
Featured Publications
All Publications
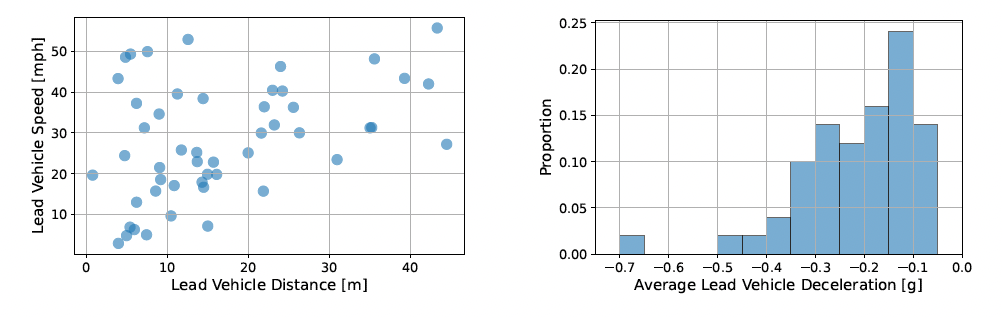
Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. We propose a novel approach for policy mobilization that bridges navigation and manipulation by optimizing the robot's base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. To understand policy mobilization in more depth, we also introduce the Mobi-π framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, and (3) visualization tools for analysis. In both our developed simulation task suite and the real world, we show that our approach outperforms baselines, demonstrating its effectiveness for policy mobilization.

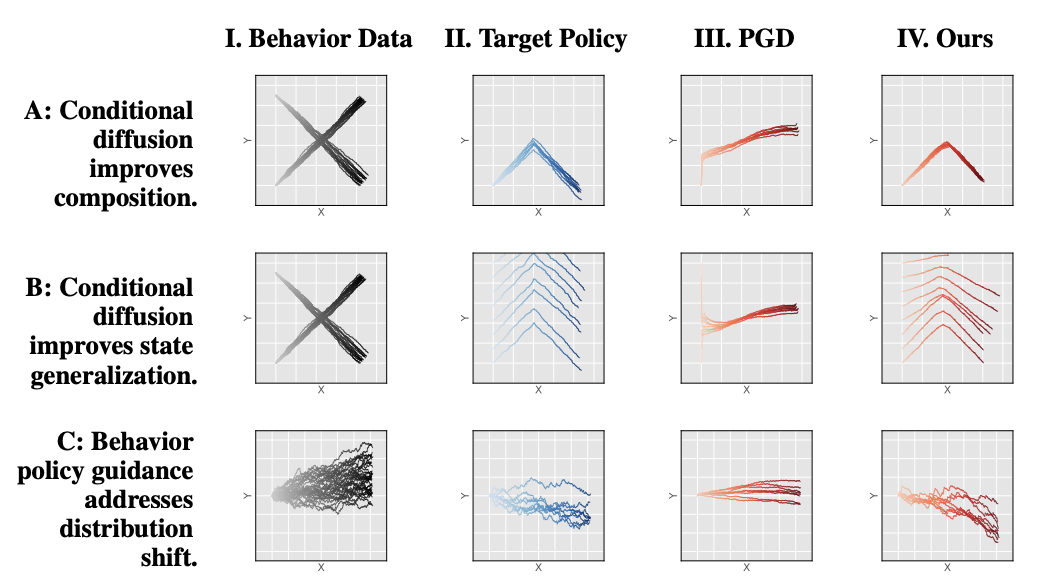
Off-policy evaluation (OPE) estimates the performance of a target policy using offline data collected from a behavior policy, and is crucial in domains such as robotics or healthcare where direct interaction with the environment is costly or unsafe. Existing OPE methods are ineffective for high-dimensional, long-horizon problems, due to exponential blow-ups in variance from importance weighting or compounding errors from learned dynamics models. To address these challenges, we propose STITCH-OPE, a model-based generative framework that leverages denoising diffusion for long-horizon OPE in high-dimensional state and action spaces. Starting with a diffusion model pre-trained on the behavior data, STITCH-OPE generates synthetic trajectories from the target policy by guiding the denoising process using the score function of the target policy. STITCH-OPE proposes two technical innovations that make it advantageous for OPE: (1) prevents over-regularization by subtracting the score of the behavior policy during guidance, and (2) generates long-horizon trajectories by stitching partial trajectories together end-to-end. We provide a theoretical guarantee that under mild assumptions, these modifications result in an exponential reduction in variance versus long-horizon trajectory diffusion. Experiments on the D4RL and OpenAI Gym benchmarks show substantial improvement in mean squared error, correlation, and regret metrics compared to state-of-the-art OPE methods.
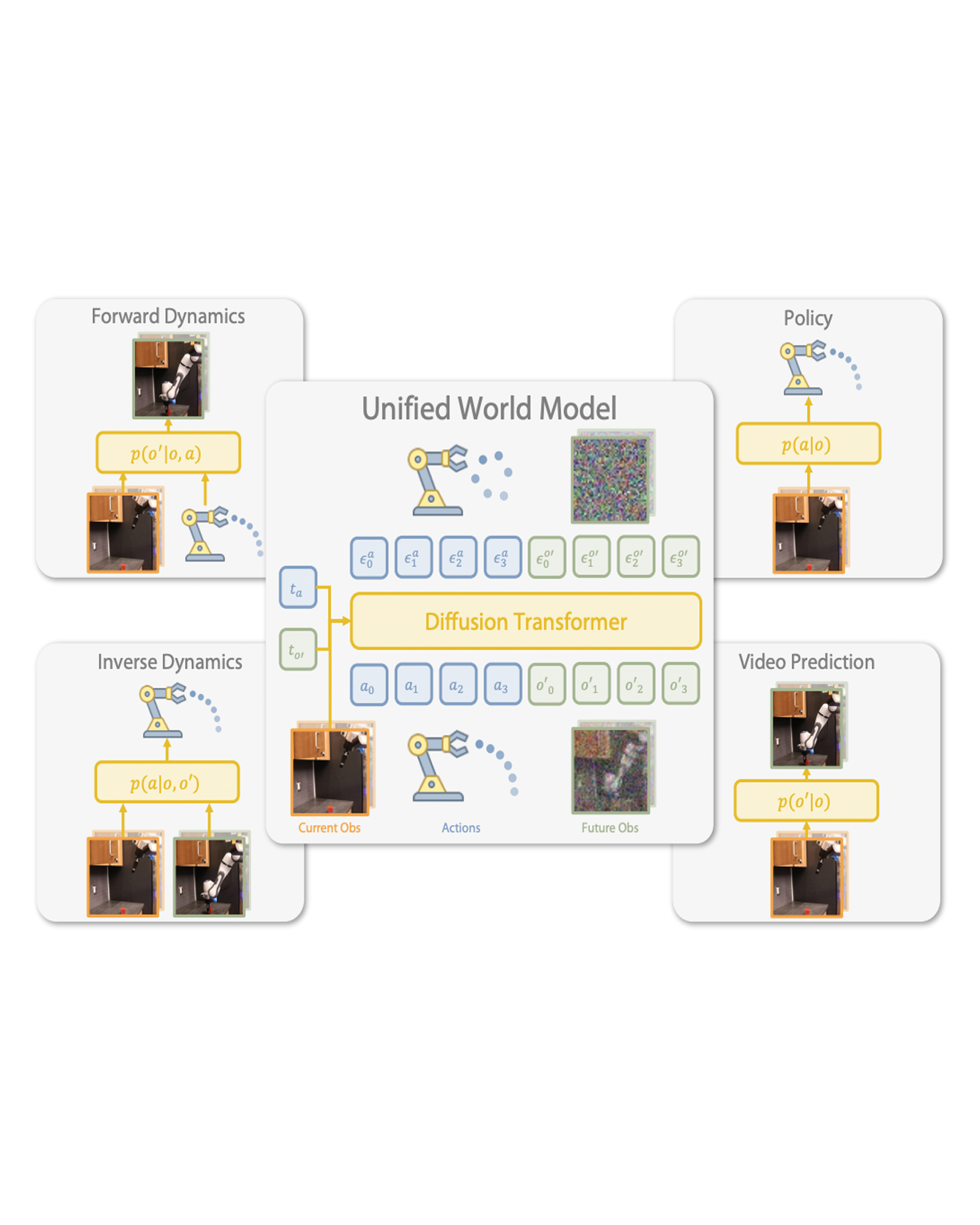
Imitation learning has emerged as a promising approach towards building generalist robots. However, scaling imitation learning for large robot foundation models remains challenging due to its reliance on high-quality expert demonstrations. Meanwhile, large amounts of video data depicting a wide range of environments and diverse behaviors are readily available. This data provides a rich source of information about real-world dynamics and agent-environment interactions. Leveraging this data directly for imitation learning, however, has proven difficult due to the lack of action annotation. In this work, we present Unified World Models (UWM), a framework that allows for leveraging both video and action data for policy learning. Specifically, a UWM integrates an action diffusion process and a video diffusion process within a unified transformer architecture, where independent diffusion timesteps govern each modality. By controlling each diffusion timestep, UWM can flexibly represent a policy, a forward dynamics, an inverse dynamics, and a video generator. Through simulated and real-world experiments, we show that: (1) UWM enables effective pretraining on large-scale multitask robot datasets with both dynamics and action predictions, resulting in more generalizable and robust policies than imitation learning, (2) UWM naturally facilitates learning from action-free video data through independent control of modality-specific diffusion timesteps, further improving the performance of finetuned policies. Our results suggest that UWM offers a promising step toward harnessing large, heterogeneous datasets for scalable robot learning, and provides a simple unification between the often disparate paradigms of imitation learning and world modeling. Videos and code are available at this https URL.
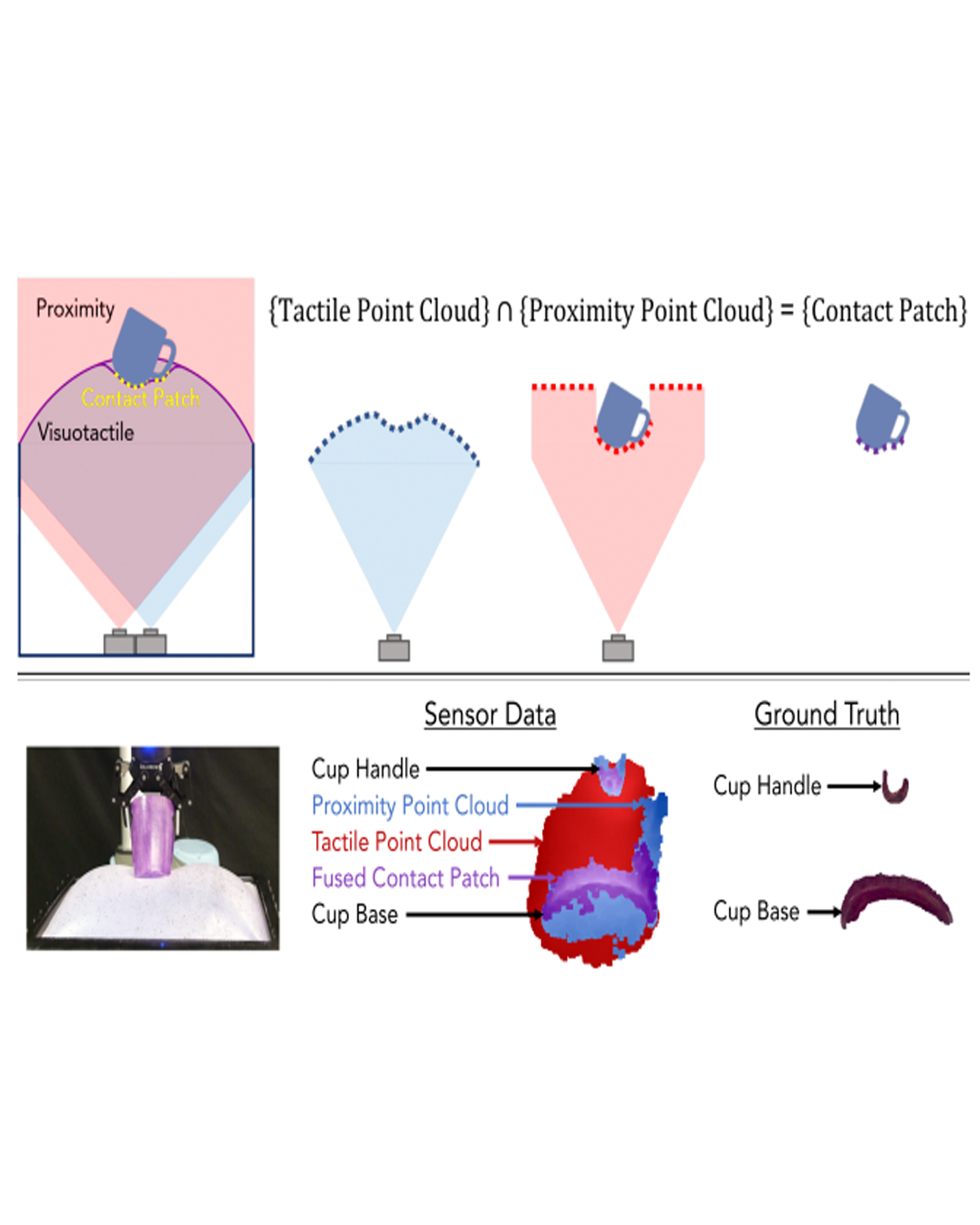
Visuotactile sensors are a popular tactile sensing strategy due to high-fidelity estimates of local object geometry. However, existing algorithms for processing raw sensor inputs to useful intermediate signals such as contact patches struggle in high-deformation regimes. This is due to physical constraints imposed by sensor hardware and small-deformation assumptions used by mechanics-based models. In this work, we propose a fusion algorithm for proximity and visuotactile point clouds for contact patch segmentation, entirely independent from membrane mechanics. This algorithm exploits the synchronous, high spatial resolution proximity and visuotactile modalities enabled by an extremely deformable, selectively transmissive soft membrane, which uses visible light for visuotactile sensing and infrared light for proximity depth. We evaluate our contact patch algorithm in low (10%), medium (60%), and high (100%+) strain states. We compare our method against three baselines: proximity-only, tactile-only, and a first principles mechanics model. Our approach outperforms all baselines with an average RMSE under 2.8 mm of the contact patch geometry across all strain ranges. We demonstrate our contact patch algorithm in four applications: varied stiffness membranes, torque and shear-induced wrinkling, closed loop control, and pose estimation.
Achieving robust dexterous manipulation in unstructured domestic environments remains a significant challenge in robotics. Even with state-of-the-art robot learning methods, haptic-oblivious control strategies (i.e. those relying only on external vision and/or proprioception) often fall short due to occlusions, visual complexities, and the need for precise contact interaction control. To address these limitations, we introduce PolyTouch, a novel robot finger that integrates camera-based tactile sensing, acoustic sensing, and peripheral visual sensing into a single design that is compact and durable. PolyTouch provides high-resolution tactile feedback across multiple temporal scales, which is essential for efficiently learning complex manipulation tasks. Experiments demonstrate an at least 20-fold increase in lifespan over commercial tactile sensors, with a design that is both easy to manufacture and scalable. We then use this multi-modal tactile feedback along with visuo-proprioceptive observations to synthesize a tactile-diffusion policy from human demonstrations; the resulting contact-aware control policy significantly outperforms haptic-oblivious policies in multiple contact-aware manipulation policies. This paper highlights how effectively integrating multi-modal contact sensing can hasten the development of effective contact-aware manipulation policies, paving the way for more reliable and versatile domestic robots. More information can be found at this https URL.

Diffusion models have made substantial progress in facilitating image generation and editing. As the technology matures, we see its potential in the context of driving simulations to enhance the simulated experience. In this paper, we explore this potential through the introduction of a novel system designed to boost visual fidelity. Our system, DRIVE (Diffusion-based Realism Improvement for Virtual Environments), leverages a diffusion model pipeline to give a simulated environment a photorealistic view, with the flexibility to be adapted for other applications. We conducted a preliminary user study to assess the system’s effectiveness in rendering realistic visuals and supporting participants in performing driving tasks. Our work lays the groundwork for future research on the integration of diffusion models in driving simulations, and provides practical guidelines and best practices for their application in this context.

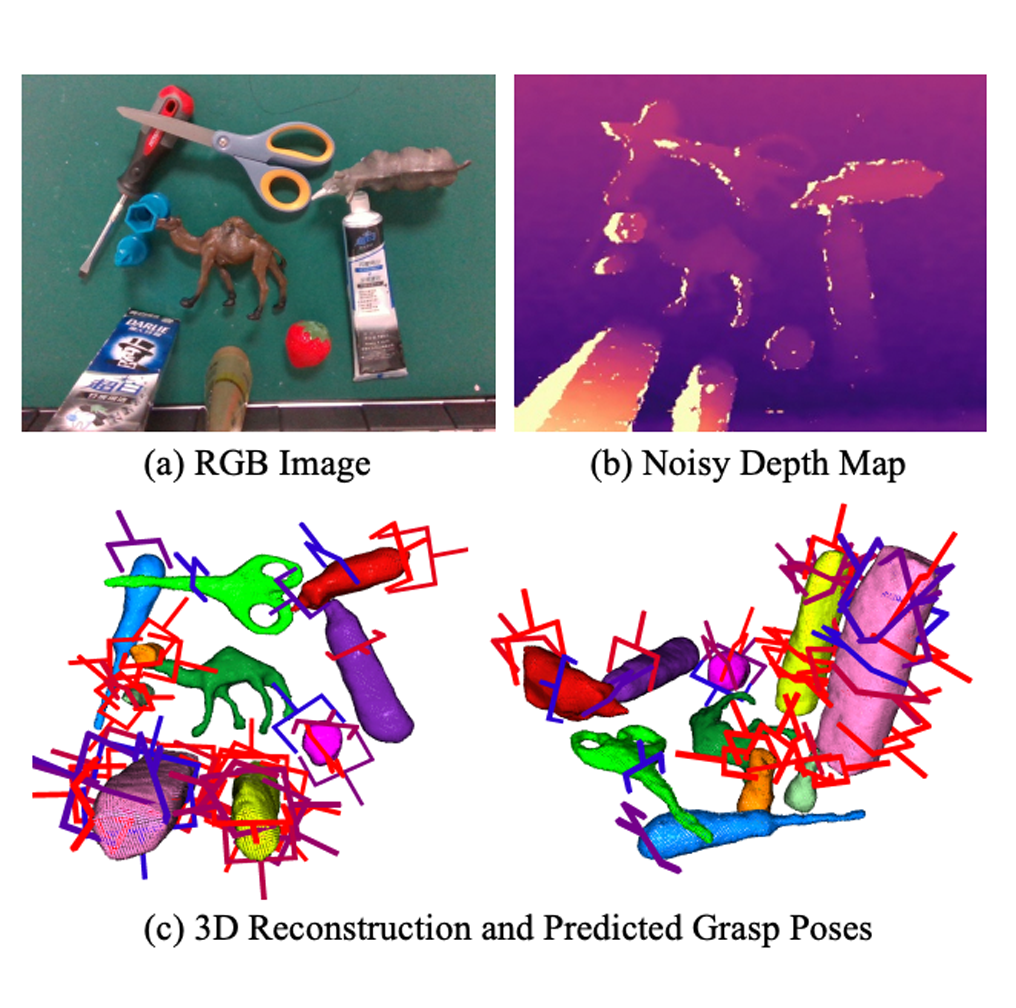
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data. READ MORE
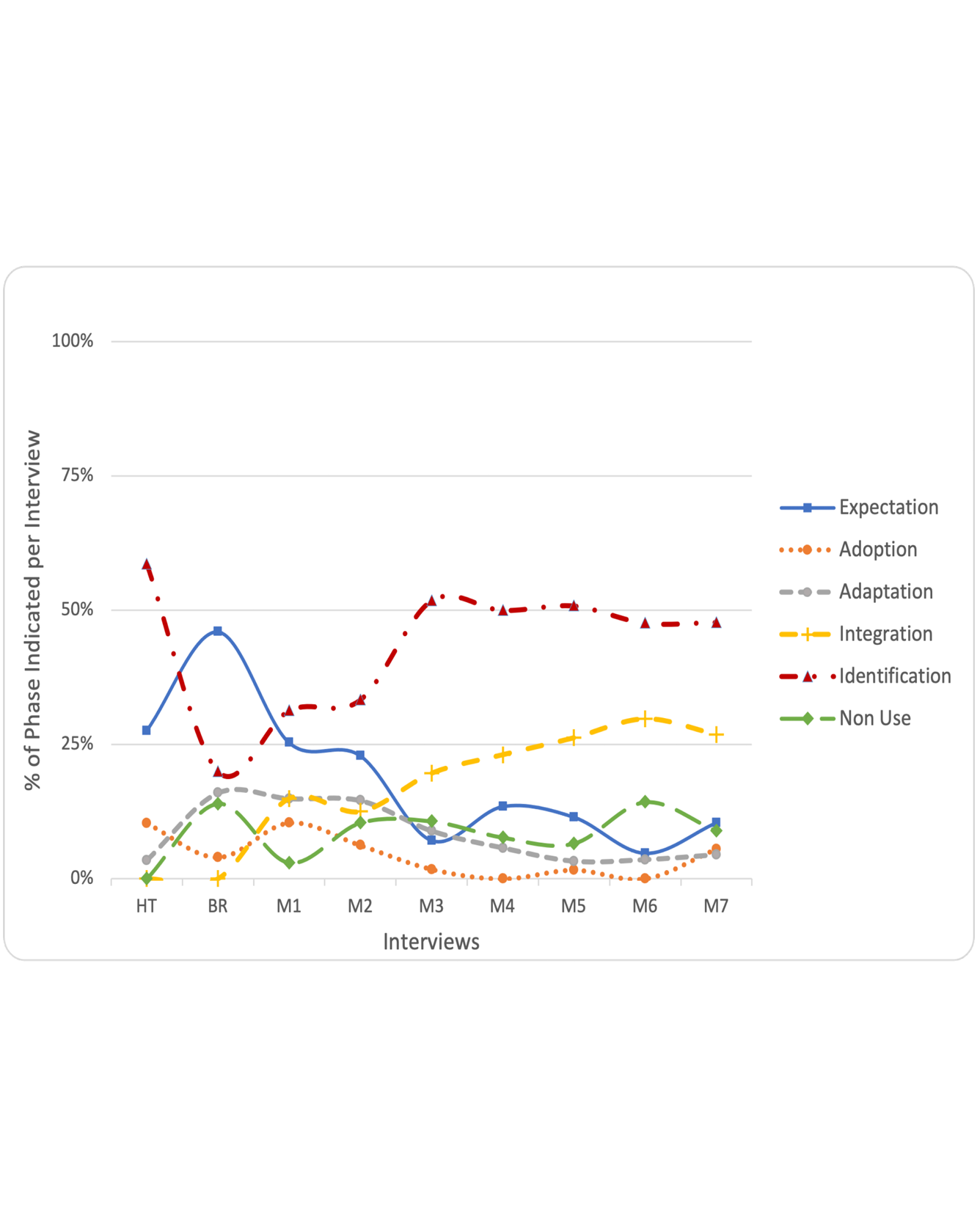
Loneliness has a direct impact on mental and physical health. This is especially relevant to older adults. In prior studies, socially isolated older adults wanted technology that would help them feel more physically present even across distances, such as telepresence robots. However, how useful this technology can be directly depends on whether people accept it over the long term. In this paper, we describe a case study in which we introduced telepresence robots into homes of older adults for seven months. We investigate how older adults’ progression through acceptance phases ebbed and flowed. We describe primary factors that affected speed of progression through acceptance phases: solving problems with technology, life situations (business vs. routines), and personality. We introduce example personas based on this case study. We also propose changes to the longitudinal technology-acceptance framework to take this more nuanced view into account. These outcomes will help future researchers and practitioners to better understand and influence longitudinal technology acceptance.
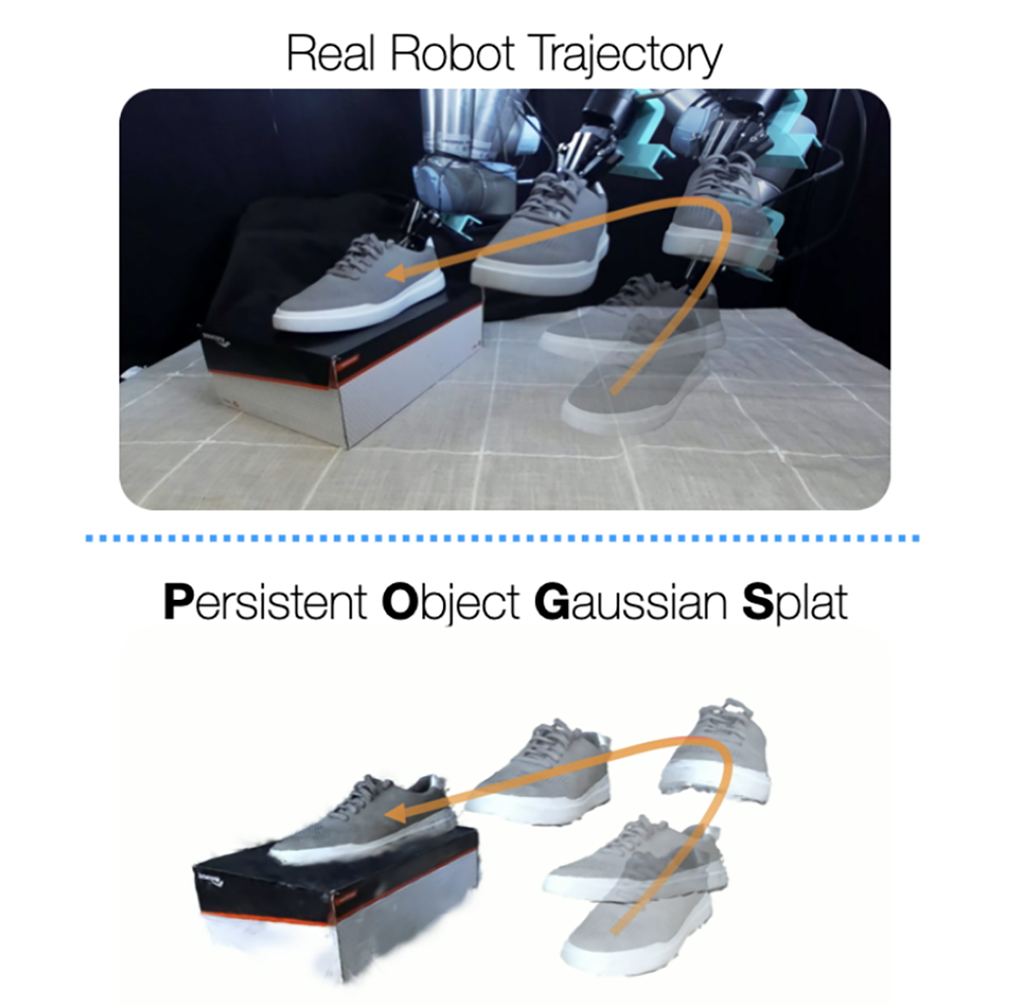
Tracking and manipulating irregularly-shaped, previously unseen objects in dynamic environments is important for robotic applications in manufacturing, assembly, and logistics. Recently introduced Gaussian Splats efficiently model object geometry, but lack persistent state estimation for task-oriented manipulation. We present Persistent Object Gaussian Splat (POGS), a system that embeds semantics, self-supervised visual features, and object grouping features into a compact representation that can be continuously updated to estimate the pose of scanned objects. POGS updates object states without requiring expensive rescanning or prior CAD models of objects. After an initial multi-view scene capture and training phase, POGS uses a single stereo camera to integrate depth estimates along with self-supervised vision encoder features for object pose estimation. POGS supports grasping, reorientation, and natural language-driven manipulation by refining object pose estimates, facilitating sequential object reset operations with human-induced object perturbations and tool servoing, where robots recover tool pose despite tool perturbations of up to 30°. POGS achieves up to 12 consecutive successful object resets and recovers from 80% of in-grasp tool perturbations. READ MORE
While abstraction is one of the best studied topics in psychology, there is little consensus on its relationship to valence and affect. Some studies have found that abstraction is associated with greater positivity, while other studies have led to the opposite conclusion. In this paper we suggest that a substantial part of this inconsistency can be attributed to the polysemy of the term abstraction. To address this problem, we use a framework developed by Iliev and Axelrod (Journal of psycholinguistic research, 46(3):715–729, 2017), who have proposed that abstraction should not be treated as a unitary construct, but should be split instead in at least two components. Concreteness is based on the proportion of sensory information in a concept, while precision is based on the aggregation of information corresponding to the concept’s position in a semantic taxonomy. While both of these components have been used as operationalizations of abstraction, they can have opposite effects on cognitive performance. Using this framework, we hypothesize that when abstraction is defined as a reduction of precision, it will be associated with greater positivity, but when it is defined as lack of concreteness, it will be associated with less positivity. We test these predictions in a novel study and we find empirical support for both hypotheses. These findings advance our understanding of the link between abstraction and valence, and further demonstrate the multi-component structure of abstraction.
