a wide range of environments and diverse behaviors are readily available. This data provides a rich source of information about real-world dynamics and agent-environment interactions. Leveraging this data directly for imitation learning, however, has proven difficult due to the lack of action annotation. In this work, we present Unified World Models (UWM), a framework that allows for leveraging both video and action data for policy learning. Specifically, a UWM integrates an action diffusion process and a video diffusion process within a unified transformer architecture, where independent diffusion timesteps govern each modality. By controlling each diffusion timestep, UWM can flexibly represent a policy, a forward dynamics, an inverse dynamics, and a video generator. Through simulated and real-world experiments, we show that: (1) UWM enables effective pretraining on large-scale multitask robot datasets with both dynamics and action predictions, resulting in more generalizable and robust policies than imitation learning, (2) UWM naturally facilitates learning from action-free video data through independent control of modality-specific diffusion timesteps, further improving the performance of finetuned policies. Our results suggest that UWM offers a promising step toward harnessing large, heterogeneous datasets for scalable robot learning, and provides a simple unification between the often disparate paradigms of imitation learning and world modeling. Videos and code are available at this https URL.
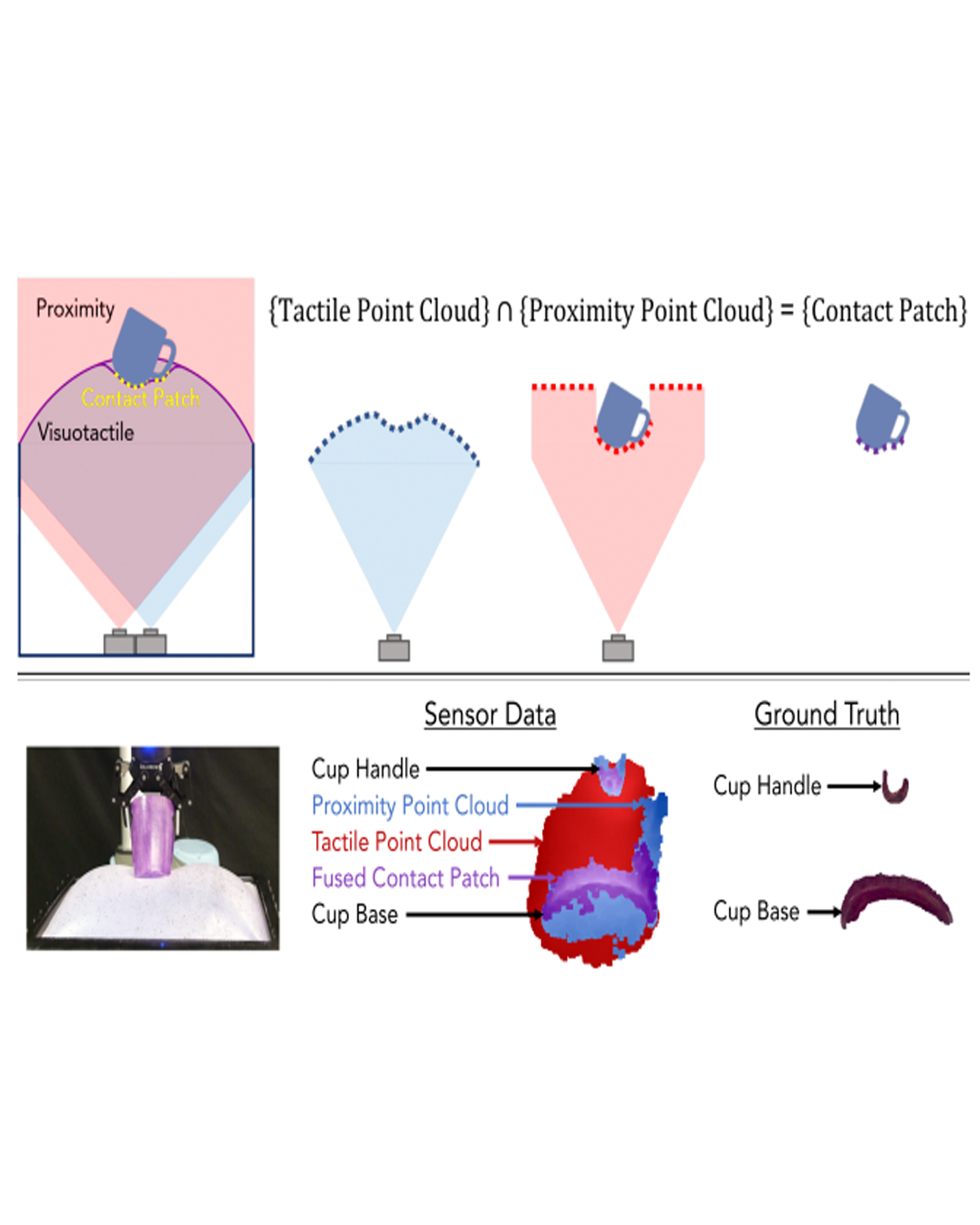
Visuotactile sensors are a popular tactile sensing strategy due to high-fidelity estimates of local object geometry. However, existing algorithms for processing raw sensor inputs to useful intermediate signals such as contact patches struggle in high-deformation regimes. This is due to physical constraints imposed by sensor hardware and small-deformation assumptions used by mechanics-based models. In this work, we propose a fusion algorithm for proximity and visuotactile point clouds for contact patch segmentation, entirely independent from membrane mechanics. This algorithm exploits the synchronous, high spatial resolution proximity and visuotactile modalities enabled by an extremely deformable, selectively transmissive soft membrane, which uses visible light for visuotactile sensing and infrared light for proximity depth. We evaluate our contact patch algorithm in low (10%), medium (60%), and high (100%+) strain states. We compare our method against three baselines: proximity-only, tactile-only, and a first principles mechanics model. Our approach outperforms all baselines with an average RMSE under 2.8 mm of the contact patch geometry across all strain ranges. We demonstrate our contact patch algorithm in four applications: varied stiffness membranes, torque and shear-induced wrinkling, closed loop control, and pose estimation.
Achieving robust dexterous manipulation in unstructured domestic environments remains a significant challenge in robotics. Even with state-of-the-art robot learning methods, haptic-oblivious control strategies (i.e. those relying only on external vision and/or proprioception) often fall short due to occlusions, visual complexities, and the need for precise contact interaction control. To address these limitations, we introduce PolyTouch, a novel robot finger that integrates camera-based tactile sensing, acoustic sensing, and peripheral visual sensing into a single design that is compact and durable. PolyTouch provides high-resolution tactile feedback across multiple temporal scales, which is essential for efficiently learning complex manipulation tasks. Experiments demonstrate an at least 20-fold increase in lifespan over commercial tactile sensors, with a design that is both easy to manufacture and scalable. We then use this multi-modal tactile feedback along with visuo-proprioceptive observations to synthesize a tactile-diffusion policy from human demonstrations; the resulting contact-aware control policy significantly outperforms haptic-oblivious policies in multiple contact-aware manipulation policies. This paper highlights how effectively integrating multi-modal contact sensing can hasten the development of effective contact-aware manipulation policies, paving the way for more reliable and versatile domestic robots. More information can be found at this https URL.

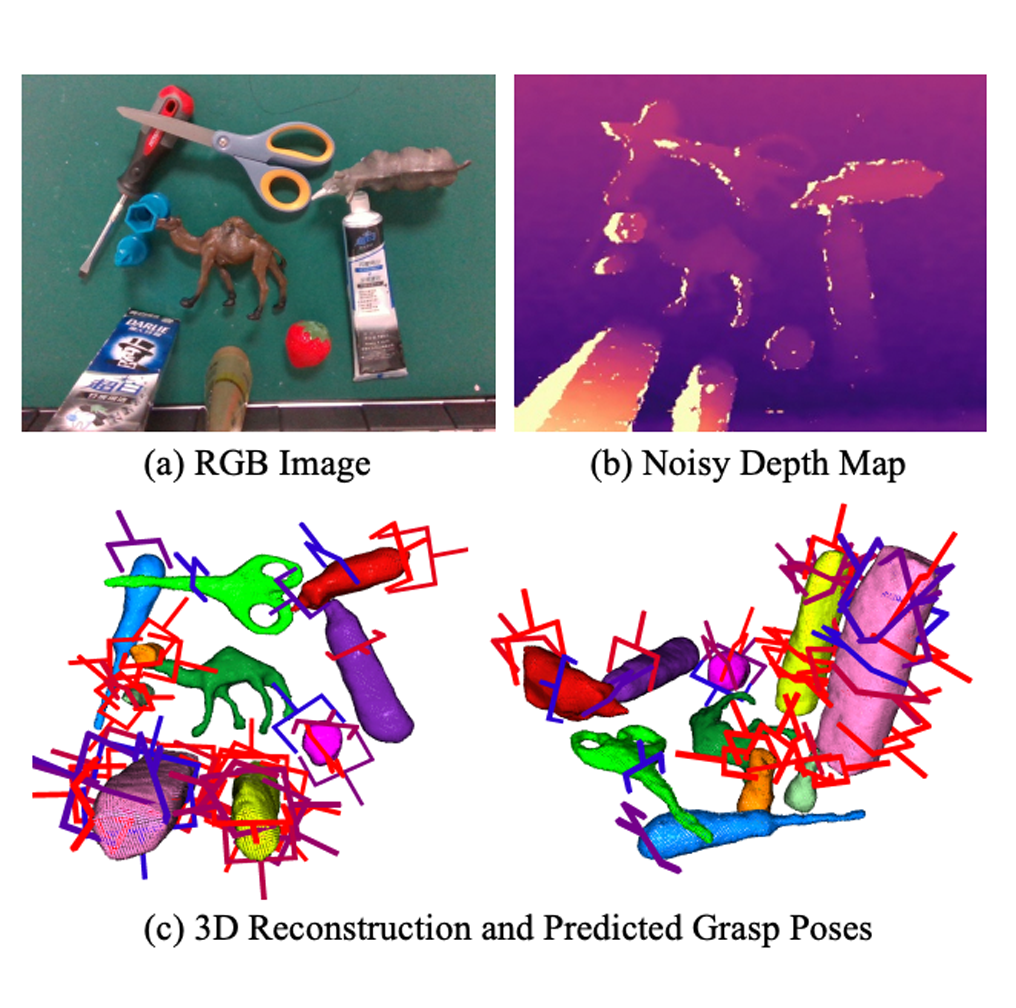
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data. READ MORE