Featured Publications

All Publications
This work addresses the challenge of streamed video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. We argue that sharing contextual information between frames or clips is pivotal in fostering temporal consistency. Thus, instead of directly developing a depth estimator from scratch, we reformulate this predictive task into a conditional generation problem to provide contextual information within a clip and across clips. Specifically, we propose a consistent context-aware training and inference strategy for arbitrarily long videos to provide cross-clip context. We sample independent noise levels for each frame within a clip during training while using a sliding window strategy and initializing overlapping frames with previously predicted frames without adding noise. Moreover, we design an effective training strategy to provide context within a clip. Extensive experimental results validate our design choices and demonstrate the superiority of our approach, dubbed ChronoDepth. Project page: this https URL. READ MORE

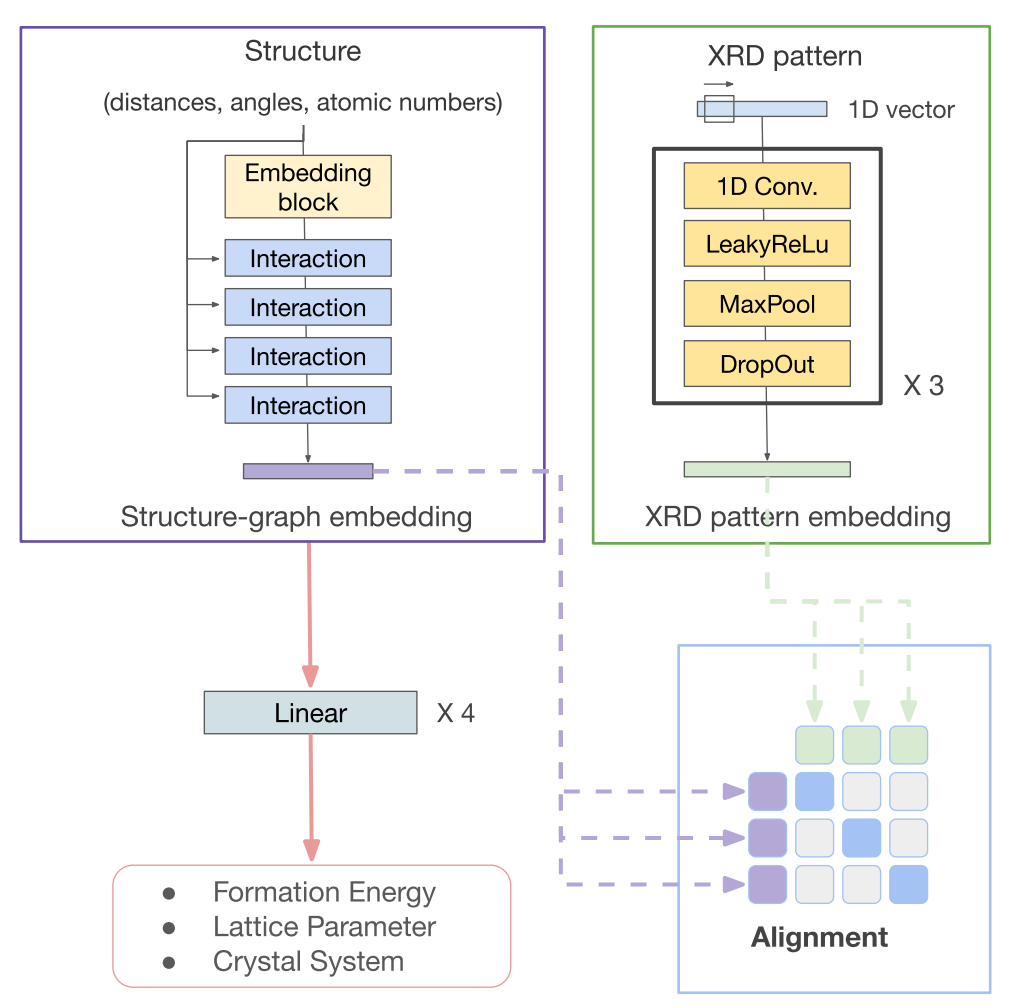
Materials science datasets are inherently heterogeneous and are available in different modalities such as characterization spectra, atomic structures, microscopic images, and text-based synthesis conditions. The advancements in multi-modal learning, particularly in vision and language models, have opened new avenues for integrating data in different forms. In this work, we evaluate common techniques in multi-modal learning (alignment and fusion) in unifying some of the most important modalities in materials science: atomic structure, X-ray diffraction patterns (XRD), and composition. We show that structure graph modality can be enhanced by aligning with XRD patterns. Additionally, we show that aligning and fusing more experimentally accessible data formats, such as XRD patterns and compositions, can create more robust joint embeddings than individual modalities across various tasks. This lays the groundwork for future studies aiming to exploit the full potential of multi-modal data in materials science, facilitating more informed decision-making in materials design and discovery. READ MORE
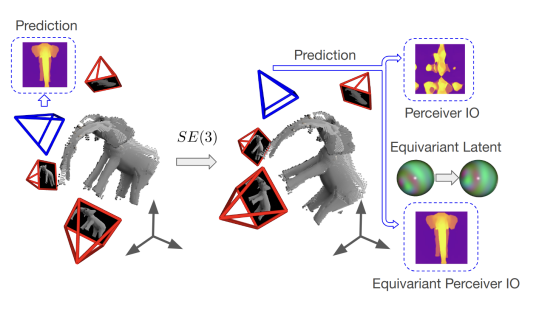
Incorporating inductive bias by embedding geometric entities (such as rays) as input has proven successful in multi-view learning. However, the methods adopting this technique typically lack equivariance, which is crucial for effective 3D learning. Equivariance serves as a valuable inductive prior, aiding in the generation of robust multi-view features for 3D scene understanding. In this paper, we explore the application of equivariant multi-view learning to depth estimation, not only recognizing its significance for computer vision and robotics but also addressing the limitations of previous research. Most prior studies have either overlooked equivariance in this setting or achieved only approximate equivariance through data augmentation, which often leads to inconsistencies across different reference frames. To address this issue, we propose to embed SE(3) equivariance into the Perceiver IO architecture. We employ Spherical Harmonics for positional encoding to ensure 3D rotation equivariance, and develop a specialized equivariant encoder and decoder within the Perceiver IO architecture. To validate our model, we applied it to the task of stereo depth estimation, achieving state of the art results on real-world datasets without explicit geometric constraints or extensive data augmentation.
Material properties calculated using density functional theory (DFT) are often corrected to more closely match experimental values, but the most common correction method has flaws that lead to unphysical results and false positives in the material discovery process. In this work, we show that these flaws stem from the fact that only additive errors are considered, and we provide evidence that DFT predictions are likely subject to proportional error as well. We analyze the case of formation energy predictions since stability is a critical material property. We propose a simpler, linear formation energy correction method, which we call the 110% PBE correction, that models proportional error and thereby addresses the problems associated with the most common correction method. We demonstrate that the conclusions drawn from the 110% PBE correction method are more likely to be physically accurate. READ MORE
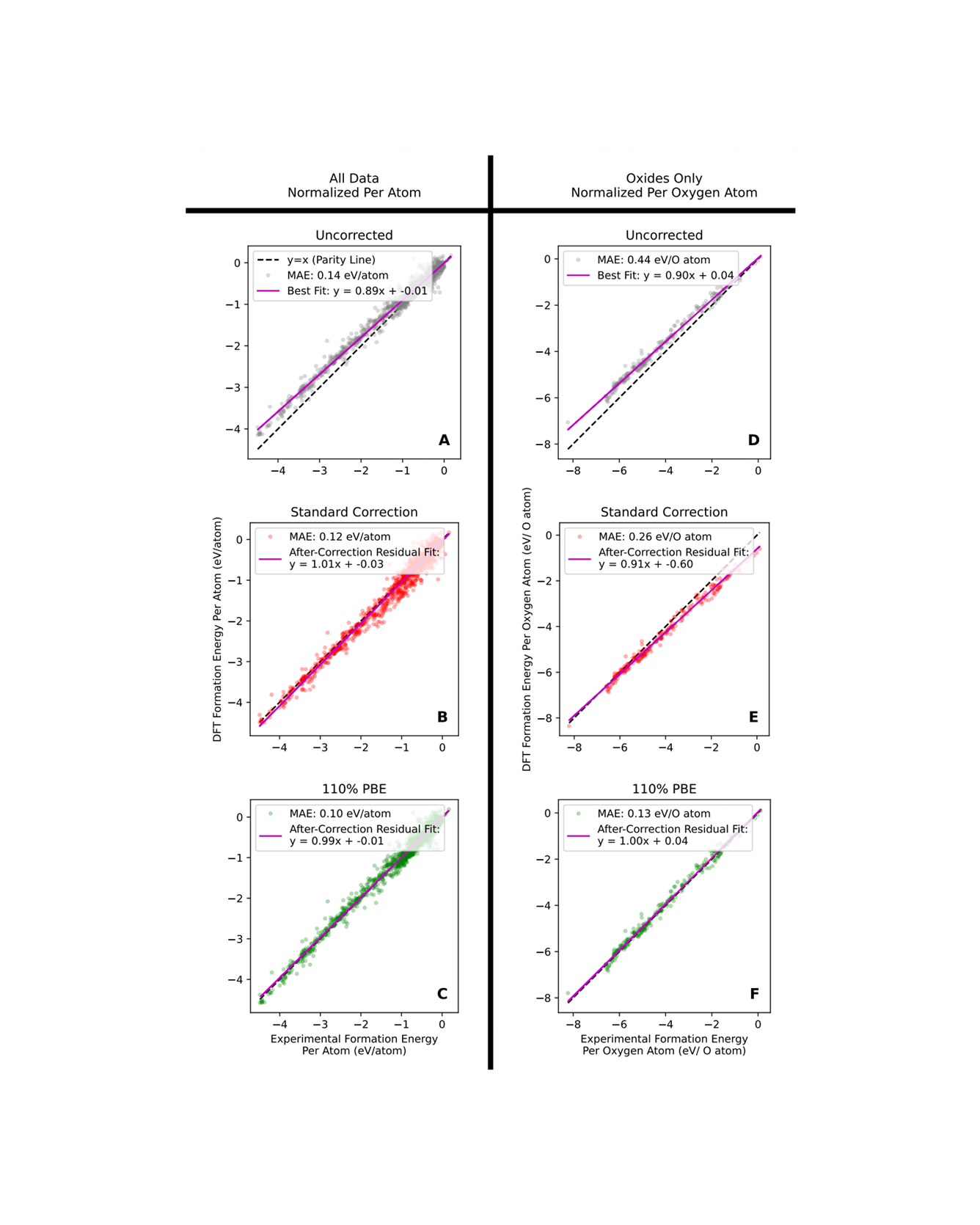
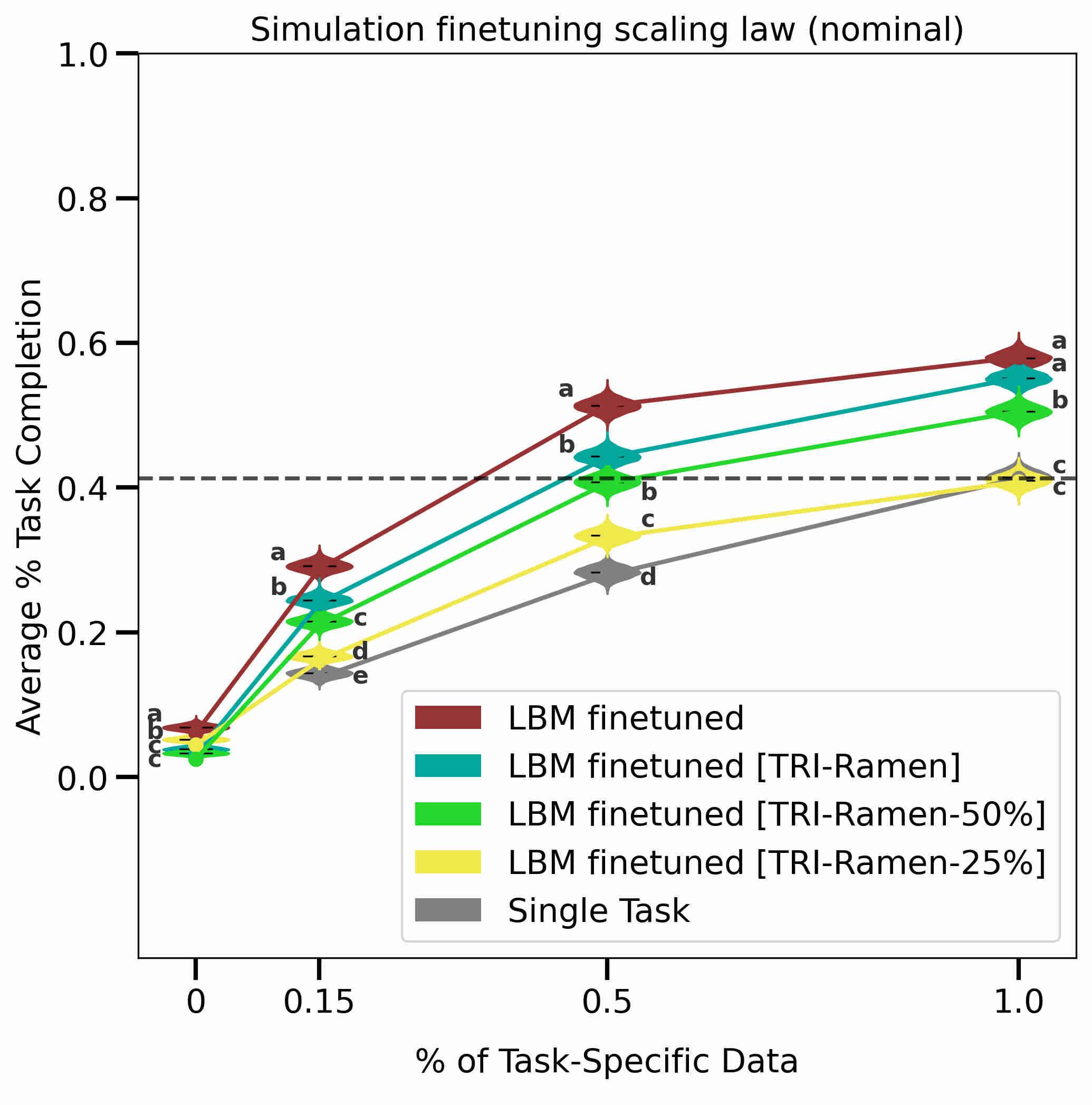
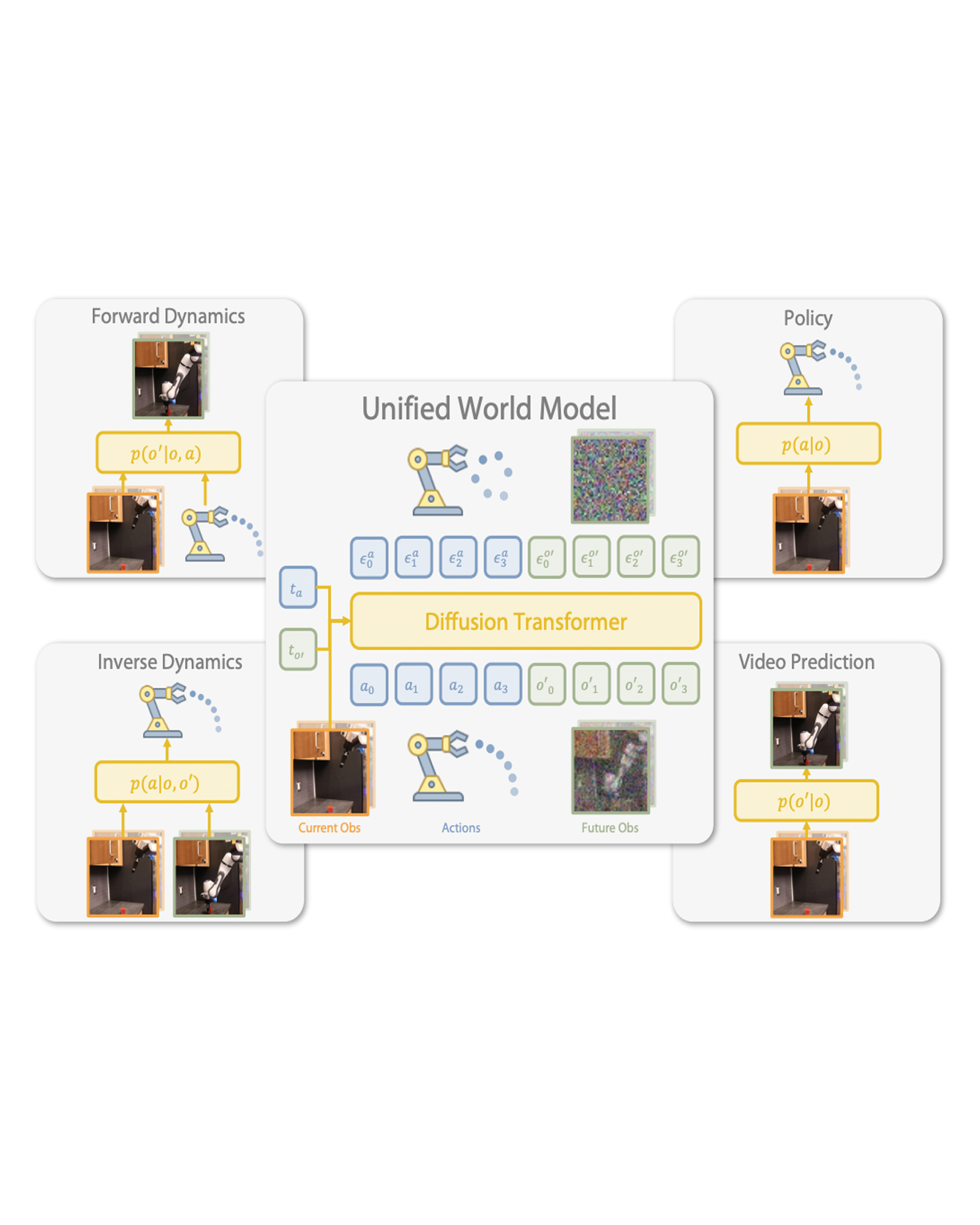
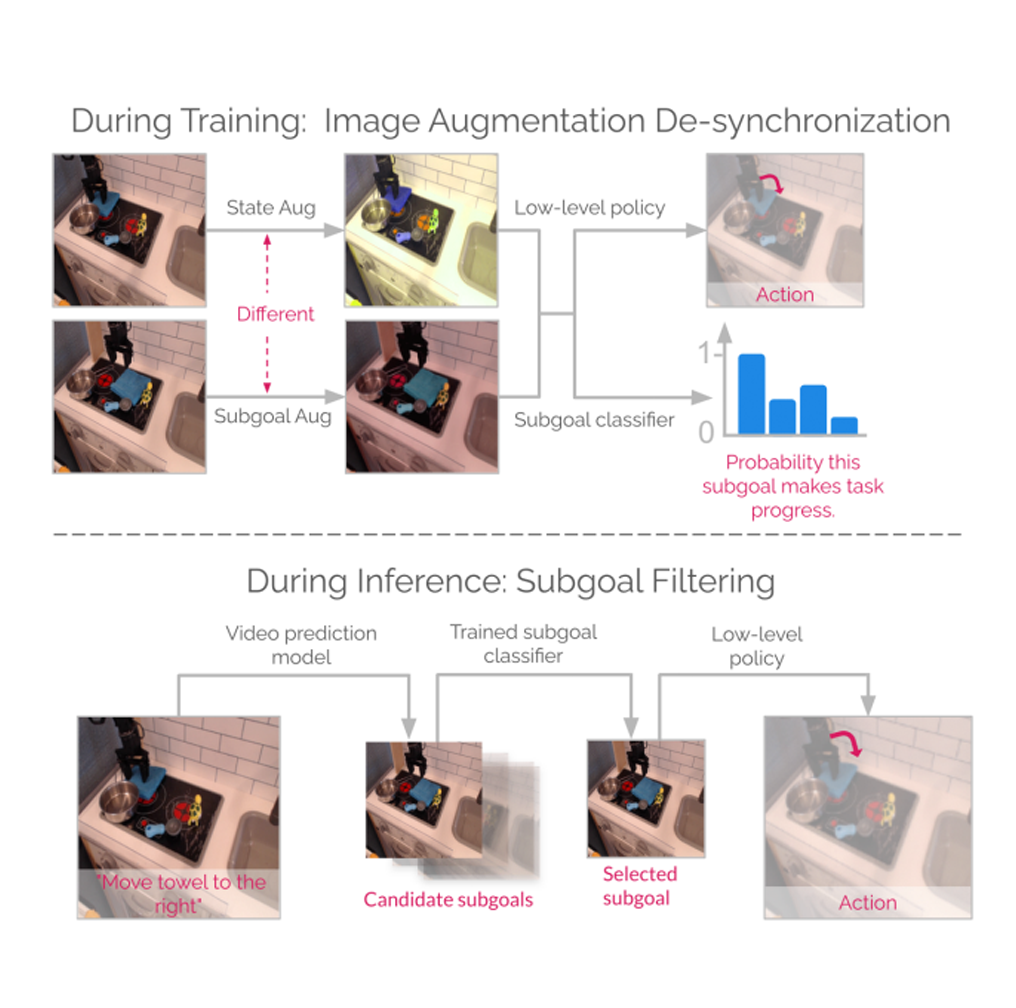
Image and video generative models that are pre-trained on Internet-scale data can greatly increase the generalization capacity of robot learning systems. These models can function as high-level planners, generating intermediate subgoals for low-level goal-conditioned policies to reach. However, the performance of these systems can be greatly bottlenecked by the interface between generative models and low-level controllers. For example, generative models may predict photorealistic yet physically infeasible frames that confuse low-level policies. Low-level policies may also be sensitive to subtle visual artifacts in generated goal images. This paper addresses these two facets of generalization, providing an interface to effectively "glue together" language-conditioned image or video prediction models with low-level goal-conditioned policies. Our method, Generative Hierarchical Imitation Learning-Glue (GHIL-Glue), filters out subgoals that do not lead to task progress and improves the robustness of goal-conditioned policies to generated subgoals with harmful visual artifacts. We find in extensive experiments in both simulated and real environments that GHIL-Glue achieves a 25% improvement across several hierarchical models that leverage generative subgoals, achieving a new state-of-the-art on the CALVIN simulation benchmark for policies using observations from a single RGB camera. GHIL-Glue also outperforms other generalist robot policies across 3/4 language-conditioned manipulation tasks testing zero-shot generalization in physical experiments. READ MORE
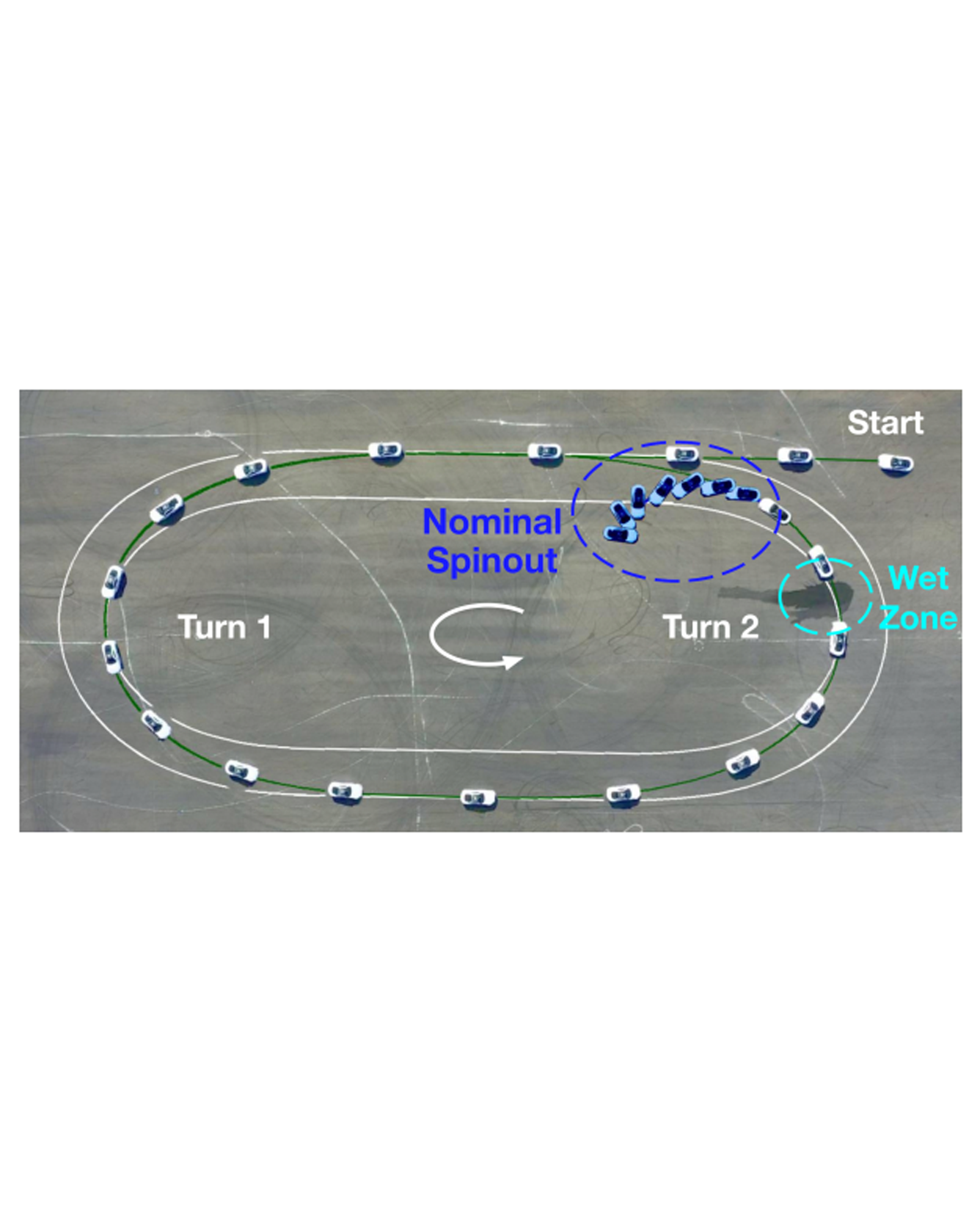
Model predictive control (MPC) algorithms can be sensitive to model mismatch when used in challenging nonlinear control tasks. In particular, the performance of MPC for vehicle control at the limits of handling suffers when the underlying model overestimates the vehicle's capabilities. In this work, we propose a risk-averse MPC framework that explicitly accounts for uncertainty over friction limits and tire parameters. Our approach leverages a sample-based approximation of an optimal control problem with a conditional value at risk (CVaR) constraint. This sample-based formulation enables planning with a set of expressive vehicle dynamics models using different tire parameters. Moreover, this formulation enables efficient numerical resolution via sequential quadratic programming and GPU parallelization. Experiments on a Lexus LC 500 show that risk-averse MPC unlocks reliable performance, while a deterministic baseline that plans using a single dynamics model may lose control of the vehicle in adverse road conditions. READ MORE
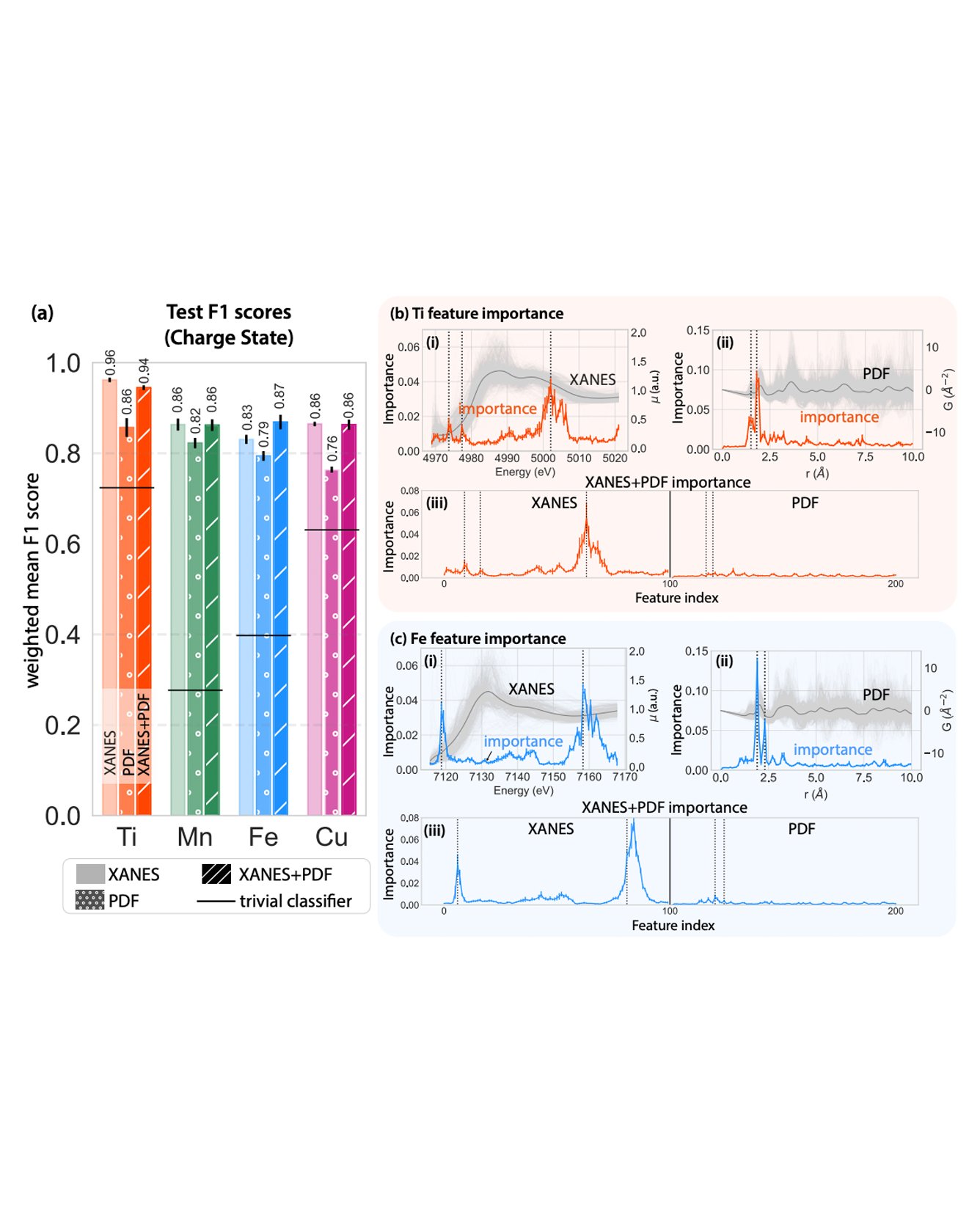
We used off-the-shelf interpretable ML techniques to combine information from multiple heterogeneous spectra: X-ray absorption near-edge spectra (XANES) and atomic pair distribution functions (PDFs), to extract information about local structure and chemistry of transition metal oxides. This approach enabled us to analyze the relative contributions of the different spectra to different prediction tasks. Specifically, we trained random forest models on XANES, PDF, and both of them combined, to extract charge (oxidation) state, coordination number, and mean nearest-neighbor bond length of transition metal cations in oxides. We find that XANES-only models tend to outperform the PDF-only models for all the tasks, and information from XANES often dominated when the two inputs were combined. This was even true for structural tasks where we might expect PDF to dominate. However, the performance gap closes when we used species-specific differential PDFs (dPDFs) as the inputs instead of total PDFs. Our results highlight that XANES contains rich structural information and may be further developed as a structural probe. Our interpretable, multimodal approach is quick and easy to implement when suitable structural and spectroscopic databases are available. This approach provides valuable insights into the relative strengths of different modalities for a practical scientific goal, guiding researchers in their experiment design tasks such as deciding when it is useful to combine complementary techniques in a scientific investigation. READ MORE
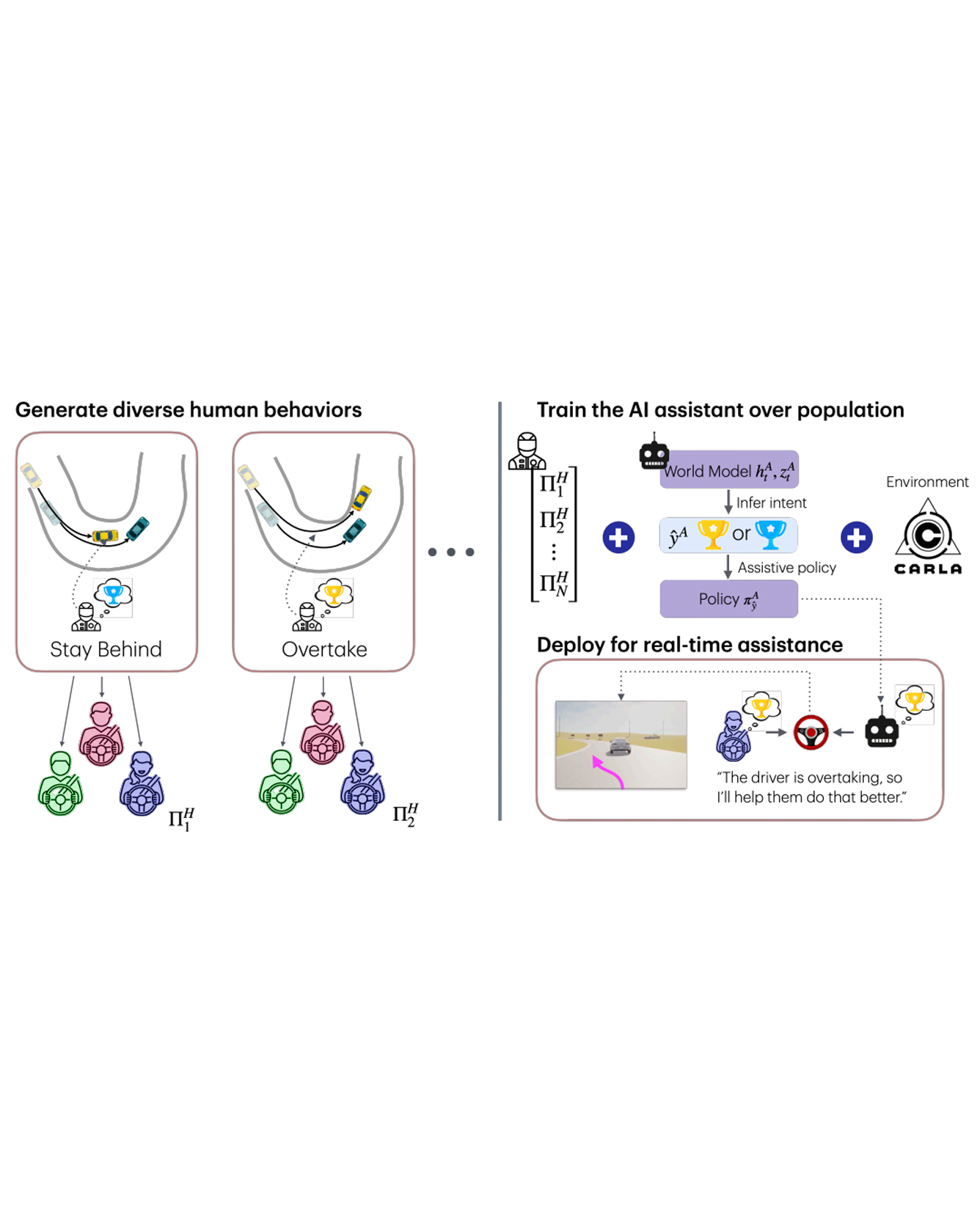
Tight coordination is required for effective human-robot teams in domains involving fast dynamics and tactical decisions, such as multi-car racing. In such settings, robot teammates must react to cues of a human teammate's tactical objective to assist in a way that is consistent with the objective (e.g., navigating left or right around an obstacle). To address this challenge, we present Dream2Assist, a framework that combines a rich world model able to infer human objectives and value functions, and an assistive agent that provides appropriate expert assistance to a given human teammate. Our approach builds on a recurrent state space model to explicitly infer human intents, enabling the assistive agent to select actions that align with the human and enabling a fluid teaming interaction. We demonstrate our approach in a high-speed racing domain with a population of synthetic human drivers pursuing mutually exclusive objectives, such as "stay-behind" and "overtake". We show that the combined human-robot team, when blending its actions with those of the human, outperforms the synthetic humans alone as well as several baseline assistance strategies, and that intent-conditioning enables adherence to human preferences during task execution, leading to improved performance while satisfying the human's objective. READ MORE
While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS's generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models. READ MORE

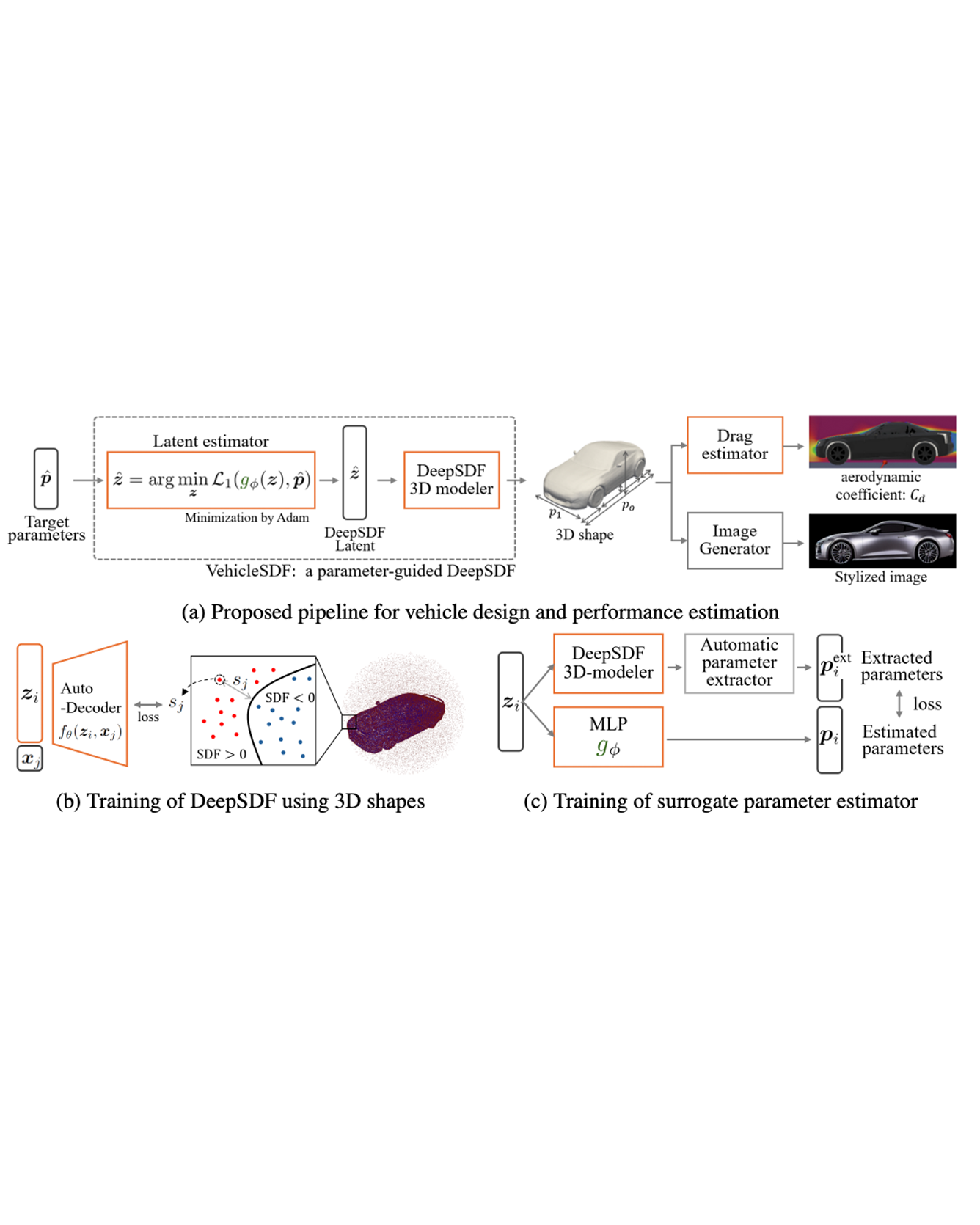
A main challenge in mechanical design is to efficiently explore the design space while satisfying engineering constraints. This work explores the use of 3D generative models to explore the design space in the context of vehicle development, while estimating and enforcing engineering constraints. Specifically, we generate diverse 3D models of cars that meet a given set of geometric specifications, while also obtaining quick estimates of performance parameters such as aerodynamic drag. For this, we employ a data-driven approach (using the ShapeNet dataset) to train VehicleSDF, a DeepSDF based model that represents potential designs in a latent space witch can be decoded into a 3D model. We then train surrogate models to estimate engineering parameters from this latent space representation, enabling us to efficiently optimize latent vectors to match specifications. Our experiments show that we can generate diverse 3D models while matching the specified geometric parameters. Finally, we demonstrate that other performance parameters such as aerodynamic drag can be estimated in a differentiable pipeline. READ MORE