Featured Publications

All Publications
A Space Resonating with Being is a visual-audio interactive artwork where the visual art on a 55-inch display changes in response to external intervention, focusing on experiencing the space as a living organism. The real-time visual effects that appear on the display reflect the local natural environment when there is no viewer interaction, symbolically integrating the natural environment into a space. When the viewer interacts with the artwork, it is transformed by an algorithm based on physiological signals from the viewer. The artwork changes based on their biorhythms, such as their breathing and heart rate, and they enjoy a unique experience where the art space responds to them, providing a dynamic and colorful visual-audio experience. The artwork draws attention to the impact of the viewer on space and how artwork affects the viewer’s internal world perception through the experience of the artwork gradually morphing to resonate with them. READ MORE

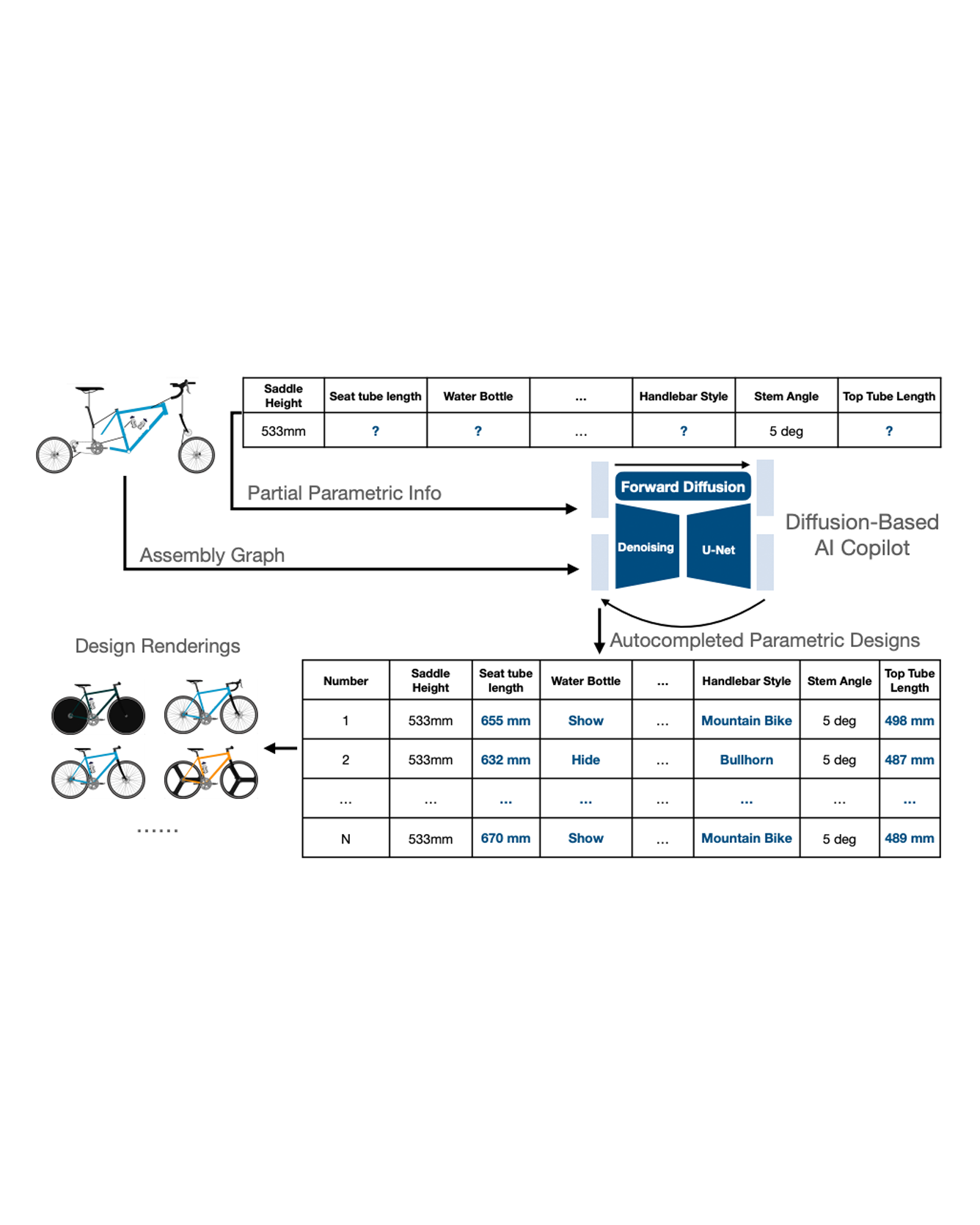
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design. READ MORE
Advances in autonomous driving provide an opportunity for AI-assisted driving instruction that directly addresses the critical need for human driving improvement. How should an AI instructor convey information to promote learning? In a pre-post experiment (n = 41), we tested the impact of an AI Coach’s explanatory communications modeled after performance driving expert instructions. Participants were divided into four (4) groups to assess two (2) dimensions of the AI coach’s explanations: information type (‘what’ and ‘why’-type explanations) and presentation modality (auditory and visual). We compare how different explanatory techniques impact driving performance, cognitive load, confidence, expertise, and trust via observational learning. Through interview, we delineate participant learning processes. Results show AI coaching can effectively teach performance driving skills to novices. We find the type and modality of information influences performance outcomes. Differences in how successfully participants learned are attributed to how information directs attention, mitigates uncertainty, and influences overload experienced by participants. Results suggest efficient, modality-appropriate explanations should be opted for when designing effective HMI communications that can instruct without overwhelming. Further, results support the need to align communications with human learning and cognitive processes. We provide eight design implications for future autonomous vehicle HMI and AI coach design. READ MORE

Social technology can improve the quality of social lives of older adults (OAs) and mitigate negative mental and physical health outcomes. When people engage with technology, they can do so to stimulate social interaction (stimulation hypothesis) or disengage from their real world (disengagement hypothesis), according to Nowland et al.‘s model of the relationship between social Internet use and loneliness. External events, such as large periods of social isolation like during the COVID-19 pandemic, can also affect whether people use technology in line with the stimulation or disengagement hypothesis. We examined how the COVID-19 pandemic affected the social challenges OAs faced and their expectations for robot technology to solve their challenges. We conducted two participatory design (PD) workshops with OAs during and after the COVID-19 pandemic. During the pandemic, OAs’ primary concern was distanced communication with family members, with a prevalent desire to assist them through technology. They also wanted to share experiences socially, as such OA’s attitude toward technology could be explained mostly by the stimulation hypothesis. However, after COVID-19 the pandemic, their focus shifted towards their own wellbeing. Social isolation and loneliness were already significant issues for OAs, and these were exacerbated by the COVID-19 pandemic. Therefore, such OAs’ attitudes toward technology after the pandemic could be explained mostly by the disengagement hypothesis. This clearly reflect the OA’s current situation that they have been getting further digitally excluded due to rapid technological development during the pandemic. Both during and after the pandemic, OAs found it important to have technologies that were easy to use, which would reduce their digital exclusion. After the pandemic, we found this especially in relation to newly developed technologies meant to help people keep at a distance. To effectively integrate these technologies and avoid excluding large parts of the population, society must address the social challenges faced by OAs. READ MORE
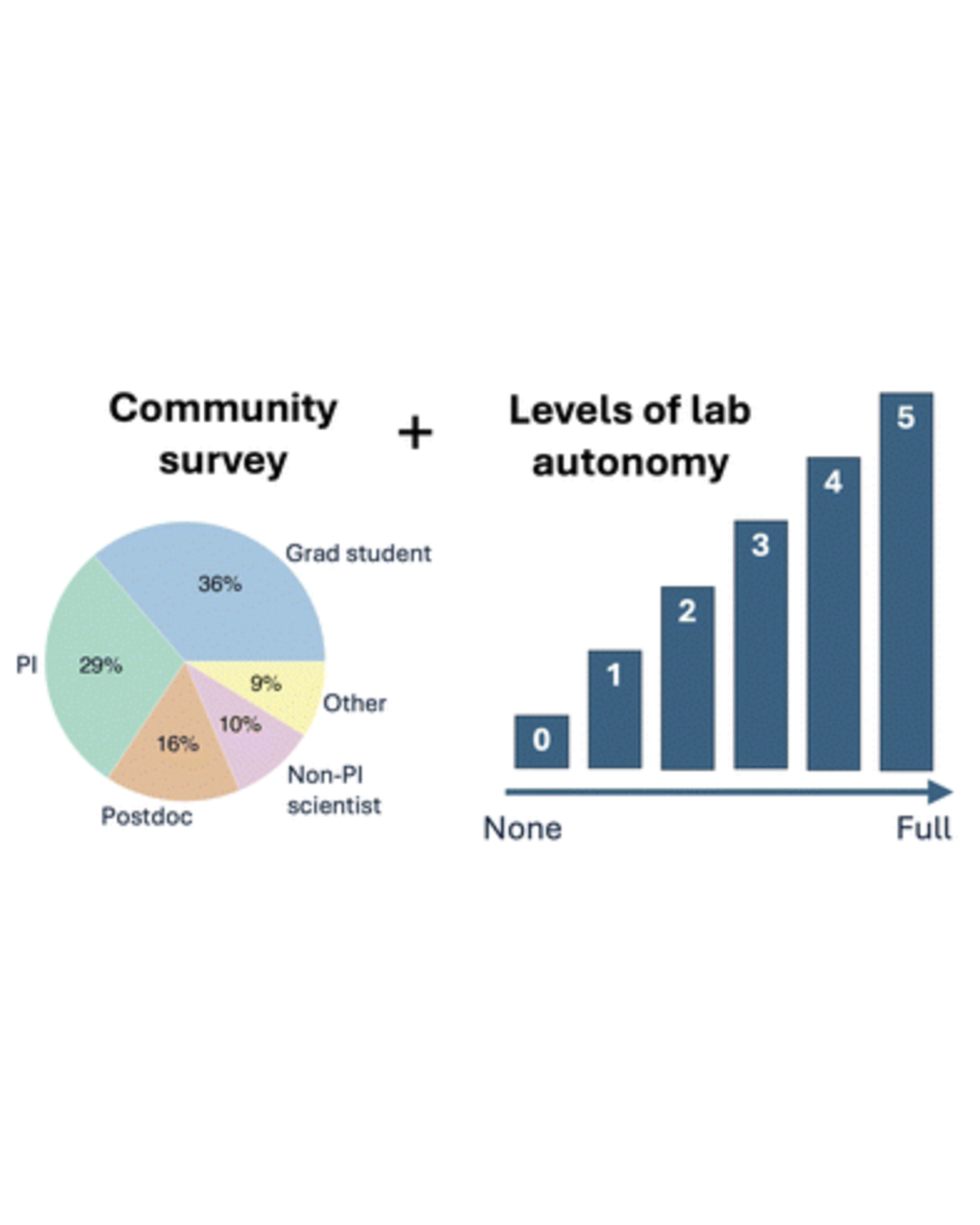
What are researchers' motivations and challenges related to automation and autonomy in materials science laboratories? Our survey on this topic received 102 responses from researchers across a variety of institutions and in a variety of roles. Accelerated discovery was a clear theme in the responses, and another theme was concern about the role of human researchers. Survey respondents shared a variety of use cases targeting accelerated materials discovery, including examples where partial automation is preferred over full self-driving laboratories. Building on the observed patterns of researcher priorities and needs, we propose a framework for levels of laboratory autonomy from non-automated (L0) to fully autonomous (L5). READ MORE
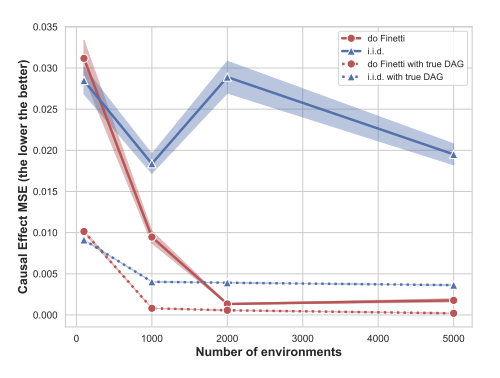
We study causal effect estimation in a setting where the data are not i.i.d. (independent and identically distributed). We focus on exchangeable data satisfying an assumption of independent causal mechanisms. Traditional causal effect estimation frameworks, e.g., relying on structural causal models and do-calculus, are typically limited to i.i.d. data and do not extend to more general exchangeable generative processes, which naturally arise in multi-environment data. To address this gap, we develop a generalized framework for exchangeable data and introduce a truncated factorization formula that facilitates both the identification and estimation of causal effects in our setting. To illustrate potential applications, we introduce a causal Pólya urn model and demonstrate how intervention propagates effects in exchangeable data settings. Finally, we develop an algorithm that performs simultaneous causal discovery and effect estimation given multi-environment data.
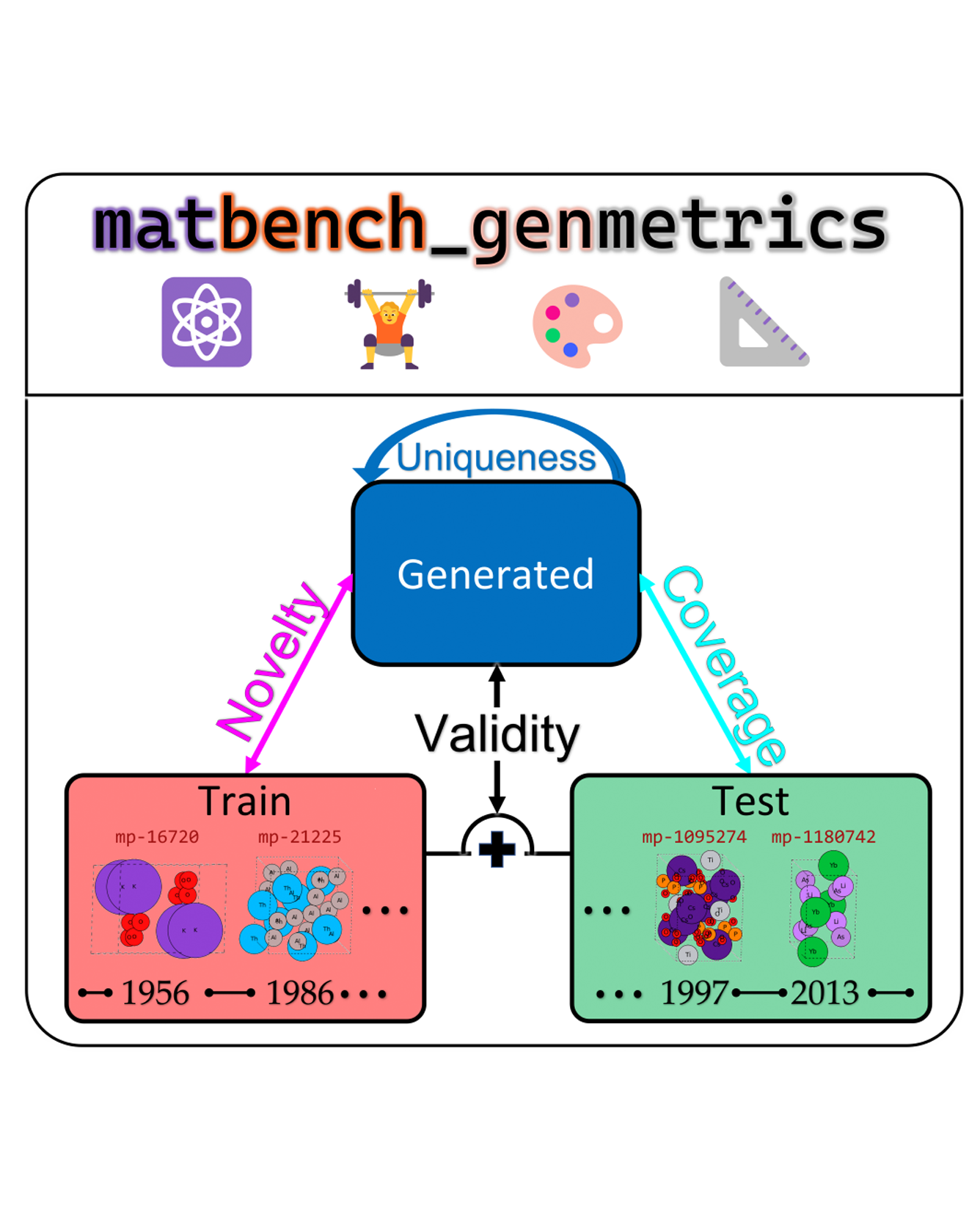
The progress of a machine learning field is both tracked and propelled through the development of robust benchmarks. While significant progress has been made to create standardized, easy-to-use benchmarks for molecular discovery e.g., (Brown et al., 2019), this remains a challenge for solid-state material discovery (Alverson et al., 2024; Xie et al., 2022; Zhao et al., 2023). To address this limitation, we propose matbench-genmetrics, an open-source Python library for benchmarking generative models for crystal structures. We use four evaluation metrics inspired by Guacamol (Brown et al., 2019) and Crystal Diffusion Variational AutoEncoder (CDVAE) (Xie et al., 2022)—validity, coverage, novelty, and uniqueness—to assess performance on Materials Project data splits using timeline-based cross-validation. We believe that matbench-genmetrics will provide the standardization and convenience required for rigorous benchmarking of crystal structure generative models. READ MORE
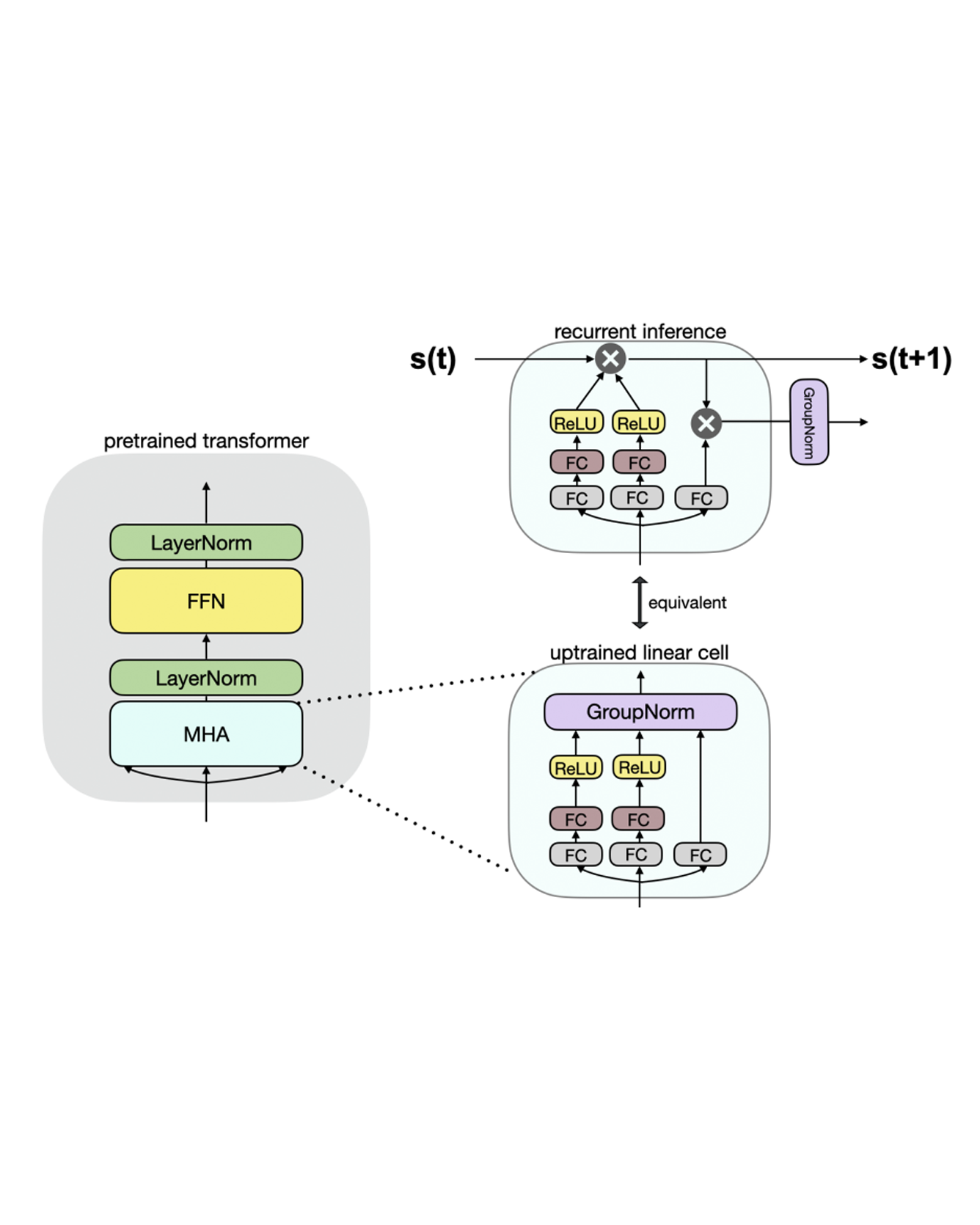
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm. READ MORE
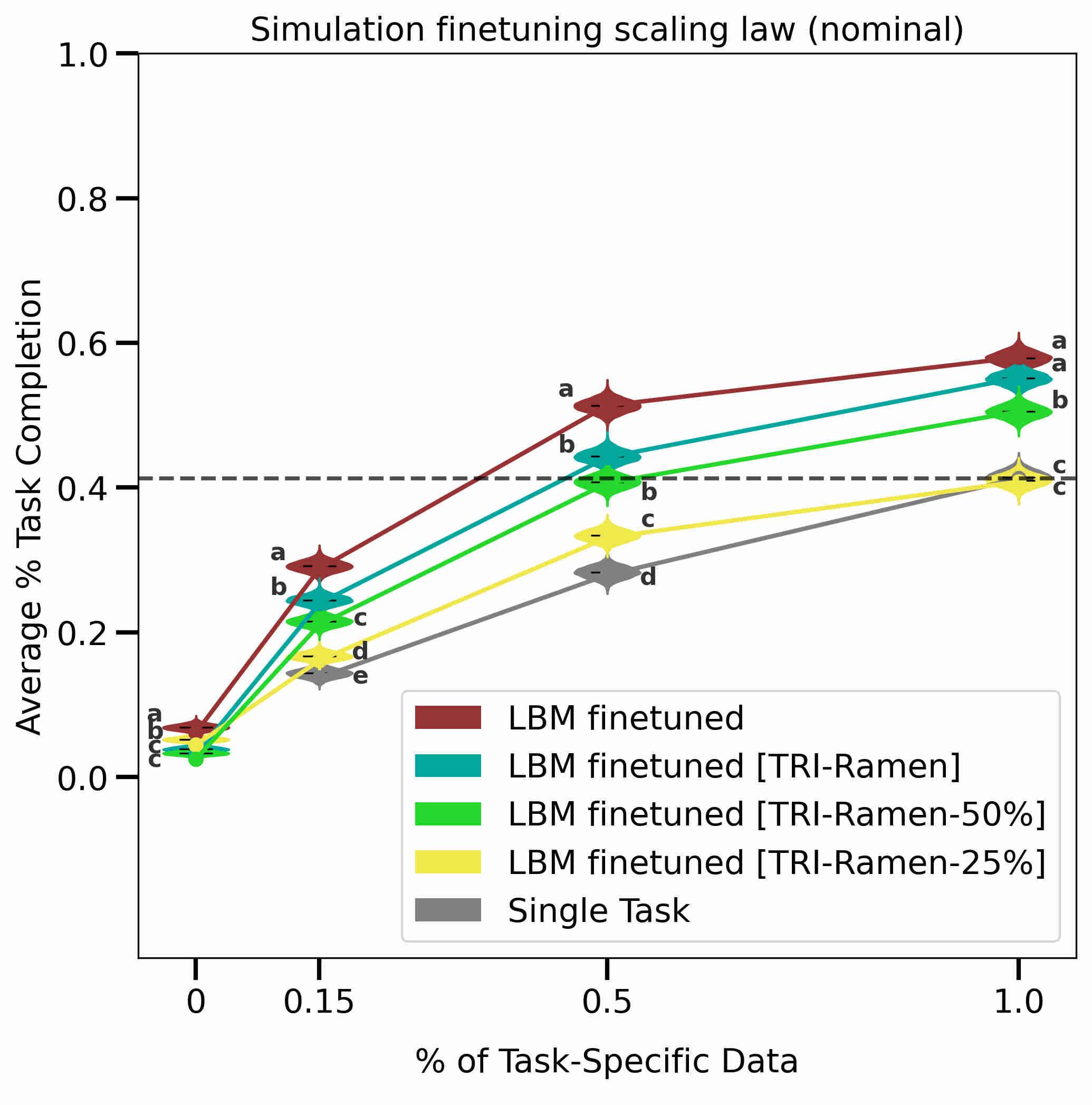
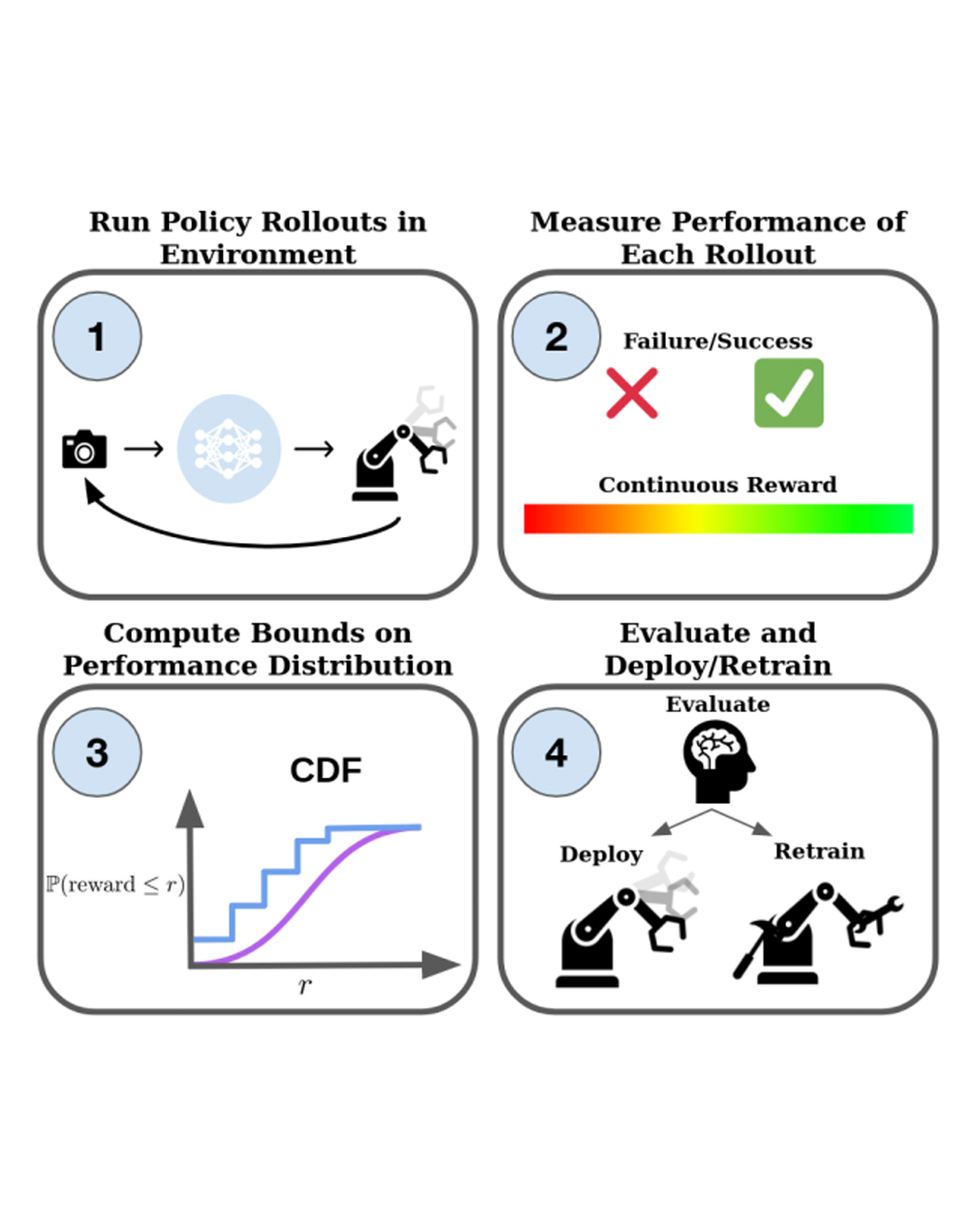
With the rise of stochastic generative models in robot policy learning, end-to-end visuomotor policies are increasingly successful at solving complex tasks by learning from human demonstrations. Nevertheless, since real-world evaluation costs afford users only a small number of policy rollouts, it remains a challenge to accurately gauge the performance of such policies. This is exacerbated by distribution shifts causing unpredictable changes in performance during deployment. To rigorously evaluate behavior cloning policies, we present a framework that provides a tight lower-bound on robot performance in an arbitrary environment, using a minimal number of experimental policy rollouts. Notably, by applying the standard stochastic ordering to robot performance distributions, we provide a worst-case bound on the entire distribution of performance (via bounds on the cumulative distribution function) for a given task. We build upon established statistical results to ensure that the bounds hold with a user-specified confidence level and tightness, and are constructed from as few policy rollouts as possible. In experiments we evaluate policies for visuomotor manipulation in both simulation and hardware. Specifically, we (i) empirically validate the guarantees of the bounds in simulated manipulation settings, (ii) find the degree to which a learned policy deployed on hardware generalizes to new real-world environments, and (iii) rigorously compare two policies tested in out-of-distribution settings. Our experimental data, code, and implementation of confidence bounds are open-source. READ MORE
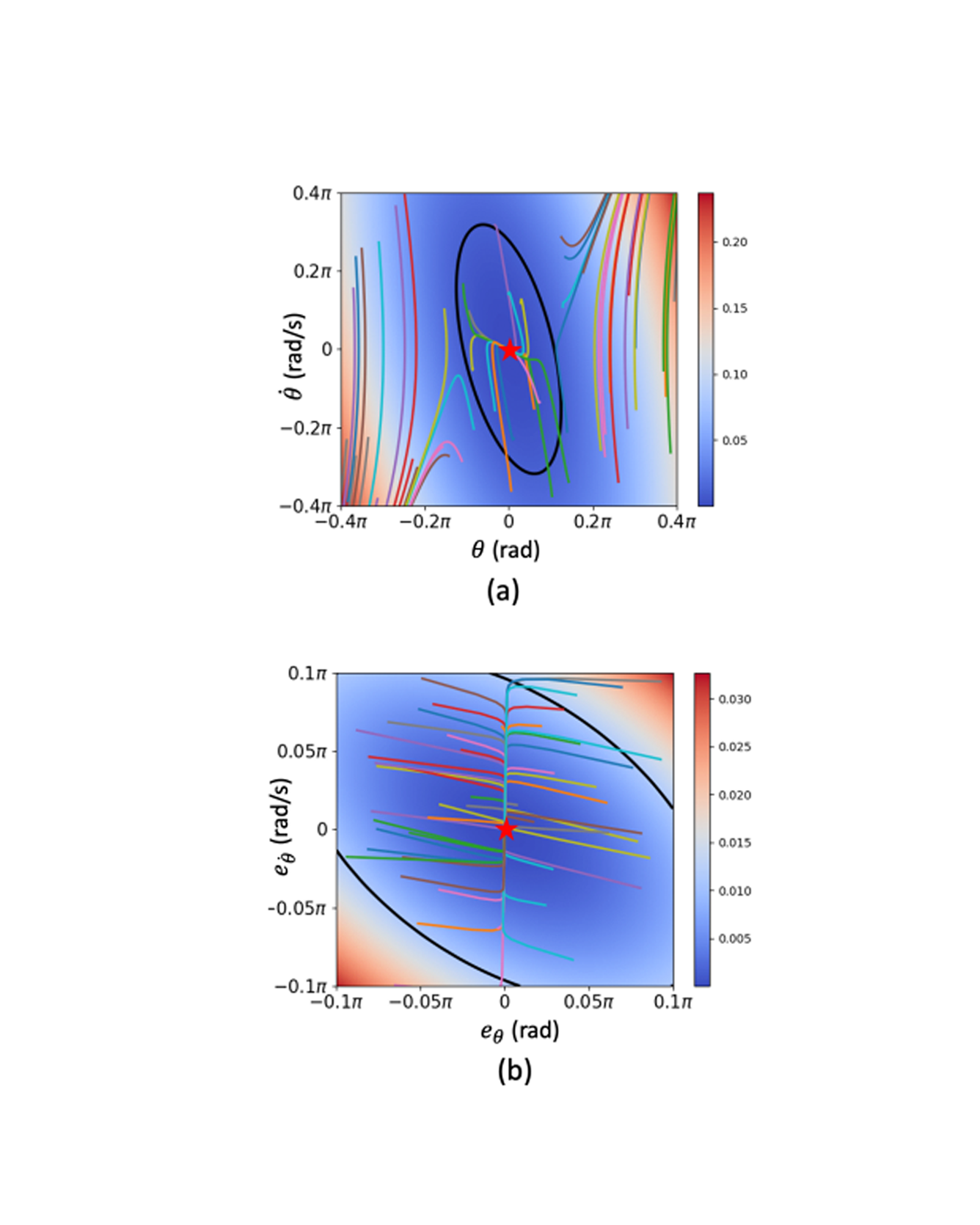
Learning-based neural-network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers for sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. READ MORE