Featured Publications

All Publications
Autonomous vehicles (AVs) are increasingly being deployed in urban environments. However, most AVs operate without accounting for uncertainty inherent to perceiving the world. To remedy this disregard, uncertainty-aware planners have recently been developed that account for upstream perception and prediction uncertainty, generating more efficient motion plans without sacrificing safety. However, such planners may be sensitive to prediction uncertainty miscalibration, the magnitude of which has not yet been characterized. Towards this end, we perform a detailed analysis of the impact that perceptual uncertainty propagation and uncertainty calibration has on perception-based motion planning. We do so with a comparison between two novel prediction-planning architectures with varying levels of uncertainty incorporation on a largescale, real-world autonomous driving dataset. We find that, despite one model producing quantifiably better predictions, both methods produce similar motion plans with only minor differences. READ MORE
If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging—it requires the ability to both parse the 3D structure of the scene and correctly ground freeform language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Code will be available at https://ripl.github.io/Transcrib3D. READ MORE

This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we show that VTCD can be used for fine-grained action recognition and video object segmentation. READ MORE

Neural fields excel in computer vision and robotics due to their ability to understand the 3D visual world such as inferring semantics, geometry, and dynamics. Given the capabilities of neural fields in densely representing a 3D scene from 2D images, we ask the question: Can we scale their self-supervised pretraining, specifically using masked autoencoders, to generate effective 3D representations from posed RGB images. Owing to the astounding success of extending transformers to novel data modalities, we employ standard 3D Vision Transformers to suit the unique formulation of NeRFs. We leverage NeRF's volumetric grid as a dense input to the transformer, contrasting it with other 3D representations such as pointclouds where the information density can be uneven, and the representation is irregular. Due to the difficulty of applying masked autoencoders to an implicit representation, such as NeRF, we opt for extracting an explicit representation that canonicalizes scenes across domains by employing the camera trajectory for sampling. Our goal is made possible by masking random patches from NeRF's radiance and density grid and employing a standard 3D Swin Transformer to reconstruct the masked patches. In doing so, the model can learn the semantic and spatial structure of complete scenes. We pretrain this representation at scale on our proposed curated posed-RGB data, totaling over 1.8 million images. Once pretrained, the encoder is used for effective 3D transfer learning. Our novel self-supervised pretraining for NeRFs, NeRF-MAE, scales remarkably well and improves performance on various challenging 3D tasks. Utilizing unlabeled posed 2D data for pretraining, NeRF-MAE significantly outperforms self-supervised 3D pretraining and NeRF scene understanding baselines on Front3D and ScanNet datasets with an absolute performance improvement of over 20% AP50 and 8% AP25 for 3D object detection. READ MORE

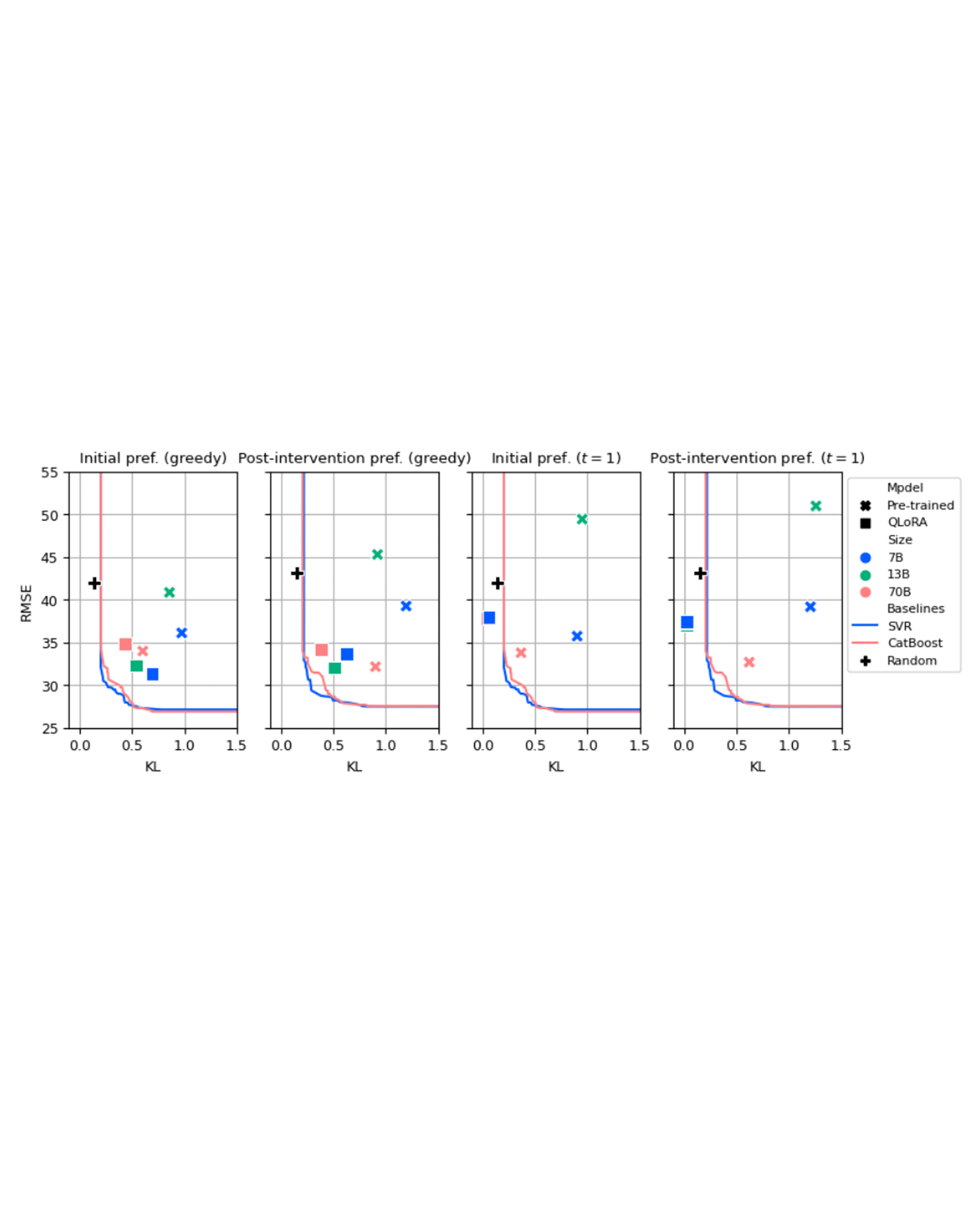
We consider the problem of aligning a large language model (LLM) to model the preferences of a human population. Modeling the beliefs, preferences, and behaviors of a specific population can be useful for a variety of different applications, such as conducting simulated focus groups for new products, conducting virtual surveys, and testing behavioral interventions, especially for interventions that are expensive, impractical, or unethical. Existing work has had mixed success using LLMs to accurately model human behavior in different contexts. We benchmark and evaluate two well-known fine-tuning approaches and evaluate the resulting populations on their ability to match the preferences of real human respondents on a survey of preferences for battery electric vehicles (BEVs). We evaluate our models against their ability to match population-wide statistics as well as their ability to match individual responses, and we investigate the role of temperature in controlling the trade-offs between these two. Additionally, we propose and evaluate a novel loss term to improve model performance on responses that require a numeric response. READ MORE
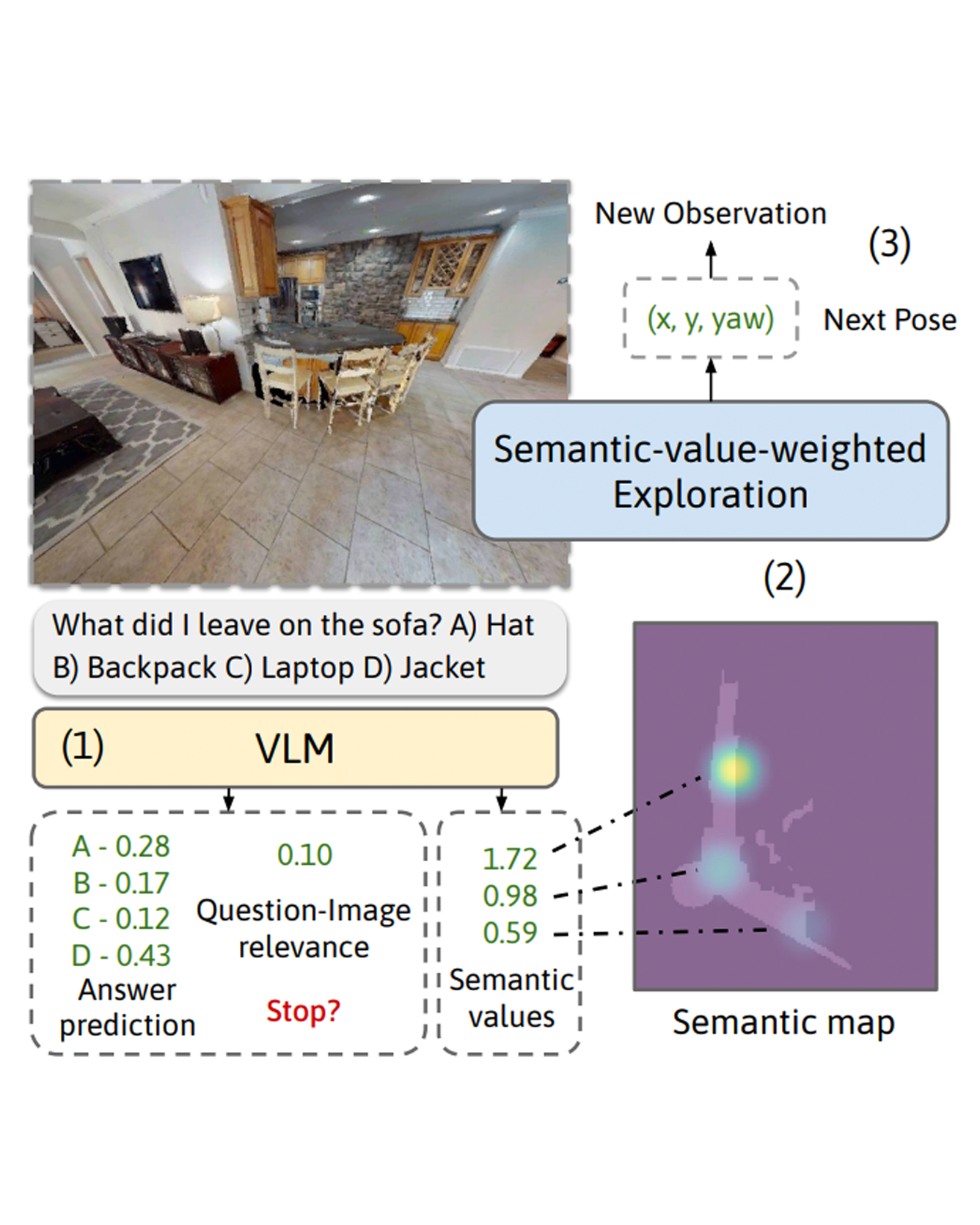
We consider the problem of Embodied Question Answering (EQA), which refers to settings where an embodied agent such as a robot needs to actively explore an environment to gather information until it is confident about the answer to a question. In this work, we leverage the strong semantic reasoning capabilities of large vision-language models (VLMs) to efficiently explore and answer such questions. However, there are two main challenges when using VLMs in EQA: they do not have an internal memory for mapping the scene to be able to plan how to explore over time, and their confidence can be miscalibrated and can cause the robot to prematurely stop exploration or over-explore. We propose a method that first builds a semantic map of the scene based on depth information and via visual prompting of a VLM - leveraging its vast knowledge of relevant regions of the scene for exploration. Next, we use conformal prediction to calibrate the VLM's question answering confidence, allowing the robot to know when to stop exploration - leading to a more calibrated and efficient exploration strategy. To test our framework in simulation, we also contribute a new EQA dataset with diverse, realistic human-robot scenarios and scenes built upon the Habitat-Matterport 3D Research Dataset (HM3D). Both simulated and real robot experiments show our proposed approach improves the performance and efficiency over baselines that do no leverage VLM for exploration or do not calibrate its confidence. READ MORE
We present a 3D shape completion method that recovers the complete geometry of multiple objects in complex scenes from a single RGB-D image. Despite notable advancements in single object 3D shape completion, high-quality reconstructions in highly cluttered real-world multi-object scenes remains a challenge. To address this issue, we propose OctMAE, an architecture that leverages an Octree U-Net and a latent 3D MAE to achieve high-quality and near real-time multi-object shape completion through both local and global geometric reasoning. Because a naïve 3D MAE can be computationally intractable and memory intensive even in the latent space, we introduce a novel occlusion masking strategy and adopt 3D rotary embeddings, which significantly improves the runtime and shape completion quality. To generalize to a wide range of objects in diverse scenes, we create a large-scale photorealistic dataset, featuring a diverse set of 12K 3D object models from the Objaverse dataset which are rendered in multi-object scenes with physics-based positioning. Our method outperforms the current state-of-the-art on both synthetic and real-world datasets and demonstrates a strong zero-shot capability. READ MORE

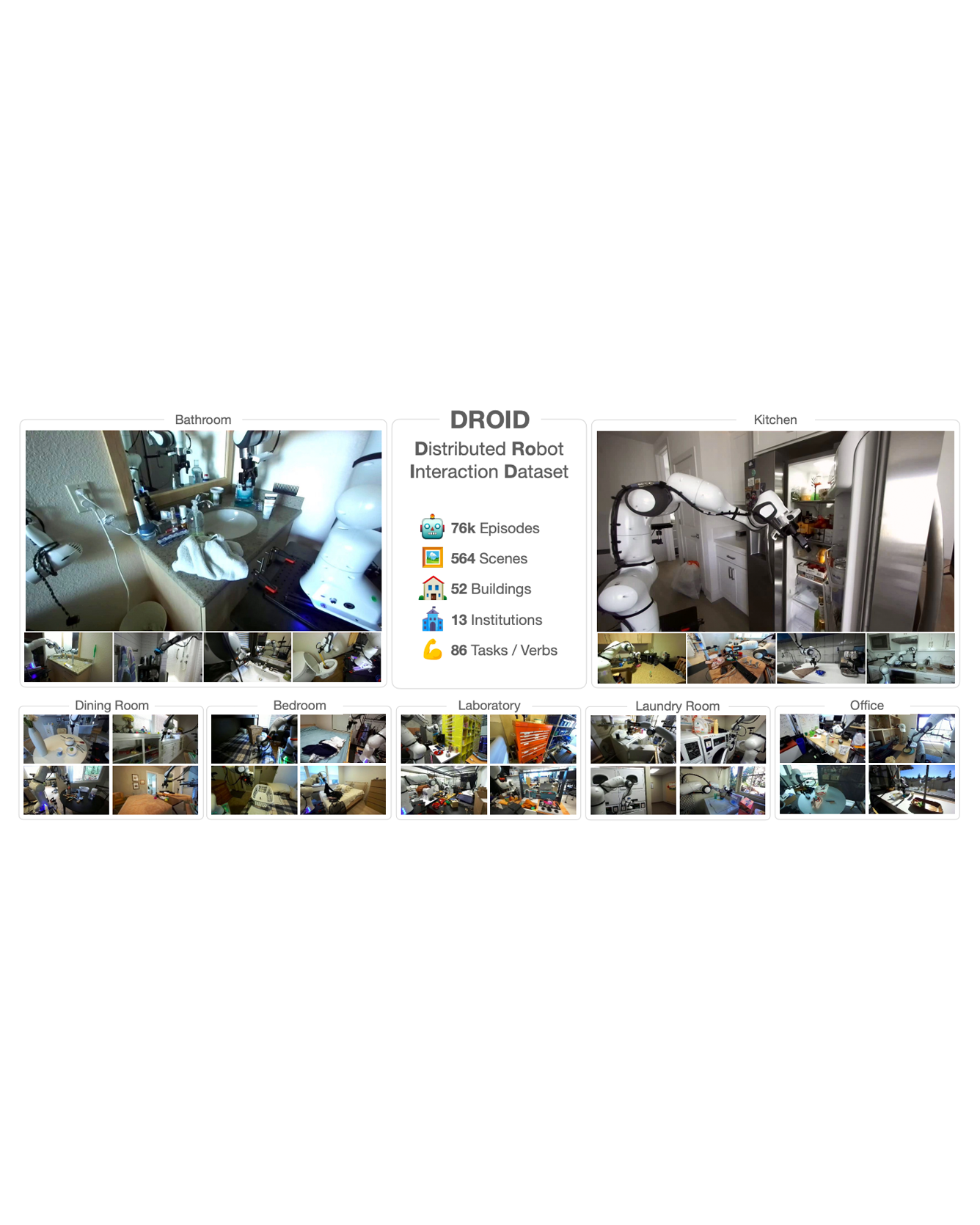
The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup. READ MORE
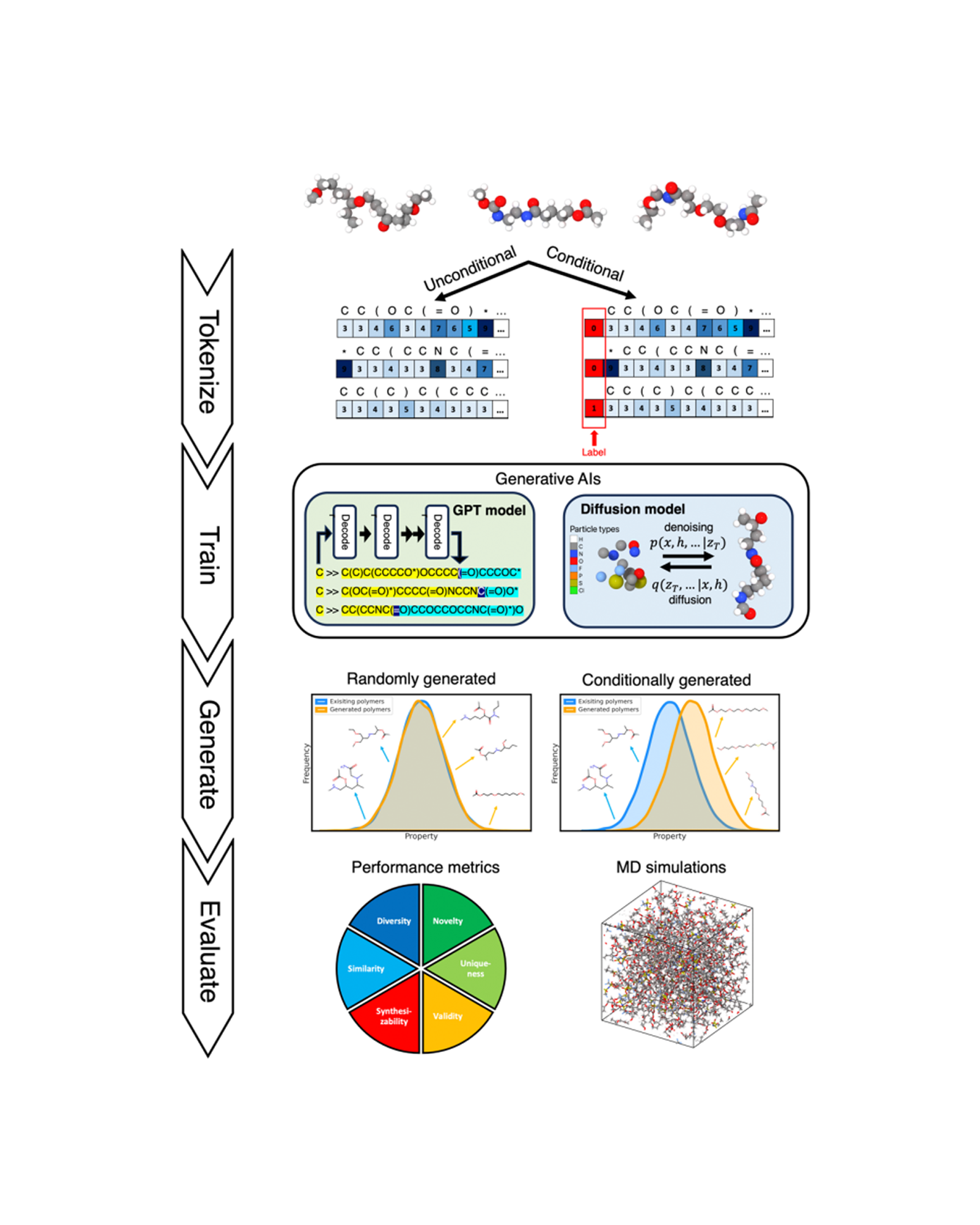
Solid polymer electrolytes hold significant promise as materials for next-generation batteries due to their superior safety performance, enhanced specific energy, and extended lifespans compared to liquid electrolytes. However, the material's low ionic conductivity impedes its commercialization, and the vast polymer space poses significant challenges for the screening and design. In this study, we assess the capabilities of generative artificial intelligence (AI) for the de novo design of polymer electrolytes. To optimize the generation, we compare different deep learning architectures, including both GPT-based and diffusion-based models, and benchmark the results with hyperparameter tuning. We further employ various evaluation metrics and full-atom molecular dynamics simulations to assess the performance of different generative model architectures and to validate the top candidates produced by each model. Out of only 45 candidates being tested, we discovered 17 polymers that achieve superior ionic conductivity better than any other polymers in our database, with some of them doubling the conductivity value. In addition, by adopting a pretraining and fine-tuning methodology, we significantly improve the efficacy of our generative models, achieving quicker convergence, enhanced performance with limited data, and greater diversity. Using the proposed method, we can easily generate a large number of novel, diverse, and valid polymers, with a chance of synthesizability, enabling us to identify promising candidates with markedly improved efficiency. READ MORE
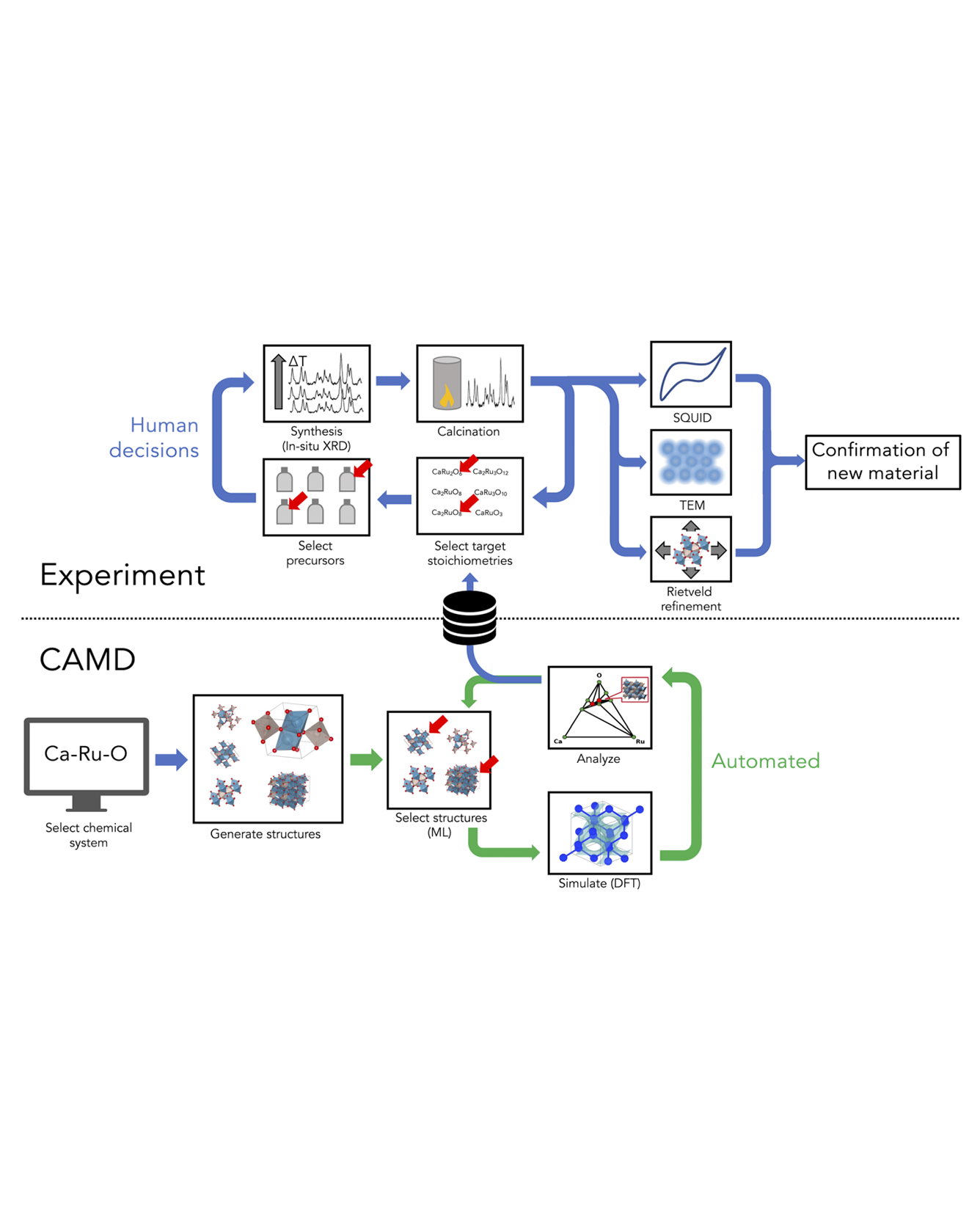
Exploratory synthesis has been the main generator of new inorganic materials for decades. However, our Edisonian and bias-prone processes of synthetic exploration alone are no longer sufficient in an age that demands rapid advances in materials development. In this work, we demonstrate an end-to-end attempt towards systematic, computer-aided discovery and laboratory synthesis of inorganic crystalline compounds as a modern alternative to purely exploratory synthesis. Our approach initializes materials discovery campaigns by autonomously mapping the synthetic feasibility of a chemical system using density functional theory with AI feedback. Following expert-driven down-selection of newly generated phases, we use solid-state synthesis and in situ characterization via hot-stage X-ray diffraction in order to realize new ternary oxide phases experimentally. We applied this strategy in six ternary transition-metal oxide chemistries previously considered well-explored, one of which culminated in the discovery of two novel phases of calcium ruthenates. Detailed characterization using room temperature X-ray powder diffraction, 4D-STEM and SQUID measurements identifies the structure and composition and confirms distinct properties, including distinct defect concentrations, of one of the new phases formed in our experimental campaigns. While the discovery of a new material guided by AI and DFT theory represents a milestone, our procedure and results also highlight a number of critical gaps in the process that can inform future efforts towards the improvement of AI-coupled methodologies. READ MORE