Featured Publications
All Publications
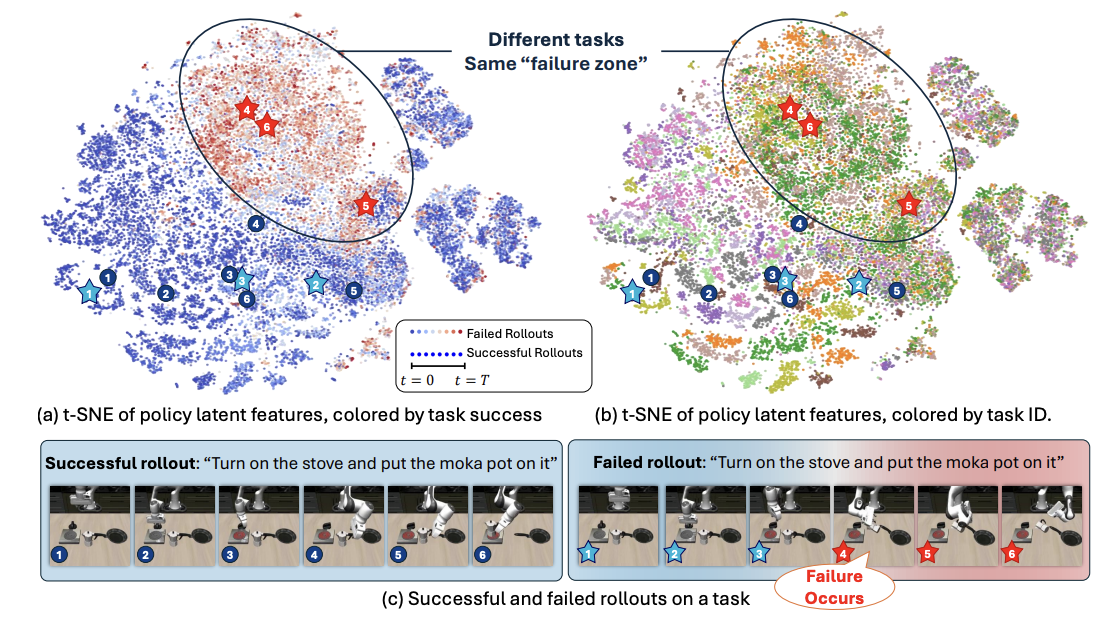
While vision-language-action models (VLAs) have shown promising robotic behaviors across a diverse set of manipulation tasks, they achieve limited success rates when deployed on novel tasks out of the box. To allow these policies to safely interact with their environments, we need a failure detector that gives a timely alert such that the robot can stop, backtrack, or ask for help. However, existing failure detectors are trained and tested only on one or a few specific tasks, while generalist VLAs require the detector to generalize and detect failures also in unseen tasks and novel environments. In this paper, we introduce the multitask failure detection problem and propose SAFE, a failure detector for generalist robot policies such as VLAs. We analyze the VLA feature space and find that VLAs have sufficient highlevel knowledge about task success and failure, which is generic across different tasks. Based on this insight, we design SAFE to learn from VLA internal features and predict a single scalar indicating the likelihood of task failure. SAFE is trained on both successful and failed rollouts, and is evaluated on unseen tasks. SAFE is compatible with different policy architectures. We test it on OpenVLA, π0, and π0-FAST in both simulated and real-world environments extensively. We compare SAFE with diverse baselines and show that SAFE achieves state-of-the-art failure detection performance and a favorable trade-off between accuracy and detection time using conformal prediction. More qualitative results and code can be found at the project webpage: https://vla-safe.github.io/.
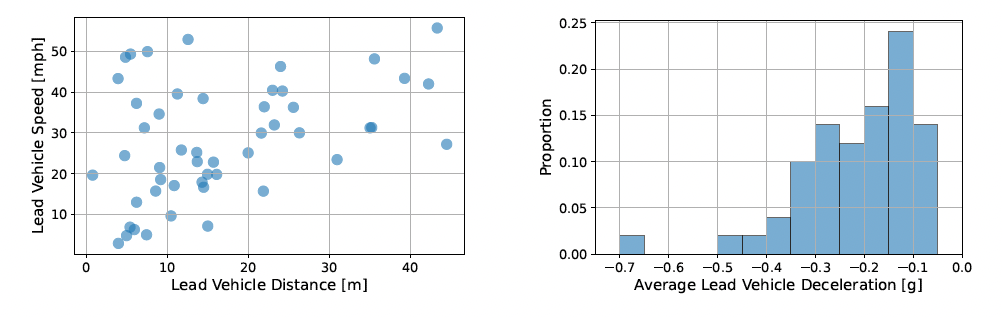
Scenarios provide a fundamental link between driving simulators and real-world conditions, shaping the extent to which the findings of a user study can be applied to public roads. However, compared to other aspects of study design, scenario development in human–vehicle interaction research tends to receive less deliberate attention. To encourage more methodical scenario generation, this work introduces a mixed methods approach for extracting representative scenarios from an integration of three real-world data sources: aggregated crash statistics, interviews with experienced drivers, and naturalistic driving data. Through a case study on winter driving, we outline the derivation of a nighttime, two-lane road scenario from these data sources and conduct an initial driving simulator pilot study to assess its realism. We hope that this demonstration of scenario generation from quantitative and qualitative data inspires researchers to consider more rigorous methods for scenario design in future work.
Learning in domains involving complex motor skills, such as performance driving, often requires feedback that is timely, personalized, and actionable. Yet many drivers rely on video and telemetry data to review their performance without guidance. We explore how conversational AI can support post-drive reflection by integrating LLM-generated coaching into an interactive review interface. In an exploratory within-subjects simulator study (n=16), participants completed laps under two conditions: one with video and data visualizations alone, and another with the same tools augmented with a conversational interface that provided verbal feedback after each lap. Conversational feedback supported short-term improvements in lap time, average speed, and steering control, and was rated as more useful and satisfying—though it also elicited slightly higher nervousness. These results suggest that conversational AI can make post-drive feedback more interpretable and actionable, particularly for drivers reviewing performance data in high-skill contexts like performance driving.

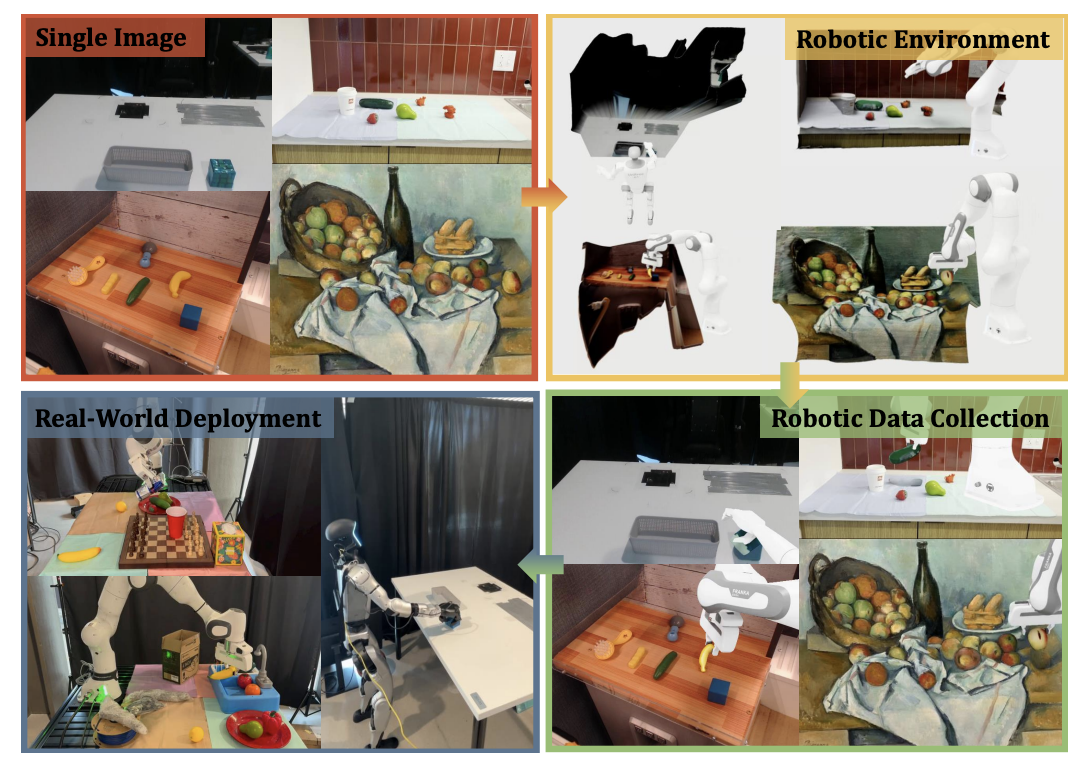
We introduce RoLA, a framework that transforms any in-the-wild image into an interactive, physics-enabled robotic environment. Unlike previous methods, RoLA operates directly on a single image without requiring additional hardware or digital assets. Our framework democratizes robotic data generation by producing massive visuomotor robotic demonstrations within minutes from a wide range of image sources, including camera captures, robotic datasets, and Internet images. At its core, our approach combines a novel method for single-view physical scene recovery with an efficient visual blending strategy for photorealistic data collection. We demonstrate RoLA's versatility across applications like scalable robotic data generation and augmentation, robot learning from Internet images, and single-image real-to-sim-to-real systems for manipulators and humanoids. Video results are available at this https URL.
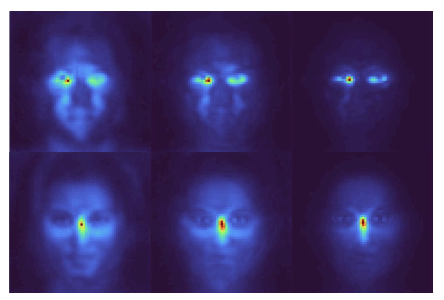
Recent work has shown that the generalization ability of image diffusion models arises from the locality properties of the trained neural network. In particular, when denoising a particular pixel, the model relies on a limited neighborhood of the input image around that pixel, which, according to the previous work, is tightly related to the ability of these models to produce novel images. Since locality is central to generalization, it is crucial to understand why diffusion models learn local behavior in the first place, as well as the factors that govern the properties of locality patterns. In this work, we present evidence that the locality in deep diffusion models emerges as a statistical property of the image dataset and is not due to the inductive bias of convolutional neural networks, as suggested in previous work. Specifically, we demonstrate that an optimal parametric linear denoiser exhibits similar locality properties to deep neural denoisers. We show, both theoretically and experimentally, that this locality arises directly from pixel correlations present in the image datasets. Moreover, locality patterns are drastically different on specialized datasets, approximating principal components of the data's covariance. We use these insights to craft an analytical denoiser that better matches scores predicted by a deep diffusion model than prior expert-crafted alternatives. Our key takeaway is that while neural network architectures influence generation quality, their primary role is to capture locality patterns inherent in the data.
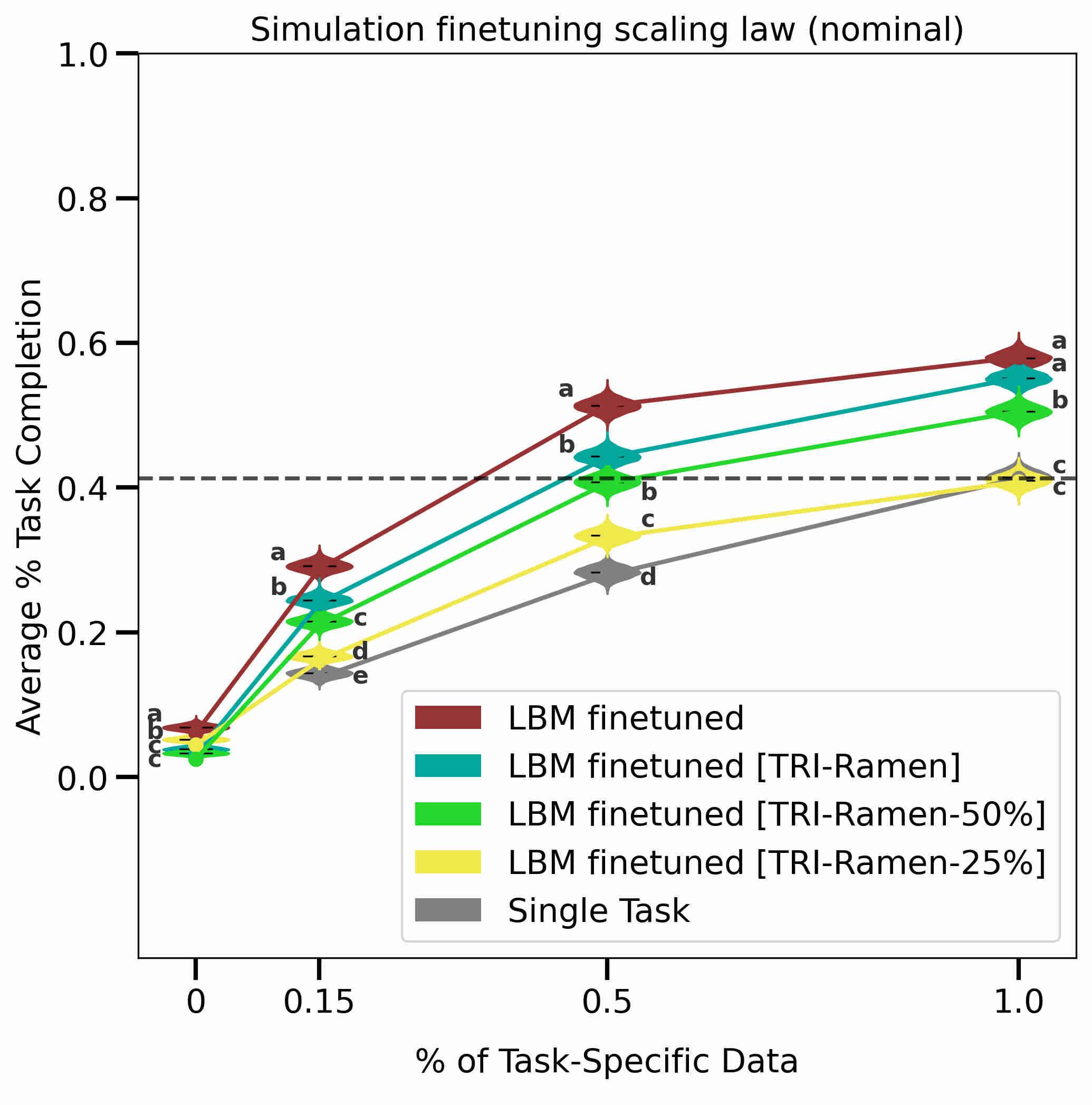
Robot manipulation has seen tremendous progress in recent years, with imitation learning policies enabling successful performance of dexterous and hard-to-model tasks. Concurrently, scaling data and model size has led to the development of capable language and vision foundation models, motivating large-scale efforts to create general-purpose robot foundation models. While these models have garnered significant enthusiasm and investment, meaningful evaluation of real-world performance remains a challenge, limiting both the pace of development and inhibiting a nuanced understanding of current capabilities. In this paper, we rigorously evaluate multitask robot manipulation policies, referred to as Large Behavior Models (LBMs), by extending the Diffusion Policy paradigm across a corpus of simulated and real-world robot data. We propose and validate an evaluation pipeline to rigorously analyze the capabilities of these models with statistical confidence. We compare against single-task baselines through blind, randomized trials in a controlled setting, using both simulation and real-world experiments. We find that multi-task pretraining makes the policies more successful and robust, and enables teaching complex new tasks more quickly, using a fraction of the data when compared to single-task baselines. Moreover, performance predictably increases as pretraining scale and diversity grows.
Abstract: In this work, we leverage GPUs to construct probabilistically collision-free convex sets in robot configuration space on the fly. This extends the use of modern motion planning algorithms that leverage such representations to changing environments. These planners rapidly and reliably optimize high-quality trajectories, without the burden of challenging nonconvex collision-avoidance constraints. We present an algorithm that inflates collision-free piecewise linear paths into sequences of convex sets (SCS) that are probabilistically collision-free using massive parallelism. We then integrate this algorithm into a motion planning pipeline, which leverages dynamic roadmaps to rapidly find one or multiple collision-free paths, and inflates them. We then optimize the trajectory through the probabilistically collision-free sets, simultaneously using the candidate trajectory to detect and remove collisions from the sets. We demonstrate the efficacy of our approach on a simulation benchmark and a KUKA iiwa 7 robot manipulator with perception in the loop. On our benchmark, our approach runs 17.1 times faster and yields a 27.9% increase in reliability over the nonlinear trajectory optimization baseline, while still producing high-quality motion plans. Website: https://sites.google.com/view/GPUPolytopes

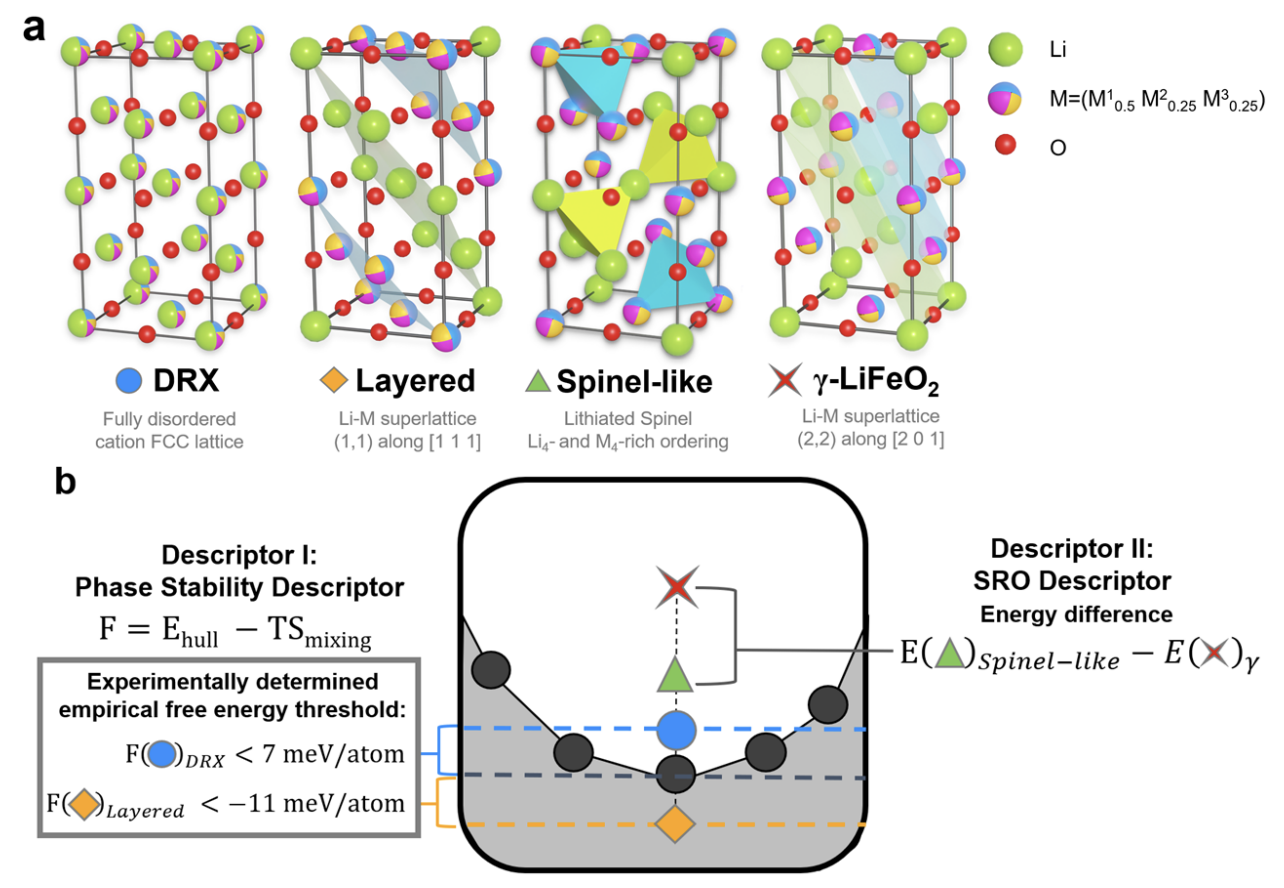
Newly designed Li-ion battery cathode materials with high capacity and greater flexibility in chemical composition will be critical for the growing electric vehicles market. Cathode structures with cation disorder were once considered suboptimal, but recent demonstrations have highlighted their potential in Li1+xM1−xO2 chemistries with a wide range of metal combinations M. By relaxing the strict requirements of maintaining ordered Li diffusion pathways, countless multi-metal compositions in LiMO2 may become viable, aiding the quest for high-capacity cobalt-free cathodes. A challenge presented by this freedom in composition space is designing compositions which possess specific, tailored types of both long- and short-range orderings, which can ensure both phase stability and Li diffusion. However, the combinatorial complexity associated with local cation environments impedes the development of general design guidelines for favorable orderings. Here we propose ordering design frameworks from computational ordering descriptors, which in tandem with low-cost heuristics and elemental statistics can be used to simultaneously achieve compositions that possess favorable phase stability as well as configurations amenable to Li diffusion. Utilizing this computational framework, validated through multiple successful synthesis and characterization experiments, we not only demonstrate the design of LiCr0.75Fe0.25O2, showcasing initial charge capacity of 234 mAhg−1 and 320 mAhg−1 in its 20% Li-excess variant Li1.2Cr0.6Fe0.2O2, but also present the elemental ordering statistics for 32 elements, informed by one of the most extensive first-principles studies of ordering tendencies known to us.
Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. We propose a novel approach for policy mobilization that bridges navigation and manipulation by optimizing the robot's base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. To understand policy mobilization in more depth, we also introduce the Mobi-π framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, and (3) visualization tools for analysis. In both our developed simulation task suite and the real world, we show that our approach outperforms baselines, demonstrating its effectiveness for policy mobilization.

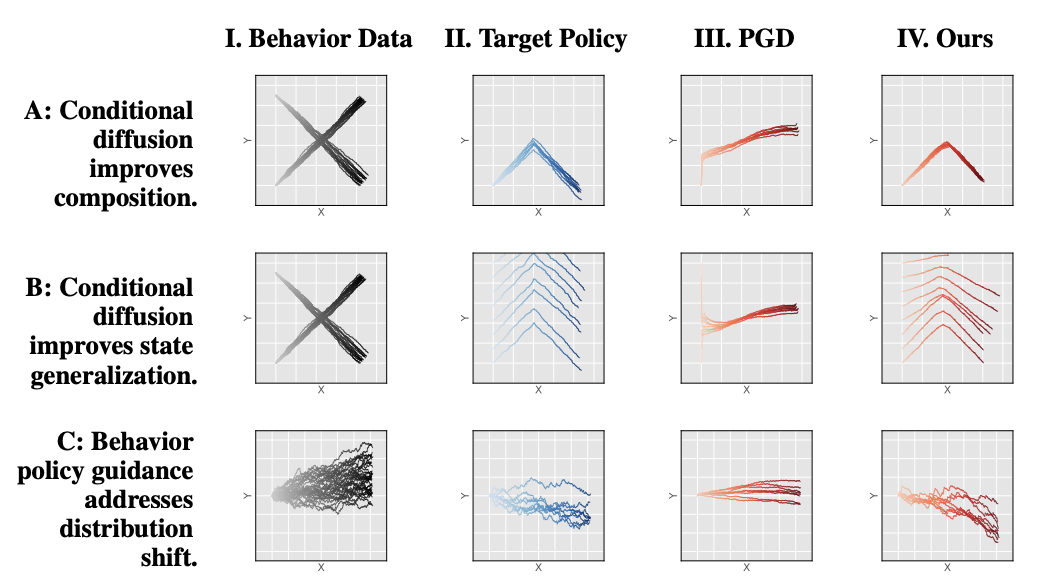
Off-policy evaluation (OPE) estimates the performance of a target policy using offline data collected from a behavior policy, and is crucial in domains such as robotics or healthcare where direct interaction with the environment is costly or unsafe. Existing OPE methods are ineffective for high-dimensional, long-horizon problems, due to exponential blow-ups in variance from importance weighting or compounding errors from learned dynamics models. To address these challenges, we propose STITCH-OPE, a model-based generative framework that leverages denoising diffusion for long-horizon OPE in high-dimensional state and action spaces. Starting with a diffusion model pre-trained on the behavior data, STITCH-OPE generates synthetic trajectories from the target policy by guiding the denoising process using the score function of the target policy. STITCH-OPE proposes two technical innovations that make it advantageous for OPE: (1) prevents over-regularization by subtracting the score of the behavior policy during guidance, and (2) generates long-horizon trajectories by stitching partial trajectories together end-to-end. We provide a theoretical guarantee that under mild assumptions, these modifications result in an exponential reduction in variance versus long-horizon trajectory diffusion. Experiments on the D4RL and OpenAI Gym benchmarks show substantial improvement in mean squared error, correlation, and regret metrics compared to state-of-the-art OPE methods.