Featured Publications
All Publications
TRI Authors: DeCastro, Jonathan*, Nikos Arechiga
All Authors: DeCastro, Jonathan*, Karen Yan Ming Leung, Nikos Arechiga, Marco Pavone DeCastro, Jonathan*, Karen Yan Ming Leung, Nikos Arechiga, Marco Pavone
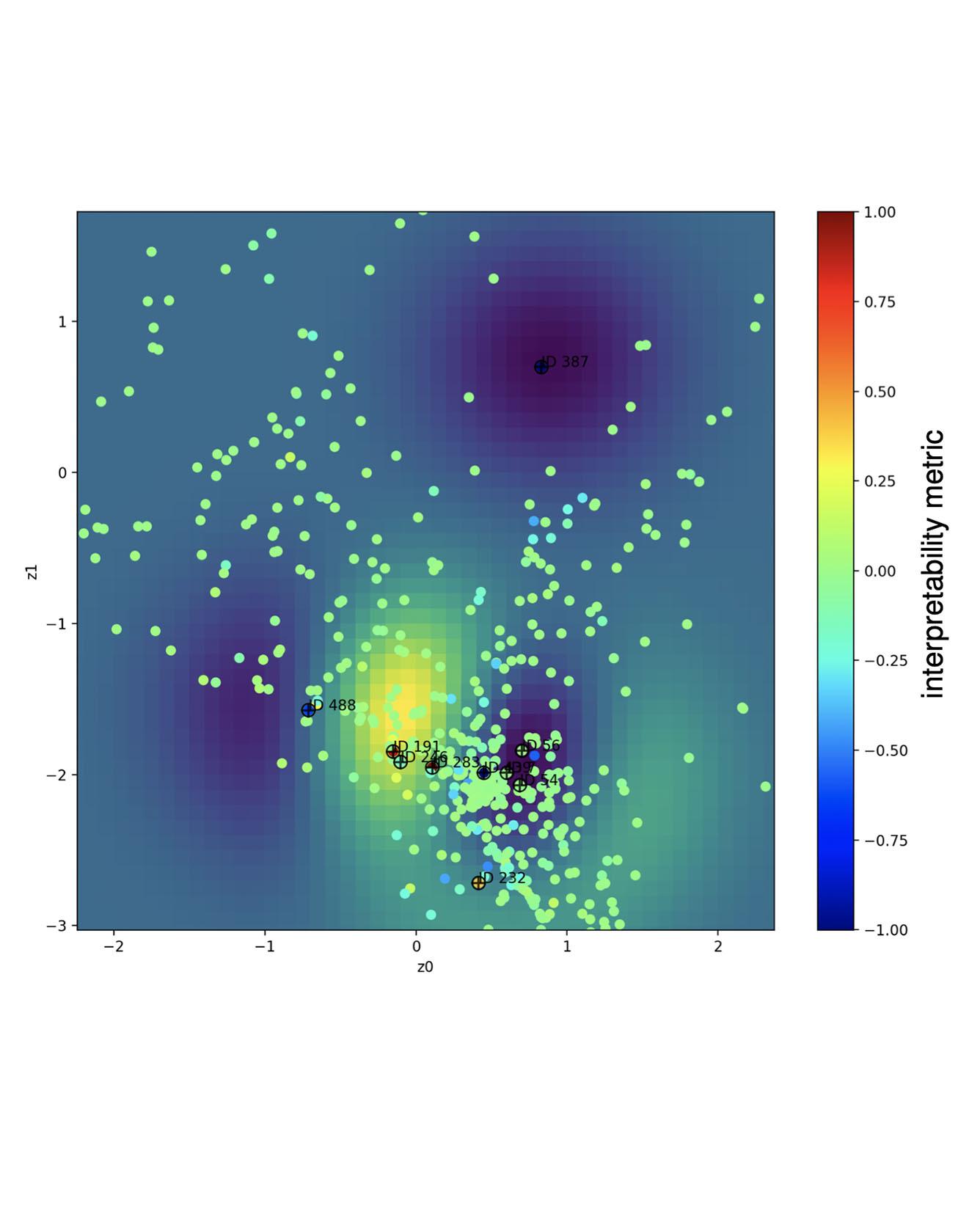
We present an approach to interpret parameterized policies through the lens of Signal Temporal Logic (STL). By providing a formally-specified description of desired behaviors we want the policy to produce, we can identify clusters in the parameter space of the policy that can produce the desired behavior. In the context of agent simulation for autonomous driving, this enables an automated way to target and produce challenging scenarios to stress-test the autonomous driving stack and hence accelerate validation and testing. Our approach leverages parametric signal temporal logic (pSTL) formulas to construct an interpretable view on the modeling parameters via a sequence of variational inference problems; one to solve for the pSTL parameters and another to construct a new parameterization satisfying the specification. We perform clustering on the new parameter space using a finite set of examples, either real or simulated, and combine computational graph learning and normalizing flows to form a relationship between these parameters and pSTL formulas either derived by hand or inferred from data. We illustrate the utility of our approach to model selection for validation of the safety properties of an autonomous driving system, using a learned generative model of the surrounding agents. Read More
Citation: DeCastro, Jonathan*, Karen Yan Ming Leung, Nikos Arechiga, Marco Pavone. "Interpretable Policies from Formally-Specified Temporal Properties." 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC).
TRI Author: Vishnu Desaraju
All Authors: Weng, Yifan, Ruikun Luo, Paramsothy Jayakumar, Mark J. Brudnak, Victor Paul, Vishnu R. Desaraju, Jeffrey L. Stein, X. Jessie Yang, Tulga Ersal
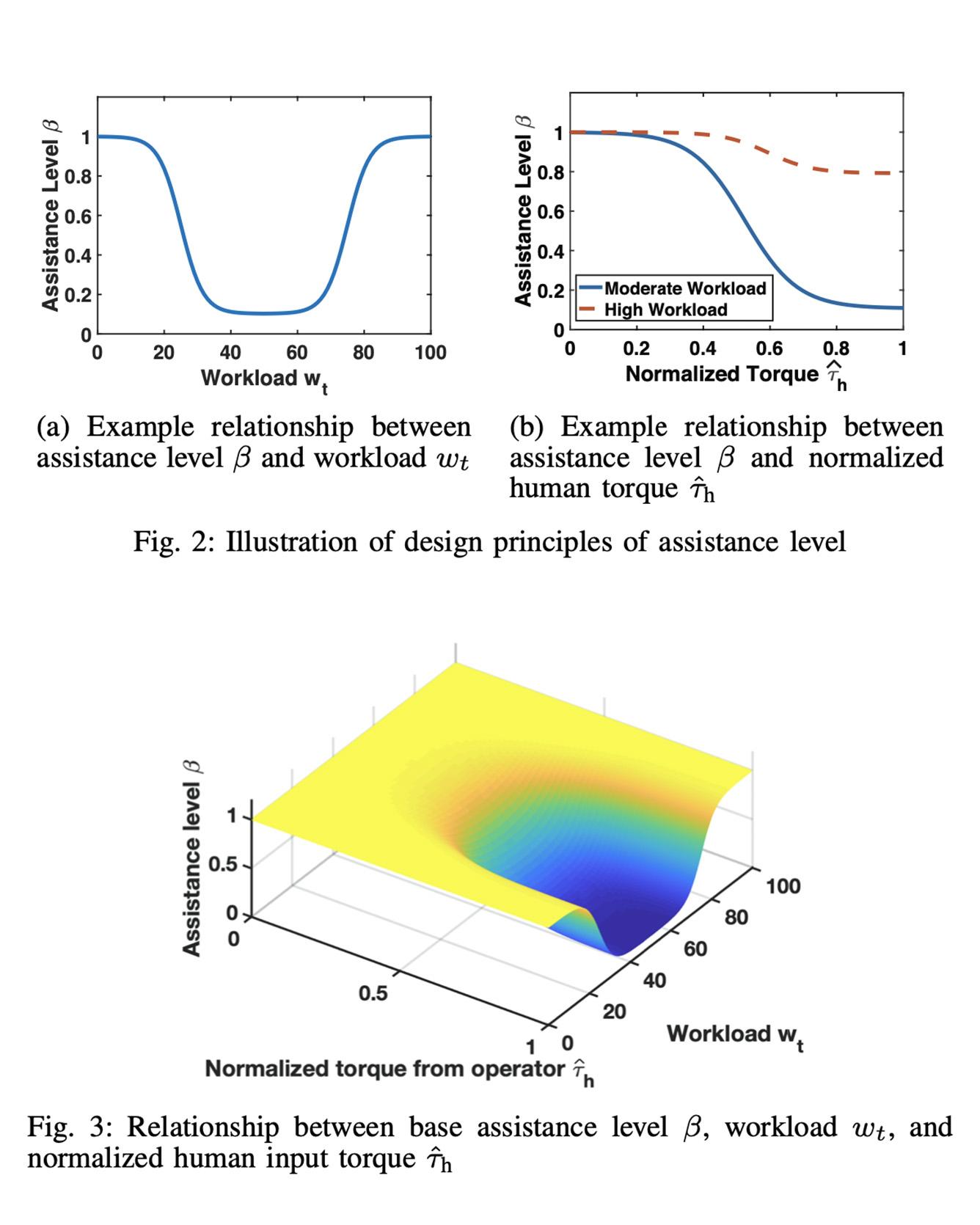
Haptic shared control of an autonomy-enabled vehicle is used to manage the control authority allocation between a human and autonomy smoothly. Existing haptic shared control schemes, however, do not take the workload condition of human into account. To fill this research gap, this study develops a novel haptic shared control scheme that adapts to a human operator's workload in a semi-autonomous driving scenario. Human-in-the-loop experiments with 8 participants are reported to evaluate the new scheme. In the experiment, a human operator and an autonomous navigation module shared the steering control of a simulated teleoperated vehicle in a path tracking task while the speed of the vehicle is controlled by autonomy. High and low screen refresh rates were used to create moderate and high workload cases, respectively. Results indicate that adaptive haptic control leads to less driver control effort without sacrificing the path tracking performance when compared with the non-adaptive case. Read More
Citation: Weng, Yifan, Ruikun Luo, Paramsothy Jayakumar, Mark J. Brudnak, Victor Paul, Vishnu R. Desaraju, Jeffrey L. Stein, X. Jessie Yang, Tulga Ersal, "Design and Evaluation of a Workload-Adaptive Haptic Shared Control Framework for Semi-Autonomous Driving," American Control Conference, Denver, CO, USA, 2020.
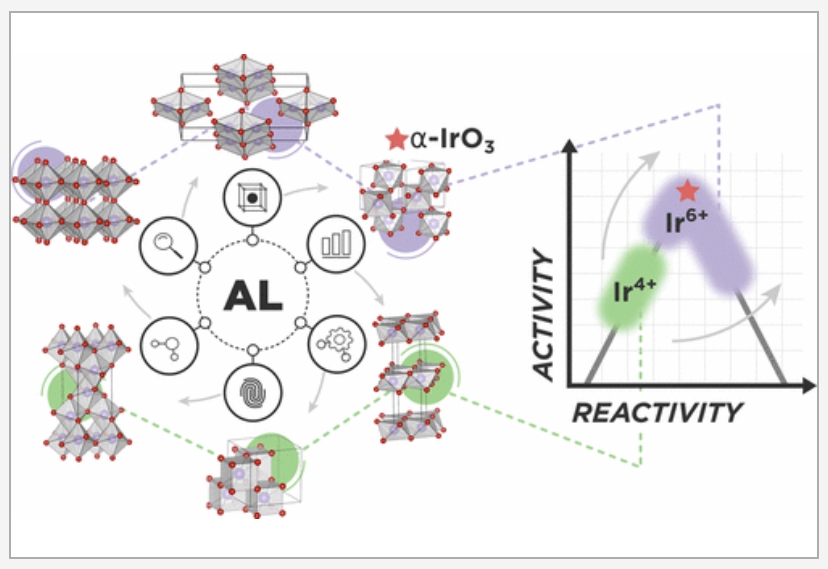
The discovery of high-performing and stable materials for sustainable energy applications is a pressing goal in catalysis and materials science. Understanding the relationship between a material’s structure and functionality is an important step in the process, such that viable polymorphs for a given chemical composition need to be identified. Machine-learning-based surrogate models have the potential to accelerate the search for polymorphs that target specific applications. Herein, we report a readily generalizable active-learning (AL) accelerated algorithm for identification of electrochemically stable iridium oxide polymorphs of IrO2 and IrO3. The search is coupled to a subsequent analysis of the electrochemical stability of the discovered structures for the acidic oxygen evolution reaction (OER). Structural candidates are generated by identifying all 956 structurally unique AB2 and AB3 prototypes in existing materials databases (more than 38000). Next, using an active learning approach, we find 196 IrO2 polymorphs within the thermodynamic amorphous synthesizability limit and reaffirm the global stability of the rutile structure. We find 75 synthesizable IrO3 polymorphs and report a previously unknown FeF3-type structure as the most stable, termed α-IrO3. To test the algorithms performance, we compare to a random search of the candidate space and report at least a 2-fold increase in the rate of discovery. Additionally, the AL approach can acquire the most stable polymorphs of IrO2 and IrO3 with fewer than 30 density functional theory optimizations. Analysis of the structural properties of the discovered polymorphs reveals that octahedral local coordination environments are preferred for nearly all low-energy structures. Subsequent Pourbaix Ir–H2O analysis shows that α-IrO3 is the globally stable solid phase under acidic OER conditions and supersedes the stability of rutile IrO2. Calculation of theoretical OER surface activities reveal ideal weaker binding of the OER intermediates on α-IrO3 than on any other considered iridium oxide. We emphasize that the proposed AL algorithm can be easily generalized to search for any binary metal oxide structure with a defined stoichiometry. READ MORE
TRI Authors: Muratahan Aykol, Patrick Herring, & Abraham Anapolsky All Authors: Muratahan Aykol, Patrick Herring, & Abraham Anapolsky
Batteries, as complex materials systems, pose unique challenges for the application of machine learning. Although a shift to data-driven, machine learning-based battery research has started, new initiatives in academia and industry are needed to fully exploit its potential. Read more
Citation: Aykol, Muratahan, Patrick Herring, Abraham Anapolsky. “Machine learning for continuous innovation in battery technologies.” Nature Reviews Materials (2020). https://doi.org/10.1038/s41578-020-0216-y
TRI Authors: KH Lee, A. Gaidon
All Authors: B. Pan, H. Cai, DA Huang, KH Lee, A. Gaidon, E. Adeli, JC Niebles
Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions. Read More
Citation: Pan, Boxiao, Haoye Cai, De-An Huang, Kuan-Hui Lee, Adrien Gaidon, Ehsan Adeli, and Juan Carlos Niebles. "Spatio-Temporal Graph for Video Captioning with Knowledge Distillation." CVPR, 2020.
TRI Authors: J. Li, A. Bhargava, A. Raventos, V. Guizilini, C. Fang, A. Gaidon
All Authors: R. Hou, J. Li, A. Bhargava, A. Raventos, V. Guizilini, C. Fang, J Lynch, A. Gaidon
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference. Read More
Citation: Hou, Rui, Jie Li, Arjun Bhargava, Allan Raventos, Vitor Guizilini, Chao Fang, Jerome Lynch, and Adrien Gaidon. "Real-Time Panoptic Segmentation from Dense Detections." CVPR 2020.

TRI Authors: W. Kehl, A. Bhargava, A. Gaidon
All Authors: S. Zakharov, W. Kehl, A. Bhargava, A. Gaidon
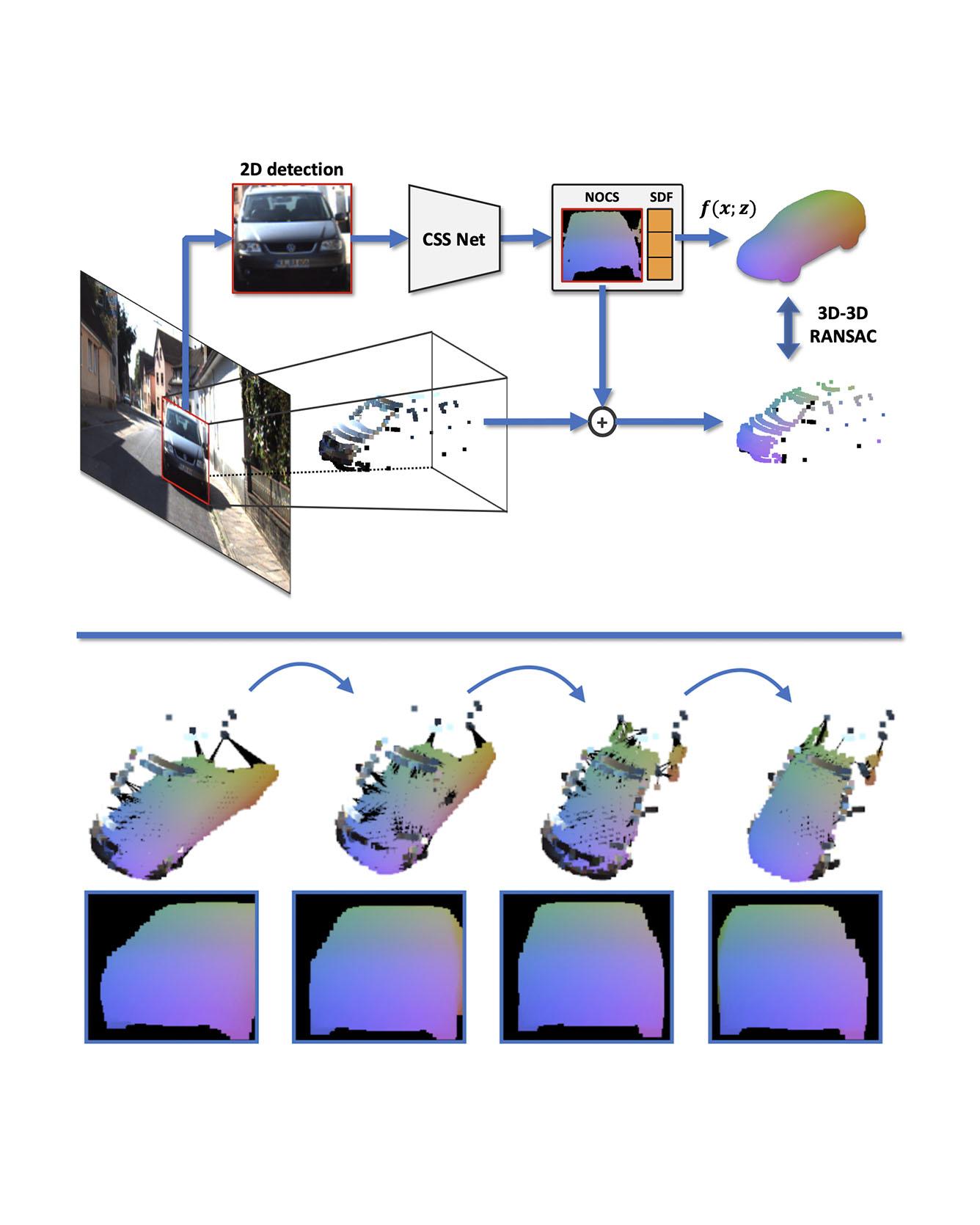
We present an automatic annotation pipeline to recover 9D cuboids and 3D shapes from pre-trained off-the-shelf 2D detectors and sparse LIDAR data. Our autolabeling method solves an ill-posed inverse problem by considering learned shape priors and optimizing geometric and physical parameters. To address this challenging problem, we apply a novel differentiable shape renderer to signed distance fields (SDF), leveraged together with normalized object coordinate spaces (NOCS). Initially trained on synthetic data to predict shape and coordinates, our method uses these predictions for projective and geometric alignment over real samples. Moreover, we also propose a curriculum learning strategy, iteratively retraining on samples of increasing difficulty in subsequent self-improving annotation rounds. Our experiments on the KITTI3D dataset show that we can recover a substantial amount of accurate cuboids, and that these autolabels can be used to train 3D vehicle detectors with state-of-the-art results. Read More
Citation: Zakharov, Sergey, Wadim Kehl, Arjun Bhargava, and Adrien Gaidon. "Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors." CVPR, 2020.
TRI Authors: V. Guizilini, R. Ambrus, S. Pillai, A. Raventos, A. Gaidon
All Authors: V. Guizilini, R. Ambrus, S. Pillai, A. Raventos, A. Gaidon
Although cameras are ubiquitous, robotic platforms typically rely on active sensors like LiDAR for direct 3D perception. In this work, we propose a novel self-supervised monocular depth estimation method combining geometry with a new deep network, PackNet, learned only from unlabeled monocular videos. Our architecture leverages novel symmetrical packing and unpacking blocks to jointly learn to compress and decompress detail-preserving representations using 3D convolutions. Although self-supervised, our method outperforms other self, semi, and fully supervised methods on the KITTI benchmark. The 3D inductive bias in PackNet enables it to scale with input resolution and number of parameters without overfitting, generalizing better on out-of-domain data such as the NuScenes dataset. Furthermore, it does not require large-scale supervised pretraining on ImageNet and can run in real-time. Finally, we release DDAD (Dense Depth for Automated Driving), a new urban driving dataset with more challenging and accurate depth evaluation, thanks to longer-range and denser ground-truth depth generated from high-density LiDARs mounted on a fleet of self-driving cars operating world-wide. Read More
Citation: Guizilini, Vitor, Rares Ambrus, Sudeep Pillai, and Adrien Gaidon. "Packnet-sfm: 3d packing for self-supervised monocular depth estimation." CVPR, 2020,

Hydrogen peroxide is a valuable chemical oxidant with a wide range of applications in a variety of industrial processes, especially in water sanitization. Electrochemical synthesis of hydrogen peroxide (H2O2) through a two-electron oxygen reduction reaction (2e-ORR) or a two-electron water oxidation reaction (2e-WOR) has emerged as an appealing process for onsite production of this chemically valuable oxidant. On-site produced H2O2 can be applied for wastewater treatment in remote locations or any applications where H2O2 is needed as an oxidizing agent. This Review studies the theoretical efforts in understanding the challenges in catalysis for electrochemical synthesis of H2O2 as well as providing design principles for more efficient catalyst materials. READ MORE
TRI Authors: KH Lee,A. Gaidon
All Authors: B. Liu, E. Adeli, Z. Cao, KH Lee, A. Shenoi, A. Gaidon, JC Niebles
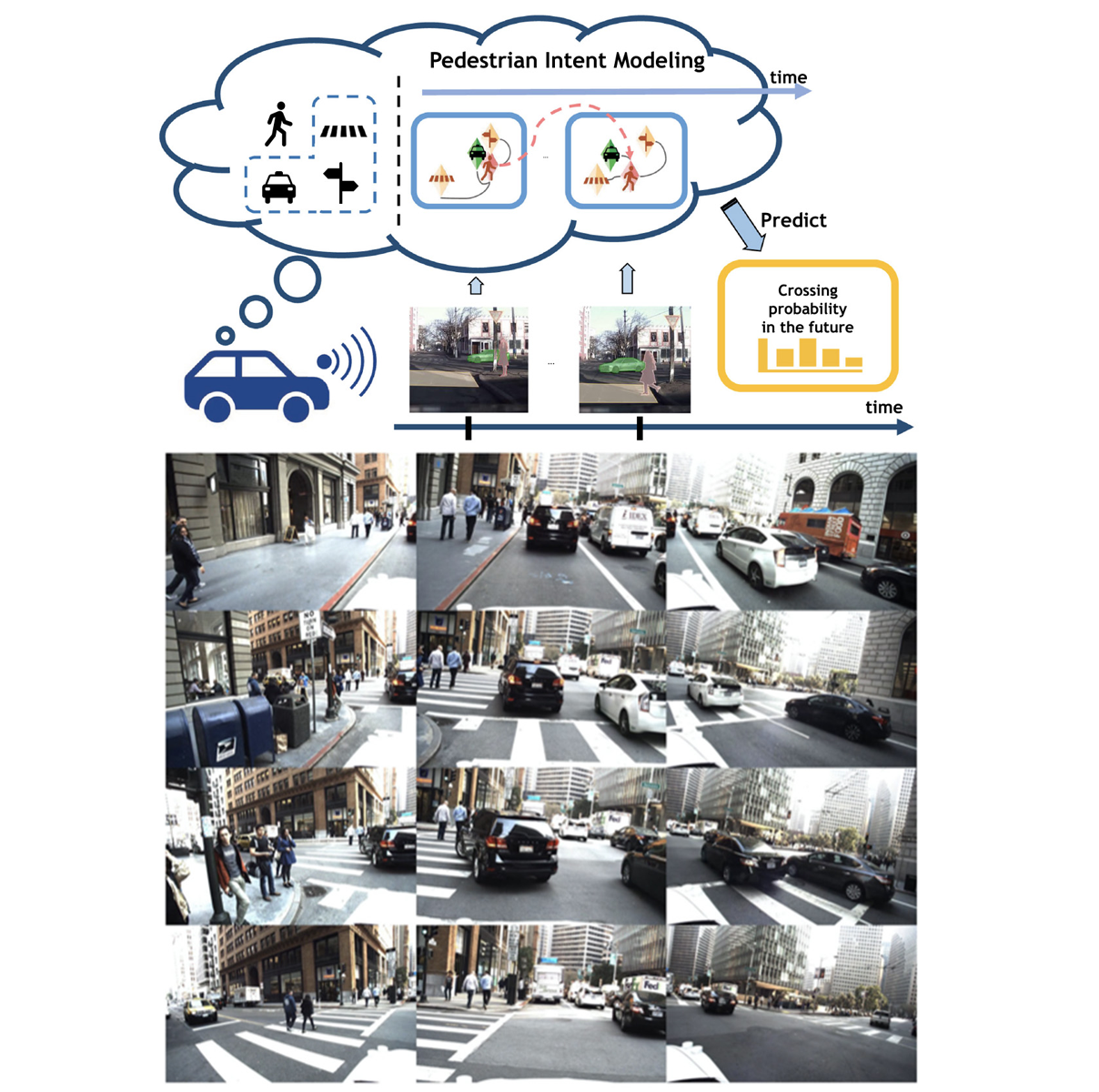
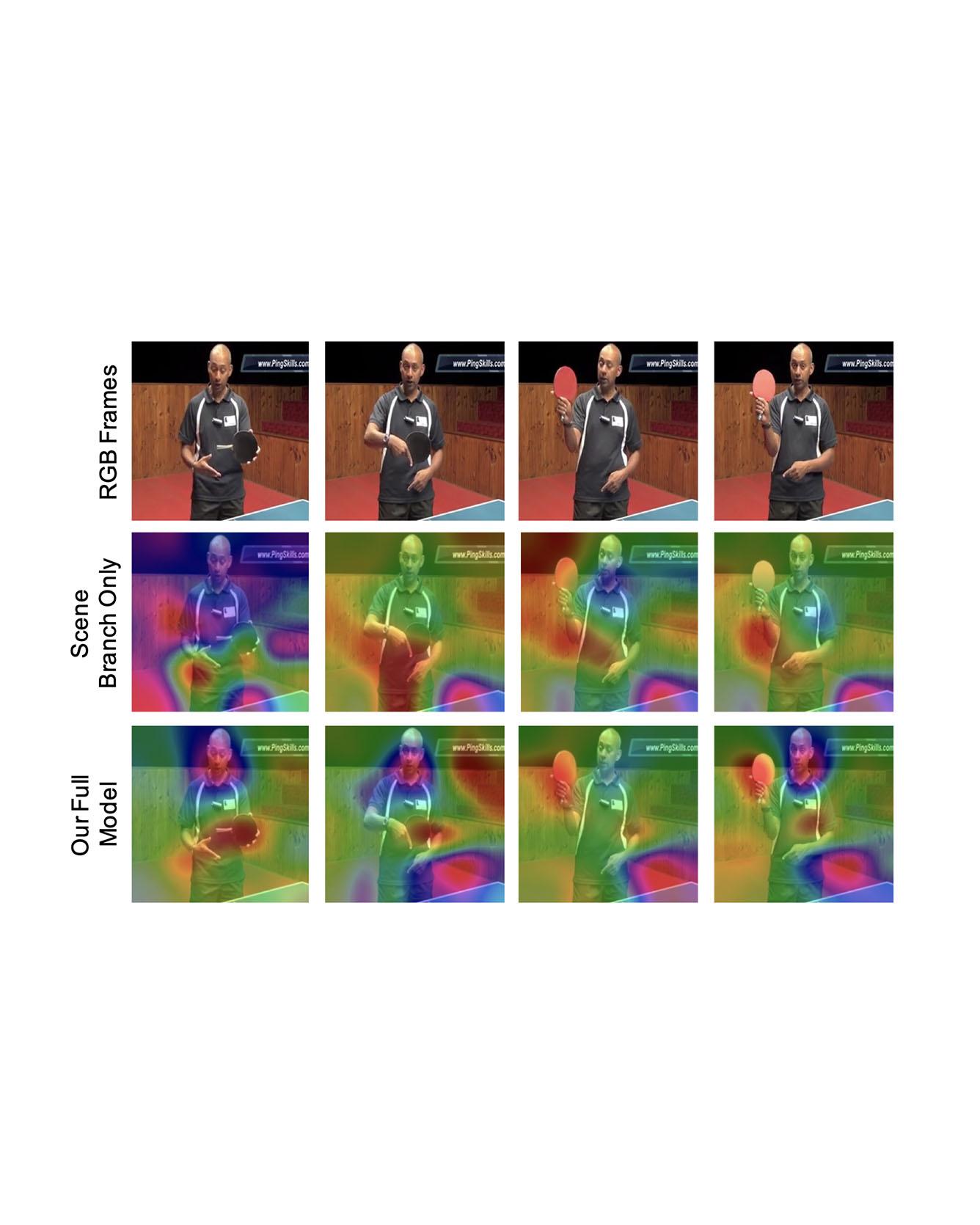
Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this letter, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomous-driving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform baseline and previous work. Read More
Citation: Liu, Bingbin, Ehsan Adeli, Zhangjie Cao, Kuan-Hui Lee, Abhijeet Shenoi, Adrien Gaidon, and Juan Carlos Niebles. "Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction." IEEE Robotics and Automation Letters 5, no. 2 (2020): 3485-3492.